
재해 복구 개요
- 회사의 비즈니스 연속성 또는 재정에 부정적인 영향을 미치는 모든 이벤트는 재난입니다.
- 재해 복구(DR)는 재해에 대비하고 재해로부터 복구하는 것입니다.
- 어떤 종류의 재해 복구입니까?
- 온프레미스 => 온프레미스: 기존 DR, 매우 고가
- 온프레미스 => AWS 클라우드: 하이브리드 복구
- AWS 클라우드 지역 A => AWS 클라우드 지역 B
- 두 가지 용어를 정의해야 합니다.
- RPO: 복구 시점 목표
- RTO: 복구 시간 목표
RPO and RTO

- 먼저 RPO 즉 복구 시점 목표란 얼마나 자주 백업을 실행할지 시간상 어느 정도 과거로 되돌릴 수 있는지를 결정합니다
- 재해가 일어나면 RPO와 재해 발생 시점 사이에 데이터 손실이 발생하겠죠
- 예를 들어 데이터를 매시간 백업한다면 재해가 발생했을 때 한 시간 전으로 돌아갈 수 있으니까 그만큼의 데이터를 잃게 됩니다
- RPO는 한 시간, 1분 등 원하는 대로 설정할 수 있습니다 RPO는 재해 발생 시 데이터 손실을 얼마만큼 감수할지 설정하는 거예요
- 반면 RTO는 재해 발생 후 복구할 때 사용됩니다 재해 발생 시점과 RTO의 시간 차는 애플리케이션 다운타임입니다
- 다운타임을 24시간으로 두기도 하는데 때로는 1분으로 설정해야 하는 경우도 있죠
- RPO와 RTO 최적화는 솔루션 아키텍처를 결정하는 요인이 되며 시간 간격이 짧을수록 비용은 높아집니다
Disaster Recovery Strategies
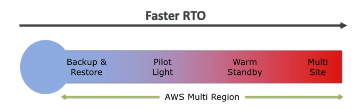
- 백업 및 복원
- Pilot Light
- Warm Standby
- Hot Site / Multi Site Approach
Backup and Restore (High RPO)
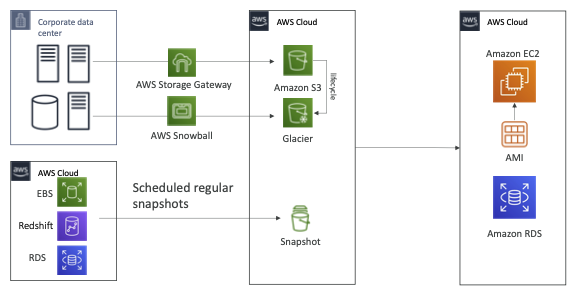
- 백업 및 복구는 RPO가 큽니다 예를 들어 기업 데이터 센터와
AWS Cloud 및 S3 버킷이 있다고 가정해 봅시다- 시간에 따라 데이터를 백업하고 싶다면 AWS Storage Gateway를 사용할 수 있습니다 수명 주기 정책을 만들어 비용 최적화 목적으로 Glacier에 데이터를 입력하거나 AWS Snowball을 사용해 일주일에 한 번씩 많은 양의 데이터를 Glacier로 전송할 수도 있죠
- Snowball을 사용하면 RPO는 대략 일주일이 되는데요 데이터 센터의 데이터가 전부 사라진다면 Snowball 장치로 일주일에 한 번만 보냈기에 한 주 치 데이터를 통째로 잃게 됩니다
- AWS Cloud를 사용하는 경우 EBS 볼륨과 Redshift RDS가 해당돼요
정기적으로 스냅샷을 예약하고 백업해 두면 24시간이든 한 시간이든 스냅샷을 만드는 간격에 따라 RPO가 달라지죠- 재해가 발생하면 모든 데이터를 복구해야 하므로 AMI를 사용해서 EC2 인스턴스를 다시 만들고 애플리케이션을 스핀 업하거나 스냅샷에서 Amazon RDS 데이터베이스 EBS 볼륨, Redshift 등을 바로 복원 및 재생산할 수 있어요
- 데이터 복구는 시간이 오래 걸리므로 RTO도 커질 테지만 값이 저렴하기 때문에 백업 및 복구 전략을 사용합니다
- 중간에서 인프라를 관리할 필요 없이 재해 발생 시 인프라를 재생산할 수 있으니까 백업 저장 비용 외에는 따로 돈이 들지 않거든요
정리하면 이렇습니다 백업 및 복구는 아주 쉽고 비용이 저렴한데 RPO와 RTO가 높습니다.
Disaster Recovery – Pilot Light
애플리케이션 축소 버전이 클라우드에서 항상 실행되고 보통 크리티컬 코어가 되는데 이를 파일럿 라이트라고 합니다

- 백업 및 복구와 아주 비슷하지만
크리티컬 시스템이 한창 작동하고 있기 때문에 복구할 때 여타 시스템만 더해 주면 되니까 속도가 더 빠르죠 - 작은 버전의 앱이 항상 클라우드에서 실행됩니다.
- 중요한 핵심에 유용함(파일럿 라이트)
- 백업 및 복원과 매우 유사
- 중요한 시스템이 이미 작동 중이므로 백업 및 복원보다 빠름
Warm Standby
웜 대기는 시스템 전체를 실행하되 최소한의 규모로 가동해서 대기하는 방법입니다
- 전체 시스템이 실행 중이지만 최소 크기입니다.
- 재해 발생 시
프로덕션 부하로 확장 가능 - ELB와 EC2 오토 스케일링이 동시에 실행되기 때문에 비용이 좀 들어갑니다.
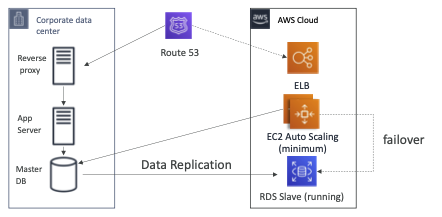
Multi Site / Hot Site Approach
- 매우 낮은 RTO(분 또는 초) - 매우 비쌉니다.
- 전체 생산 규모는 AWS 및 온프레미스를 실행합니다.

- EC2가 RDS Slave 데이터베이스에 장애 조치를 할 수 있지만 AWS와 온프레미스에서 완전 프로덕션 스케일이 실행돼 많은 비용이 발생하는데 동시에 장애 조치 할 준비가 돼 있으므로 다중 DC 유형 인프라를 실행할 수 있어 아주 좋습니다
All AWS Multi Region
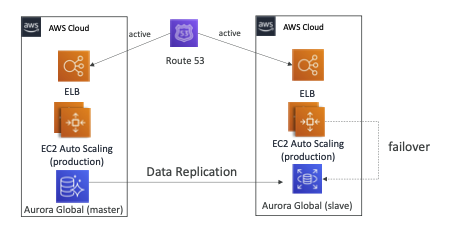
모두 클라우드로 실행하는 경우를 마지막으로 볼 텐데 아키텍처는 동일할 겁니다
다중 리전이며 클라우드 내에 있으므로 오로라 사용도 가능합니다 리전에 마스터 데이터베이스가 있고 Slave로 다른 리전에 복제된 오로라 글로벌 데이터베이스도 있습니다 두 리전 모두 잘 작동하는데 장애 조치를 할 때 필요에 따라 완전 프로덕션 스케일이 다른 리전에서 가능할 겁니다
Disaster RecoveryTips
- 백업
EBS 스냅샷,RDS 자동 백업/스냅샷등...S3/S3 IA/Glacier, 수명 주기 정책, 지역 간 복제에 대한 정기적인 푸시- 온프레미스에서:
Snowball또는Storage Gateway
- 고가용성
Route53을 사용하여 리전에서 리전으로 DNS 마이그레이션- RDS
다중 AZ, ElastiCache다중 AZ, EFS, S3 - Direct Connect에서 복구하는
site to site 간 VPN
- 복제
RDS 복제(지역 간), AWS Aurora + 글로벌 데이터베이스- 온프레미스에서 RDS로 데이터베이스 복제
스토리지 게이트웨이
- 자동화
CloudFormation/Elastic Beanstalk로 완전히 새로운 환경 재구축- 경보 실패 시 CloudWatch로 EC2 인스턴스 복구/재부팅
- 맞춤형 자동화를 위한 AWS Lambda 기능
- 혼돈
- Netflix에는 EC2를 임의로 종료하는 "simian-army"가 있습니다.
DMS – Database Migration Service
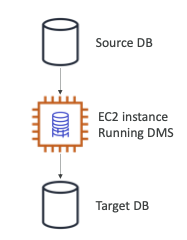
- DMS를 사용하여 신속하고 안전하게 온프레미스 데이터베이스를 AWS로 마이그레이션할 수 있습니다.
- 탄력적이고 자가 치유
- 마이그레이션 중에 소스 데이터베이스를 계속 사용할 수 있습니다.
- 지원:
- 동종 마이그레이션: Oracle to Oracle
- 이기종 마이그레이션: 예: Microsoft SQL Server에서 Aurora로
- CDC를 사용한 지속적인 데이터 복제
- 복제 작업 수행을 수행하려면 EC2 인스턴스를 생성해야 합니다.
DMS Sources and Targets
SOURCES:
- 온프레미스 및 EC2 인스턴스 데이터베이스:
Oracle, MS SQL Server, MySQL, MariaDB, PostgreSQL, MongoDB, SAP, DB2 - Azure: Azure SQL 데이터베이스
- Amazon RDS: 모두 포함 오로라
- 아마존 S3
TARGET:
- 온프레미스 및 EC2 인스턴스 데이터베이스:
Oracle, MS SQL Server, MySQL, MariaDB, PostgreSQL, SAP - 아마존 RDS
- 아마존 레드시프트
- Amazon DynamoDB
- Amazon S3
- ElasticSearch 서비스
- Kinesis Data Streams
- DocumentDB
AWS Schema ConversionTool (SCT)
- 만약 소스 데이터베이스와 대상 데이터베이스가 같은 엔진을 갖고 있지 않은 경우
- 한 엔진에서 다른 엔진으로 데이터베이스 스키마 변환
- OLTP 예: (SQL Server 또는 Oracle)에서 MySQL, PostgreSQL, Aurora로
- 예 OLAP: (Teradata 또는 Oracle)에서 Amazon Redshift로
. - 동일한 DB 엔진을 마이그레이션하는 경우 SCT를 사용할 필요가 없습니다.
- 예: On-Premise PostgreSQL => RDS PostgreSQL
- DB 엔진은 여전히 PostgreSQL입니다(RDS는 플랫폼임).
- 데이터 변환을 최적화하기 위해 컴퓨팅 집약적인 인스턴스를 선호합니다.

DMS - Continuous Replication
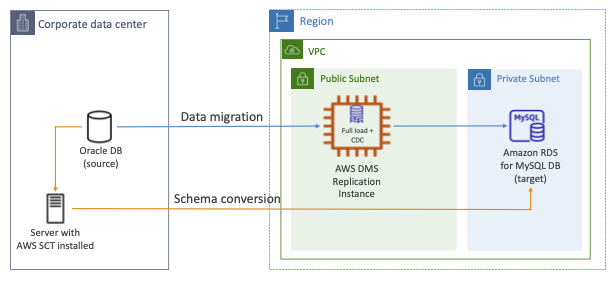
DMS에 지속적인 복제는 어떻게 설정할까요?
- 기업 데이터 센터가 있고 소스로 Oracle 데이터베이스를 쓴다고 합시다
- 대상은 MySQL DB의 Amazon RDS 데이터베이스고요 보시다시피 두 유의 서로 다른 데이터베이스가 있습니다 형이 경우에는 SCT를 쓰지 않으면 안 되겠죠
- AWS SCT를 설치해서 서버를 구축하고 온프레미스를 만들면 최적입니다 그리고 MySQL을 실행하는 Amazon RDS 데이터베이스에 스키마 변환을 합니다
- 그러면 DMS 복제 인스턴스를 설정해 풀로드(full load)와 CDC를 사용할 수 있고 지속적 복제가 생겨 온프레미스, 소스, Oracle 데이터베이스를 읽어서 마이그레이션하고 데이터를 여러분의 사설 서브넷에 삽입합니다
RDS & Aurora MySQL Migrations

- RDS MySQL에서 Aurora MySQL로
- 옵션 1: RDS MySQL의 DB 스냅샷을 MySQL Aurora DB로 복원
- 옵션 2: RDS MySQL에서 Aurora 읽기 전용 복제본을 생성하고 복제 지연이 0일 때 자체 DB 클러스터로 승격합니다(시간과 비용 $이 소요될 수 있음).
- 외부 MySQL에서 Aurora MySQL로
- 옵션 1:
- Percona XtraBackup을 사용하여 Amazon S3에서 파일 백업 생
- Amazon S3에서 Aurora MySQL DB 생성
- 옵션 1:
- 옵션 2:
- Aurora MySQL DB 생성
- mysqldump 유틸리티를 사용하여 MySQL을 Aurora로 마이그레이션(
S3 방법보다 느림)
- 두 데이터베이스가 모두 실행 중인 경우 DMS 사용
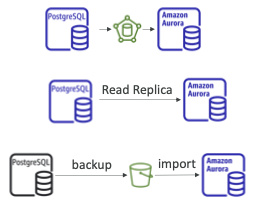
RDS & Aurora PostgreSQL Migrations
-
RDS PostgreSQL에서 Aurora PostgreSQL로
- 옵션 1: PostgreSQL Aurora DB로 복원된 RDS PostgreSQL의 DB 스냅샷
(다운타임) - 옵션 2: RDS PostgreSQL에서 Aurora 읽기 전용 복제본을 생성하고 복제 지연이 0이면 자체 DB 클러스터로 승격합니다
(시간과 비용 $이 소요될 수 있음).
- 옵션 1: PostgreSQL Aurora DB로 복원된 RDS PostgreSQL의 DB 스냅샷
-
Aurora PostgreSQL에 대한 외부 PostgreSQL
- 백업을 생성하여 Amazon S3에 저장
- aws_s3 Aurora 확장 프로그램을 사용하여 가져오기
-
두 데이터베이스가 모두 실행 중인 경우 DMS 사용
On-Premise strategy with AWS
- Amazon Linux 2 AMI를 VM(.iso 형식)으로 다운로드하는 기능
- VMWare, KVM, VirtualBox(Oracle VM), Microsoft Hyper-V
- VM 가져오기/내보내기
- 기존 애플리케이션을 EC2로 마이그레이션
- 온프레미스 VM을 위한 DR 리포지토리 전략 생성
- VM을 EC2에서 온프레미스로 다시 내보낼 수 있습니다.
- AWS 애플리케이션 검색 서비스
- 온프레미스 서버에 대한 정보를 수집하여 마이그레이션 계획
- 서버 활용 및 종속성 매핑
- AWS Migration Hub로 추적
- AWS 데이터베이스 마이그레이션 서비스(DMS)
- 온프레미스 복제 => AWS , AWS => AWS, AWS => 온프레미스
- 다양한 데이터베이스 기술(Oracle, MySQL, DynamoDB 등)과 연동
- AWS 서버 마이그레이션 서비스(SMS)
- 온프레미스 라이브 서버를 AWS로 증분 복제
AWS Backup
- 완전 관리형 서비스
- AWS 서비스 전체에서 백업을 중앙에서 관리 및 자동화합니다.
- 사용자 지정 스크립트 및 수동 프로세스를 생성할 필요가 없습니다.
- 지원되는 서비스:
- 아마존 EC2 / 아마존 EBS
- 아마존 S3
- Amazon RDS(모든 DB 엔진) / Amazon Aurora / Amazon DynamoDB
- Amazon DocumentDB / Amazon Neptune
- Amazon EFS / Amazon FSx(Lustre 및 Windows 파일 서버)
- AWS Storage Gateway(볼륨 게이트웨이)
- 교차 지역 백업 지원
- 교차 계정 백업 지원
AWS Backup
- 지원되는 서비스에 대한 PITR 지원
- 온디맨드 및 예약 백업
- 태그 기반 백업 정책
- 백업 계획이라는 백업 정책을 만듭니다.
- 백업 빈도(12시간마다, 매일, 매주, 매월, cron 표현) - 백업 기간
- 콜드 스토리지로 전환(없음, 일, 주, 월, 년)
- 보유기간(항상, 일, 주, 월, 년)
AWS Backup

AWS Backup 과정을 살펴보면 백업 플랜을 만들고 나서 여러분에게 중요한 특정 AWS 리소스를 할당합니다.이 목록은 더 늘어날 수 있습니다 그리고 할당이 완료되면 데이터가 자동으로 Amazon S3에 백업됩니다 AWS Backup에 지정된 내부 버킷에 백업되지요
AWS Backup Vault Lock

- AWS Backup Vault에 저장하는 모든 백업에 대해 WORM(Write Once Read Many) 상태를 적용합니다.
- 다음으로부터 백업을 보호하기 위한 추가 방어 계층:
- 부주의하거나 악의적인 삭제 작업
- 보존 기간을 단축하거나 변경하는 업데이트
- 활성화된 경우 루트 사용자도 백업을 삭제할 수 없습니다.
AWS Application Discovery Service
- 온프레미스 데이터 센터에 대한 정보를 수집하여 마이그레이션 프로젝트 계획
- 서버 활용 데이터 및 종속성 매핑은 마이그레이션에 중요합니다.
- Agentless Discovery(AWS Agentless Discovery Connector)
- CPU, 메모리 및 디스크 사용량과 같은 VM 인벤토리, 구성 및 성능 기록
- Agent-based Discovery(AWS Application Discovery Agent)
- 시스템 구성, 시스템 성능, 실행 중인 프로세스, 시스템 간의 네트워크 연결 세부 정보
- 결과 데이터는 AWS Migration Hub 내에서 볼 수 있습니다.
AWS Application Migration Service (MGN)
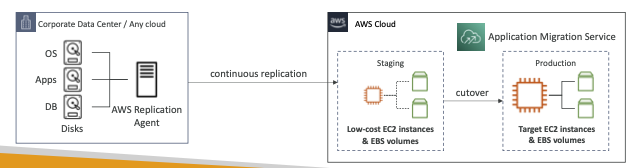
- AWS Server Migration Service(SMS)를 대체하는 CloudEndure Migration의 "AWS 진화"
- AWS로의
애플리케이션 마이그레이션을 간소화하는 리프트 앤 시프트(재호스트) 솔루션 - 물리적, 가상 및 클라우드 기반 서버를 AWS에서 기본적으로 실행하도록 변환합니다.
- 다양한 플랫폼, 운영 체제 및 데이터베이스를 지원합니다.
- 다운타임 최소화, 비용 절감
VMware Cloud on AWS
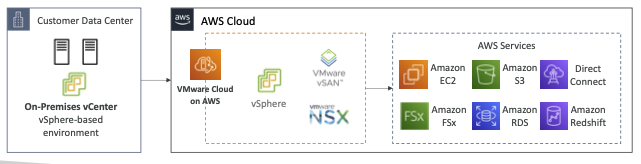
- 일부 고객은 VMware Cloud를 사용하여 온프레미스 데이터 센터를 관리합니다.
- 데이터 센터 용량을 AWS로 확장하되 VMware Cloud 소프트웨어를 계속 사용하려고 합니다. - ...EnterVMwareCloudonAWS
- 사용 사례
- VMware vSphere 기반 워크로드를 AWS로 마이그레이션
- VMware vSphere 기반 프라이빗, 퍼블릭 및 하이브리드 클라우드 환경에서 프로덕션 워크로드 실행
- 재해 복구 전략 수립
Transferring large amount of data into AWS
- 예: 클라우드에서 200TB의 데이터를 전송합니다. 100Mbps 인터넷 연결이 있습니다.
- 인터넷/사이트 간 VPN:
- 즉각적인 설정
- 200(TB)1000(GB)1000(MB)*8(Mb)/100Mbps = 16,000,000s = 185d 소요
- 직접 연결 1Gbps:
- 1회 설정이 길다(1개월 이상).
- 200(TB)1000(GB)8(Gb)/1Gbps = 1,600,000s = 18.5d 소요
- 오버 스노우볼:
- 2~3개의 눈덩이를 병렬로 처리합니다.
- 종단 간 전송에 약 1주일 소요
- DMS와 결합 가능
- 지속적인 복제/전송의 경우: Site-to-SiteVPN 또는 DMS 또는 DataSync가 포함된 DX

42seoul, blockchain, web 3.0