
AWS에는 여러 관리형 데이터베이스가 있습니다. 무엇을 선택할지는 문제가 어떤 아키텍처를 요구하는지에 따라 천차만별로 달라집니다.
- 읽기 중심, 쓰기 중심 또는 균형 잡힌 워크로드입니까?
- 처리량이 필요합니까?
- 하루 동안 규모를 조정하거나 변동해야 합니까?
- 저장할 데이터의 양과 기간은? 성장할까요? 평균 개체 크기? 어떻게 액세스합니까?
- 데이터 내구성? 데이터에 대한 진실의 출처?
- 대기 시간 요구 사항? 동시 사용자?
- 데이터 모델? 데이터를 어떻게 쿼리할 것인가? 조인? 구조화? 반구조화?
- 강력한 스키마? 더 많은 유연성? 보고? 찾다? RDBMS/NoSQL?
- 라이센스 비용? Aurora와 같은 Cloud Native DB로 전환하시겠습니까?
RDS
RDS
PostgreSQL,MySQL,Oracle,SQL Server에 의해 관리됩니다.- EC2 인스턴스와 EBS 볼륨 프로비저닝이 필요합니다.
- 스토리지를 위한 Auto-scaling 기능 지원
- 읽기 전용 복제본과 다중 AZ 지원
IAM,보안 그룹,KMS,전송중 암호화 SSL로 보안을 지원- 자동
백업이나스냅샷,지정 시간 복구를 지원 (35일) - 장기 보존 백업이 필요한 경우에는 수동 DB 스냅샷을 사용하면 됩니다.
- 유지 관리 작업 처리와 예약이 가능기 때문에 데이터베이스
다운타임이 발생할 수 있습니다. RDS 프록시를 강제하여 RDS에IAM 인증을 추가하는 기능이 있습니다.Secrets Manager와 통합하여 DB자격 증명을 관리할 수 있습니다.- 기본 인스턴스에 액세스하고 사용자 지정하려면 RDS사용자 지정 옵션을 사용할 수 있습니다.
- CloudWatch가 모니터링을 수행합니다.
- 사용 사례:
- Amazon RDS는 관계형 데이터베이스를 저장하는 데 활용됩니다. (RDBMS)
- RDBMS와 온라인 트랜잭션 처리 데이터베이스(OLTP)가 포함
- SQL 쿼리를 실행할 수도 있고 트랜잭션에도 활용
- 사용 사례:
Aurora
Aurora
- PostgreSQL 및 MySQL과 호환하는 API를 갖춘 데이터베이스
- 데이터는
3 AZ에 걸쳐6개에 복제됩니다.- 고 가용성, 자가 복구, 오토스케일링
- 컴퓨팅: 여러 AZ에 걸쳐 DB 인스턴스의 클러스터, 읽기 복제본의 자동 확장
- 클러스터: writer 및 reader DB 인스턴스에 대한 사용자 지정 endpoint
- RDS와 동일한 보안/모니터링/유지보수 기능
- Aurora의 백업 및 복원 옵션 파악
- AuroraServerless – 예측할 수 없거나 간헐적인 워크로드, 용량 계획 없음
- Aurora Multi-Master – 지속적인 쓰기 장애 조치용(높은 쓰기 가용성)
- Aurora 글로벌: 각 지역에서 최대 16개의 DB 읽기 인스턴스, < 1초 스토리지 복제
- Aurora 머신 러닝: Aurora에서 SageMaker 및 Comprehend를 사용하여 ML 수행
- Aurora 데이터베이스 복제: 기존 클러스터에서 새 클러스터를 스냅샷으로 복원하는 것보다 빠름
- 사용 사례: RDS와 동일하지만 유지 관리가 적고 유연성이 높으며 성능이 높으며 기능이 더 많습니다.
ElastiCache
- 관리형
Redis/Memcached(RDS와 유사하지만 캐시용) - 인메모리 데이터 저장소, 1밀리초 미만의 대기 시간
- EC2 인스턴스 유형을 프로비저닝해야 함
- 클러스터링(Redis) 및 다중 AZ, 읽기 전용 복제본(샤딩) 지원
- IAM, Security Groups, KMS, Redis Auth를 통한 보안
- 백업/스냅샷/시점 복원 기능
- 관리되고 예정된 유지 보수
- RDS가 결합된 데이터베이스에서 캐싱 작업을 수행하려면 애플리케이션 코드가 ElastiCache를 활용하도록 코드를 수정해 줘야 합니다.
- 코드 변경이 필요한 캐싱 솔루션입니다.
- 사용 사례: 키/값 저장, 빈번한 읽기, 적은 쓰기, DB 쿼리에 대한 캐시 결과, 웹사이트에 대한 세션 데이터 저장, SQL 사용 불가.
DynamoDB
- AWS 독점 기술, 관리형 서버리스 NoSQL 데이터베이스, 밀리초 대기 시간
- 용량 모드:
프로비저닝된 용량 모드: 선택형 오토 스케일링이 탑재되어있고, 점진적으로 늘어나거나 점진적으로 줄어드는 이중(double) 워크로드가 있을 때 유용합니다.온디맨드 용량 모드: 용량을 프로비저닝하지 않아도 됩니다. 하지만 오토 스케일링이 실행되므로 워크로드를 예측하기 어려울 때나 데이터베이스의 수요가 급증할 때 유용합니다.
- ElastiCache 대신 키/값 저장소로 대체할 수 있습니다(예: TTL 기능을 사용하여 세션 데이터 저장).
- 고가용성, 기본적으로 다중 AZ, 읽기 및 쓰기가 분리됨, 트랜잭션 기능
- 읽기 캐시용 DAX 클러스터, 마이크로초 읽기 지연 시간
- 보안, 인증 및 승인은 IAM을 통해 이루어집니다.
- 이벤트 처리: DynamoDB에는 이벤트 처리 용량이 있어DynamoDB Streams로 데이터베이스의 모든 변경 사항을 스트리밍할 수 있습니다.
- AWS Lambda 또는 Kinesis Data Streams(보유 기간 1년)와 통합 가능
- GlobalTable 기능: 여러 리전 간에 다중 활성(active-active) 복제
- PITR(백업 보유기간을 길게하려면 새 테이블로 복원) 또는 온디맨드 백업을 통해 최대 35일까지 자동 백업
- PITR 창 내에서 RCU를 사용하지 않고 S3로 내보내기 (35일), WCU를 사용하지 않고 S3에서 가져오기
- 빠르게 진화하는 스키마에 적합
- 사용 사례: 서버리스 애플리케이션 개발(작은 문서 400KB), 분산형 서버리스 캐시, SQL 쿼리 언어를 사용할 수 없음
S3
- S3는 객체의 키/값 저장소입니다.
- 더 큰 물체에는 적합하지만 여러 작은 물체에는 적합하지 않습니다.
- 서버리스, 무한 확장, 최대 개체 크기는 5TB, 시간 경과에 따른 버전 관리 기능
- 계층: S3 Standard, S3 Infrequent Access, S3 Intelligent, S3 Glacier + (계층 전환을 하려면)수명 주기 정책
- 기능:
버전 관리, 암호화, 복제, MFA 삭제, 액세스 로그... - 보안: IAM, 버킷 정책, ACL, 액세스 포인트, 객체 Lambda, CORS,
Glacier 객체/볼트 잠금 - 암호화: SSE-S3, SSE-KMS, SSE-C, 클라이언트 측, 전송 중인 TLS, 기본 암호화 체계 설정
- S3 Batch를 사용하여 모든 객체에 대한 일괄 작업
- 기존 Amazon S3 버킷의 비암호화 객체를 암호화한다던가 S3복제를 활성화하기 전에 기존 파일을 다른 버킷으로 복사할 때 유용.
- S3 Inventory를 사용하여 파일 목록 생성
- 성능:
- 파일을 병렬식으로 업로드 할 수 있는 멀티 파트 업로드
- 파일을 한 리전에서 다른 리전으로 더 빠르게 전송할 수 있는 S3 Transfer Acceleration
- Amazon S3에서 필요한 데이터만 검색할 수 있는 S3Select
- 자동화: S3 이벤트 알림(SNS, SQS, Lambda, EventBridge)
- 사용 사례: 정적 파일, 대용량 파일용 키 값 저장소, 웹사이트 호스팅
DocumentDB
- Aurora는 PostgreSQL/MySQL의 "AWS 구현"하는 방식과 비슷한 DocumentDB는 MongoDB(NoSQL 데이터베이스)용 Aurora입니다.
- MongoDB는 JSON 데이터를 저장, 쿼리 및 인덱싱하는 데 사용됩니다.
- Aurora와 유사한 "배포 개념"
- 3개의 AZ에 걸친 복제를 통한 완전 관리형 고가용성
- DocumentDB 스토리지는 10GB씩 최대 64TB까지 자동으로 증가합니다.
- 초당 수백만 건의 요청으로 워크로드에 맞춰 자동 확장
Amazon Neptune
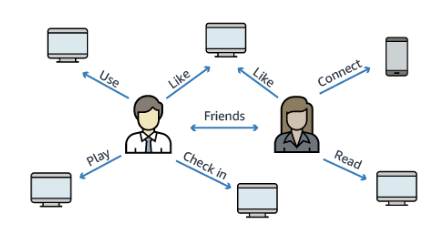
- 완전 관리형 그래프 데이터베이스
- 인기 있는 그래프 데이터 세트는 소셜 네트워크입니다.
- 사용자에게 친구를 가집니다.
- 게시물에 댓글을 가집니다.
- 댓글에는 사용자의 좋아요가 있습니다.
- 사용자가 게시물을 공유하고 좋아합니다 등등
- 최대 15개의 읽기 전용 복제본으로 3개의 AZ에서 고가용성 제공
- 고도로 연결된 애플리케이션 구축 및 실행
데이터 세트 – 이러한 복잡하고 어려운 쿼리에 최적화됨 - 최대 수십억 개의 관계를 저장하고 밀리초 대기 시간으로 그래프를 쿼리할 수 있습니다.
- 여러 AZ에 걸친 복제로 고가용성
- 사용 사례: 지식 그래프(Wikipedia), 사기 탐지, 추천 엔진, 소셜 네트워킹
Amazon Keyspaces (for Apache Cassandra)
- Apache Cassandra는 오픈 소스 NoSQL 분산 데이터베이스입니다.
- 관리형
Apache Cassandra호환 데이터베이스 서비스 - 서버리스, 확장 가능, 고가용성, AWS에서 완벽하게 관리
- 애플리케이션 트래픽에 따라 자동으로 테이블 확장/축소
- 테이블은 여러 AZ에서 3번 복제됩니다.
- CQL(Cassandra Query Language) 사용
- 모든 규모에서 한 자릿수 밀리초의 지연 시간, 초당 요청 수 1000
- 용량: 온디맨드 모드 또는 자동 확장 기능이 있는 프로비저닝 모드
- 최대 35일의 암호화, 백업, 특정 시점 복구(PITR)
- 사용 사례: IoT 장치 정보, 시계열 데이터 저장, ...
Amazon QLDB
- QLDB는 "Quantum Ledger Database"의 약자입니다.
- 원장은 금융거래를 기록한 장부
- 완전 관리형, 서버리스, 고가용성, 3AZ 간 복제
- 시간 경과에 따른 애플리케이션 데이터의 모든 변경 내역을 검토하는 데 사용됩니다.
- 불변 시스템: 어떤 항목도 제거하거나 수정할 수 없으며 암호학적으로 검증 가능
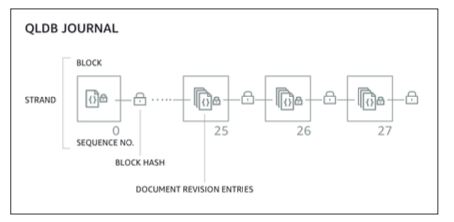
- 내부적으로 저널이 있습니다. 저널에는 수정 시퀀스가 있습니다 따라서 수정이 일어날 때마다, 암호화 해시가 계산됩니다. 아무 것도 삭제되거나 수정되지 않도록 보장하는 거죠
- 일반 원장 블록체인 프레임워크보다 2-3배 더 나은 성능, SQL을 사용하여 데이터 조작
- Amazon Managed Blockchain과의 차이점: 탈중앙화 구성 요소가 없습니다.
금융 규제 규칙
Amazon Timestream
- 완벽하게 관리되는 빠르고 확장 가능한 서버리스 시계열 데이터베이스
- 자동으로 확장/축소하여 용량 조정
- 매일 수조 건의 이벤트 저장 및 분석
- 1000배 빠른 속도 및 관계형 데이터베이스 비용의 1/10
- 예약된 쿼리, 다중 측정 레코드, SQL 호환성
- 데이터 스토리지 계층화: 최근 데이터는 메모리에 보관하고 과거 데이터는 비용 최적화된 스토리지에 보관
- 내장된 시계열 분석 기능(거의 실시간으로 데이터의 패턴을 식별하는 데 도움이 됨)
- 전송 및 미사용 암호화
- 사용 사례: IoT 앱, 운영 애플리케이션, 실시간
분석, ...
- 사용 사례: IoT 앱, 운영 애플리케이션, 실시간
Amazon Timestream – Architecture
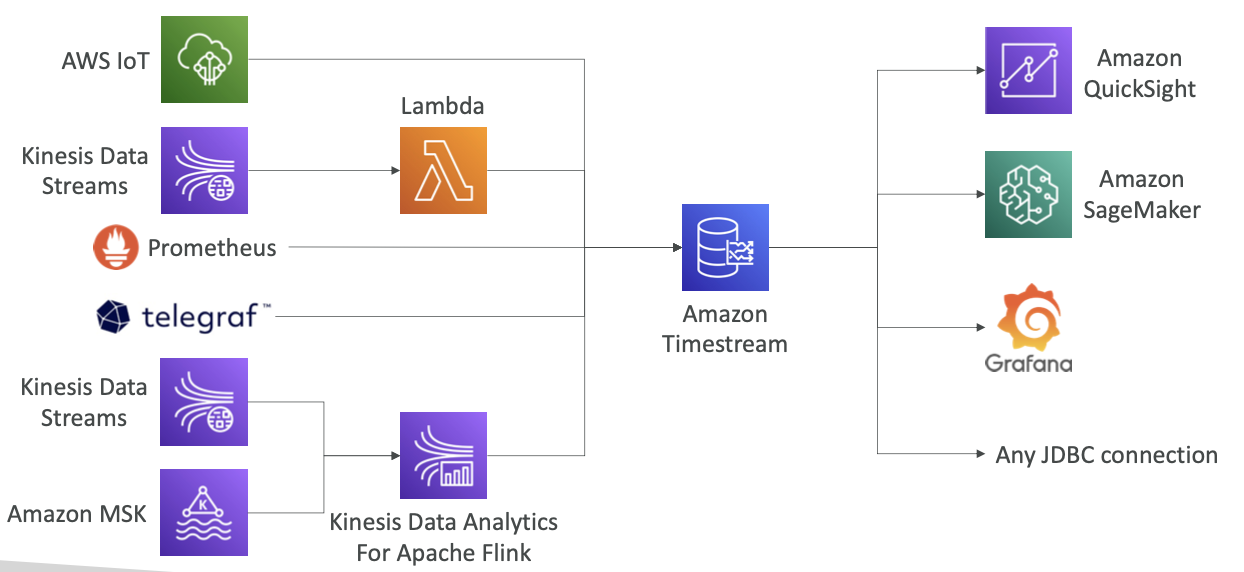
-
Timestream은 AWS IoT 즉, 사물 인터넷에서 데이터를 받을 수 있습니다.
-
Kinesis Data Streams의 데이터도 Lambda를 통해 받을 수 있습니다.
-
Prometheus, telegraf와 통합할 수 있습니다.
-
Apache Flink용 Kinesis Data Analytics는 Kineis Data Stream과 Amazon MSK의 데이터를 Amazon Timestream에 전달합니다.
-
Timestream과 연결 가능한 것으로는 대시보드를 빌드할 수 있는 Amazon Quicksight
-
기계 학습을 할 수 있는 Amazon SageMaker
-
Grafana가 있습니다
-
데이터베이스에 표준 JDBC가 연결돼 있으므로 JDBC, SQL과 호환 가능한 애플리케이션은 Amazon Timestream을 활용할 수 있습니다

42seoul, blockchain, web 3.0