
Auto scaling이란?
클라우드 컴퓨팅의 대표적인 장점으로는 필요에 따라 서비스를 빠르게 확장하거나 축소할 수 있는 유연성을 들 수 있는데, 오토스케일링(Auto Scaling)은 클라우드의 유연성을 돋보이게 하는 핵심기술로 CPU, 메모리, 디스크, 네트워크 트래픽과 같은 시스템 자원들의 메트릭(Metric) 값을 모니터링하여 서버 사이즈를 자동으로 조절 하는 서비스를 말합니다.
이를 통해 사용자는 예상치 못한 서비스 부하에 효과적으로 대응하고, 최대한 저렴한 비용으로 안정적이고 예측 가능한 성능을 유지 할 수 있습니다.
Auto scaling의 목표
- 정확한 수의 EC2 인스턴스를 보유하도록 보장
- 그룹의 최소 인스턴스 숫자와 최대 인스턴스 숫자를 관리
- 만약 애플리케이션을 실행하기 위해 인스턴스가 3개가 필요하다면, 3대이상의 인스턴스가 항상 떠있을 수 있게 보장한다.
- 최소 숫자 이하로 내려가지 않도록 인스턴스 숫자를 유지 (인스턴스 추가)
- 최대 숫자 이상 늘어자니 않도록 인스턴스 숫자 유지 (인스턴스 삭제)-
다양한 스케일링 정책 적용 가능
- CPU의 부하에 따라 인스턴스 크기 늘리기/줄이기 (오후 2시가 되면 게임 접속 트래픽이 많으니 인스턴스 확 올리고, 새벽 2시가 되면 접속 트래픽이 낮으니 인스턴스를 내린다.) - Auto scaling policies는 CPU, Network, 그리고 커스텀 metric, 또는 스케줄을 기반으로 하는 것 역시 가능하다. -
가용영역에 인스턴스가 골고루 분산될 수 있도록 인스턴스를 분배
- 서비스 장애가 발생하더라도 문제없이 서비스 이용
오토 스케일링 구성요소
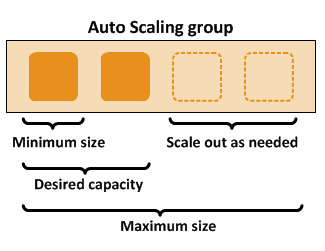
-
EC2 인스턴스를 조정 및 관리 목적의 논리 단위로 취급될 수 있도록 그룹으로 구성
-
그룹을 생성할 때 EC2 인스턴스의 최소(minimum size) 및 최대(maximum size) 인스턴스 수와 원하는(desired capacity) 인스턴스 수를 지정하고 이 범위안에서 Scale in/out 이 일어난다.
-
인스턴스 증감은 이 그룹안에서 이루어 지게 되며, 사용자가 지정한 조건을 통해 실행된다.
- 증설 시 어떤 인스턴스 템플릿을 이용할 것인지
- 얼마나 많은 서버를 필요로 하는지
- 어떤 값을 기반으로 모니터링해서, 인스턴스를 증설 또는 감축 할 것인지
-
추가적으로 증설된 인스턴스가 로드밸런서의 멤버로 연결되어야 한다면, 로드밸런서를 지정할 수도 있다.
-
네트워크 + 서브넷 정보
-
로드 밸런서 정보
스케일링 정책(Scaling Policies)
Dynamic Scaling Policies
Target Tracking Scaling
- 가장 간단하고 쉬운 방법입니다.
- 예를 들어, ASG의 평균 CPU가 40% 언저리에 있도록 설정할 수 있습니다.
Simple / Step Scaling
-
CloudWatch 알람을 생성할 때는 한 번에 추가하거나 제거할 인스턴스의 수를 단계적으로 설정해야 합니다.
-
예를 들면,
CPU > 70% 일 때 CloudWatch 알람을 트리거 -> 2개 추가
CPU < 30% 일 때 CloudWatch 알람을 트리거 -> 1개 삭제
Scheduled Actions
- 사용 패턴을 기준으로 scaling 여부를 예측할 수 있습니다.
- 예를 들어, 금요일 5시마다 최소 용량을 10으로 올리라고 설정할 수 있습니다.
Predictive Scaling
Predictive scaling이란 지속적으로 부하를 예측하고 이를 통해 다음 스케일링을 예측합니다.
스케일링의 기반이 되는 좋은 지표(metrics)
- CPU Utilization
- 여러 인스턴스들에 대한 평균 CPU 사용량
RequestCountPerTarget - 인스턴스 당 갖는 요청의 수가 안정성을 유지하도록 하기 위해 측정하는 지표입니다.
Scaling Cooldowns
스케일링이 발생한 다음, cooldown period가 생깁니다.
- 즉, 5분 혹은 300초의 휴지 기간을 갖는 것 입니다(기본이 300초).
cooldown 주기 동안에는 ASG는 새로운 인스턴스를 시작하거나 종료할 수 없다(새로 만들어진 인스턴스에 대한 지표가 안정되도록 하기 위함입니다).
이 기능을 사용하지 않을 수도 있습니다.

즉시 사용이 가능한 AMI를 구성해 EC2 인스턴스 구성 시간을 단축하고 이를 통해 요청을 좀 더 빠르게 처리하는 것이 좋습니다.
- 왜냐하면, 인스턴스 구성에 할애되는 시간이 적으면 즉시 적용이 가능하게 되고, 활성화 시간이 빨라지면 휴지 기간 역시 단축 되어 ASG 상에서 더 많은 동적 스케일링이 가능해집니다.

Tips
오토 스케일링 그룹을 생성 한뒤 스트레스 테스트를 원하면,
인스턴스가 linux2인경우 install stress Amazon Linux2를 입력해서 다운받거나
$sudo amazon-linux-extras install epel -y
$sudo yum install stress -y
$ stress -c [cpu개수] #cpu의 사용률을 높이는 명령을 통해 설치하고
인스턴스가 ubuntu인 경우 이전과 같이 ab테스트로 스트레스 테스트가 가능합니다.
출처: https://docs.aws.amazon.com/ko_kr/emr/latest/ManagementGuide/emr-automatic-scaling.html
https://inpa.tistory.com/entry/AWS-%F0%9F%93%9A-EC2-%EC%98%A4%ED%86%A0-%EC%8A%A4%EC%BC%80%EC%9D%BC%EB%A7%81-ELB-%EB%A1%9C%EB%93%9C-%EB%B0%B8%EB%9F%B0%EC%84%9C-%EA%B0%9C%EB%85%90-%EA%B5%AC%EC%B6%95-%EC%84%B8%ED%8C%85-%F0%9F%92%AF-%EC%A0%95%EB%A6%AC
https://opentutorials.org/course/2717/11336
