
표준 조인
집합 연산자
두 개 이상의 테이블에서 조인을 사용하지 않고 연관된 데이터를 조회할 때 사용하는 것을 말합니다. SELECT 절의 칼럼 수가 동일하고 SELECT 절의 동일 위치에 존재하는 칼럼의 데이터 타입이 상호 호환할 때 사용 가능합니다.
일반 집합 연산자
Union, Intersection, Difference, Product
- UNION : 합집합(중복 행 1개로) 정렬, 느림
- UNION ALL : 합집합(중복 행도 표시) 정렬X, 빠름
- INTERSECT : 교집합(중복 행 1개로)
- EXCEPT/MINUS(oracle) : 차집합(중복 행 1개로)
- CROSS JOIN : 곱집합(PRODUCT)
순수 관계 연산자
Select, Project, Join, Divide
관계형 DB를 새롭게 구현
- SELECT -> WHERE절로 구현
- PROJECT -> SELECT절로 구현
- NATRUAL JOIN -> 다양한 JOIN으로 구현
- DIVIDE -> 사용x
FROM 절 JOIN 형태
- INNER JOIN
- NATURAL JOIN
- USING 조건절
- ON 조건절
- CROSS JOIN
- OUTER JOIN
INNER JOIN
JOIN 조건에서 동일한 값이 있는 행만 반환합니다.
- INNER JOIN 표시는 그 동안 WHERE 절에서 사용하던 JOIN 조건을 FROM 절에서 정의하겠다는 표시이므로 USING 조건절이나 ON 조건절을 필수적으로 사용해야 합니다.
NATURAL JOIN
두 테이블 간의 동일한 이름을 갖 는 모든 칼럼들에 대해 EQUI JOIN 수행합니다.
- NATURAL JOIN이 명시되면 추가로 USING, ON, WHERE 절에서 JOIN 조건을 정의할 수 없습니다.
- SQL Sever는 지원 X
- JOIN에 사용된 칼럼들은 같은 데이터 유형이어야 하며, ALIAS나 테이블 명과 같은 접두사를 붙일 수 없습니다.
- NATURAL JOIN의 기준이 되는 칼럼 들이 다른 칼럼보다 먼저 출력됩니다.
USING 조건절
- 같은 이름을 가진 칼럼들 중에서 원하는 칼럼에 대해서만 선택적으로 EQUI JOIN을 할 수 있습니다.
- JOIN 칼럼에 대해서 ALIAS나 테이블 이름과 같은 접두사를 붙일 수 없습니다. SQL Server 지원x
ON 조건절
-
ON 조건절과 WHERE 조건절을 분리하여 이해가 쉬우며, 칼럼명이 다르더라도 JOIN 조건을 사용할 수 있 는 장점이 있습니다.
-
ALIAS나 테이블명 반드시 사용해야합니다.
CROSS JOIN
카티시안 곱
JOIN 조건이 없는 경우 생길 수 있는 모든 데이터의 조합을 말 합니다.
즉, 양쪽 집합의 M*N건의 데이터 조합이 발생합니다.
- NATURAL JOIN의 경우 WHERE 절에서 JOIN 조건을 추가할 수 없지만, CROSS JOIN의 경우 WHERE 절에 JOIN 조건을 추가할 수 있다
- 하지만 INNER JOIN과 같은 결과를 얻기 때문에 CROSS JOIN을 사용하는 의미가 없어집니다.
OUTER JOIN
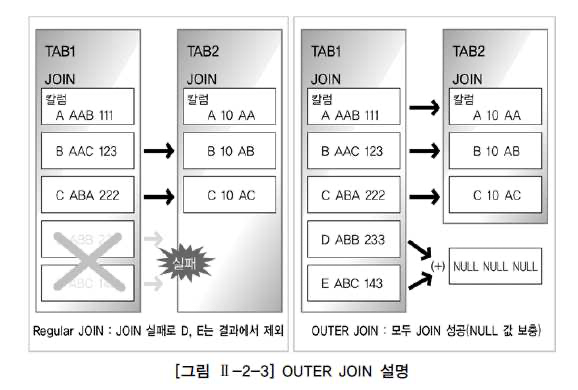
- JOIN 조건에서 동일한 값이 없는 행도 반환 가능합니다.
- USING이나 ON 조건절 반드시 사용해야 합니다.
- SQL식 에서 (+) 안붙은 쪽으로 JOIN하게 됩니다.
LEFT OUTER JOIN
먼저 표기된 좌측 테이블에 해당하는 데이터를 읽은 후, 나중 표기된 우측 테이블 에서 JOIN 대상 데이터를 읽어 옵니다.
우측 값에서 같은 값이 없는 경우 NULL 값으로 채웁니다.
RIGHT OUTER JOIN
LEFT OUTER JOIN의 반대로 작동합니다.
FULL OUTER JOIN
좌우측 테이블의 모든 데이터를 읽어 JOIN하여 결과를 생성합니다.
또한, UNION 기능과 같으므로 중복 데이터는 삭제합니다.
Join 별 비교

계층형 질의
테이블에 계층형 데이터가 존재하는 경우 데이터를 조회하기 위해서 계층형 질의(Hierarchical Query)를 사용합니다.
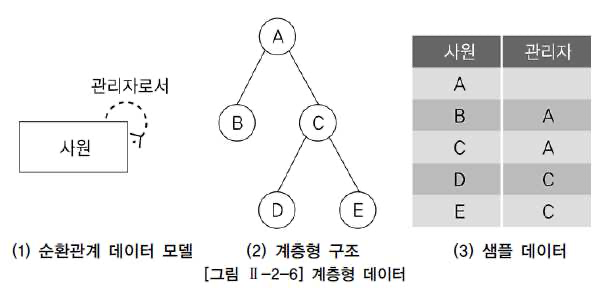
Oracle 계층형 질의

- START WITH : 계층 구조 전개의 시작 위치 지정
- CONNECT BY : 다음에 전개될 자식 데이터 지정
- PRIOR : CONNECT BY 절에 사용되며, 현재 읽은 칼럼을 지정합니다.
- PRIOR 자식 = 부모 형태를 사용하면 계층구조에서 부모 데이터에서 자식 데이터(부모-> 자식) 방향으로 전개하는 순방향 전개를 합니다. 반대는 역방향 전개
- NOCYCLE : 동일한 데이터가 전개되지 않습니다.
- ORDER SIBLINGS BY : 형제 노드간의 정렬 수행합니다.
- WHERE : 모든 전개를 수행한 후에 지정된 조건을 만족하는 데이터만 추출합니다.(필터링)
계층형 질의 가상컬럼

계층형 질의 함수

셀프 조인
셀프 조인(Self Join)이란 동일 테이블 사이의 조인을 말합니다.
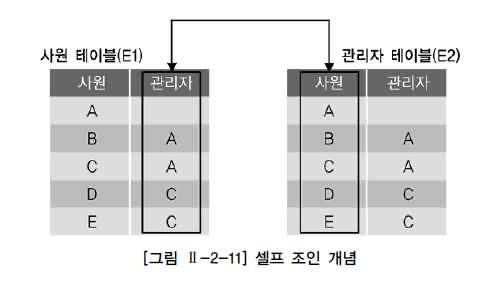
- FROM 절에 동일 테이블이 두 번 이상 나타납니다.
- 동일 테이블 사이의 조인을 수행하면 테이블과 칼럼 이름이 모두 동일하기 때문에 식별을 위해 반드시 테이블 별칭(Alias)를 사용해야 합니다.
- 칼럼에도 모두 테이블 별칭을 사용해서 어느 테이블의 칼럼인지 식별해줘야 합니다.
- 이외 사항은 조인과 동일합니다.
서브쿼리
서브 쿼리란?
하나의 SQL문안에 포함되어 있는 또 다른 SQL문입니다. 알려지지 않은 기준을 이용한 검색에 사용합니다. 또한, 서브쿼리는 메인쿼리가 서브쿼리를 포함하는 종속적인 관계입니다.

서브쿼리 특징
- 서브쿼리를 괄호로 감싸서 사용한다.
- 서브쿼리는 단일 행 또는 복수 행 비교 연산자와 함께 사용 가능합니다.
- 단일행 비교 연산자는 서브쿼리의 결과가 반드시 1건 이하여야 하고 복수행 비교 연산자는 결과 건수와 상관없습니다.
- 서브쿼리에서는 ORDER BY를 사용하지 못합니다.
- SELECT, FROM, WHERE, HAVING, ORDER BY, INSERT문의 VALUES절, UPDATE문의 SET 절에 사용 가능합니다
동작하는 방식에 따른 분류

반환되는 데이터의 형태에 따른 분류

서브쿼리 예제
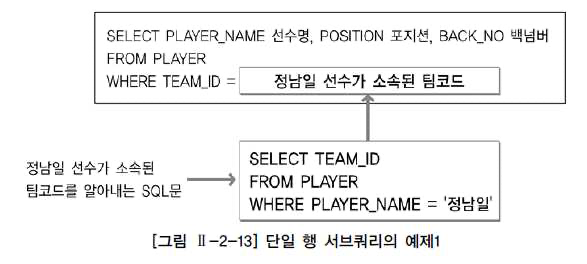
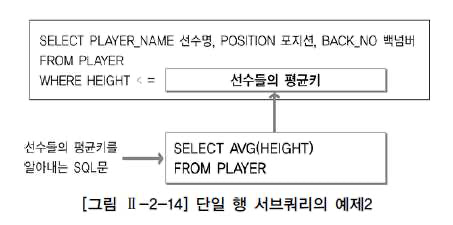
단일행 서브쿼리
- 단일 행 비교 연산자 : =,<,>,<> 등
다중행 서브쿼리

다중 컬럼 서브쿼리
다중 칼럼 서브쿼리는 서브쿼리의 결과로 여러 개의 칼럼이 반환되어 메인쿼리의 조건과 동시에 비교되는 것을 의미합니다.
- SQL Server에서는 지원되지 않는 기능입니다.
다중 행 비교 연산자 : IN, ALL, ANY, SOME 등 스칼라 서브쿼리 : 한 행, 한 칼럼만을 반환하는 서브 쿼리
연관 서브쿼리
연관 서브쿼리(Correlated Subquery)는 서브쿼리 내에 메인쿼리 칼럼이 사용된 서브쿼리입니다.
그밖에 위치에서 사용하는 서브쿼리
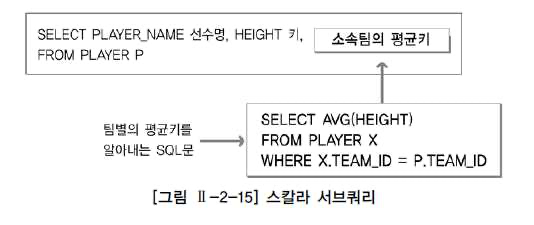
SELECT 절에 서브쿼리 사용하기
한 행, 한 칼럼만을 반환하는 서브쿼리이고, 스칼라 서브쿼리라고 불립니다.
select 절에서 쓰이는 서브쿼리를 말합니다.
FROM 절에서 서브쿼리 사용하기
FROM 절에서 사용되는 서브쿼리를 인라인 뷰(Inline View)라고 합니다.
서브쿼리의 결과가 마치 실행 시에 동적으로 생성된 테이블인 것처럼 사용할 수 있습니다.
뷰 : 테이블은 실제로 데이터를 가지고 있는 반면, 뷰 는 실제 데이터를 가지고 있지 않다. 가상 테이블이라 고도 함. 실행 시점에 SQL 재작성하여 수행됨.
인라인 뷰 : FROM 절에서 사용되는 서브쿼리이며, ORDER BY를 사용 가능합니다.
HAVING 절에서 서브쿼리 사용하기
HAVING 절은 그룹함수와 함께 사용될 때 그룹핑된 결과에 대해 부가적인 조건을 주기 위해서 사용합니다.
UPDATE문의 SET 절에서 사용하기
INSERT문의 VALUES 절에서 사용하기
뷰
테이블은 실제로 데이터를 가지고 있는 반면, 뷰(View)는 실제 데이터를 가지고 있지 않습니다.
뷰는 단지 뷰 정의(View Definition)만을 가지고 있습니다. 질의에서 뷰가 사용되면 뷰 정의를 참조해서 DBMS 내부적으로 질의를 재작성(Rewrite)하여 질의를 수행합니다. 뷰는 실제 데이터를 가지고 있지 않지만 테이블이 수행하는 역할을 수행하기 때문에 가상 테이블(Virtual Table)이라고도 한다.
뷰의 장점

뷰 사용예제
CREATE VIEW V_PLAYER_TEAM AS SELECT ... ;
DROP VIEW V_PLAYER_TEAM;
그룹 함수
그룹 함수를 사용한다면 하나의 SQL로 테이블을 한 번만 읽어 소계, 중계, 합계, 총 합계등을 손쉽게 추출할 수 있습니다.
ROLLUP
- Subtotal을 생성하기 위해 사용합니다.
- Grouping Columns의 수를 N이라고 했을 때 N+1 Level의 Subtotal이 생성됩니다.
- 인수 순서에 주의해야합니다. 순서에 따라 결과가 달라짐
GROUP BY ROLLUP (DNAME, JOB);
==
GROUP BY (DNAME, JOB)
UNION ALL
GROUP BY (DNAME)
UNION ALL
GROUP BY ()GROUPING
ROLLUP, CUBE, GROUPING SETS 등 새로운 그룹 함수를 지원하기 위해 GROUPING 함수가 추가되었습니다.
소계가 계산된 결과에는 GROUPING(EXPR) = 1 이 표시되고, - 그 외의 결과에는 GROUPING(EXPR) = 0 이 표시됩니다.
- case와 결합하여 소계의 이름을 바꾸는 데 많이 쓰입니다.
CUBE
결합 가능한 모든 값에 대하여 다차원 집계를 생성합니다.
ROLLUP에 비해 시스템에 부하가 심합니다.
GROUP BY CUBE(A, B) = GROUPING SETS(A, B, (A,B ), ())GROUPING SETS
인수들에 대한 개별 집계를 구할 수 있습니다.
-
다양한 소계 집합 생성이 가능합니다.
-
표시된 인수들 간에는 계층 구조인 ROLLUP과는 달리 평등한 관계이므로 인수의 순서가 바뀌어도 결과는 같습니다.
-
GROUPING SETS 함수 사용시 UNION ALL을 사용한 일반 그룹함수를 사용한 SQL과 같은 결과를 얻을 수 있으며, 괄호로 묶은 집합 별로(괄호 내는 계층 구조가 아닌 하나의 데이터로 간주함) 집계를 구할 수 있습니다.
윈도우 함수
윈도우 함수란?
행과 행간의 관계를 쉽게 정의하기 위해 만든 함수가 바로 WINDOW FUNCTION입니다. 즉, 행과 행간의 관계를 정의하거나 행과 행간을 비교합니다.
윈도우 함수 구조
SELECT WINDOW_FUNCTION (ARGUMENTS) OVER ( [PARTITION BY 칼럼] [ORDER BY 절] [WINDOWING 절] ) FROM 테이블 명;-
WINDOW 함수에는 OVER 문구가 키워드로 필수 포함됩니다.
-
WINDOW_FUNCTION : 기존에 사용하던 함수도 있고, 새롭게 WINDOW 함수용으로 추가된 함수도 있습니다.
-
ARGUMENTS (인수) : 함수에 따라 0 ~ N개의 인수 가 지정될 수 있습니다.
-
PARTITION BY 절 : 전체 집합을 기준에 의해 소그룹으로 나눌 수 있습니다.
-
ORDER BY 절 : 어떤 항목에 대해 순위를 지정할지 ORDER BY 절을 기술합니다.
-
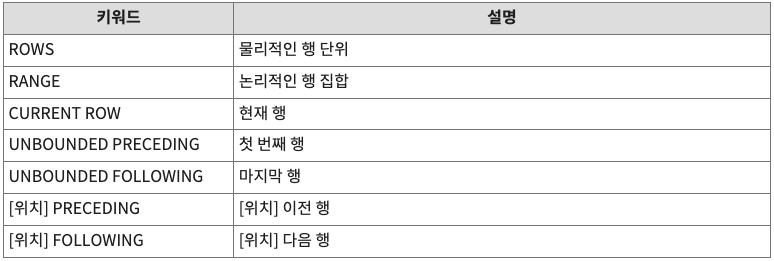
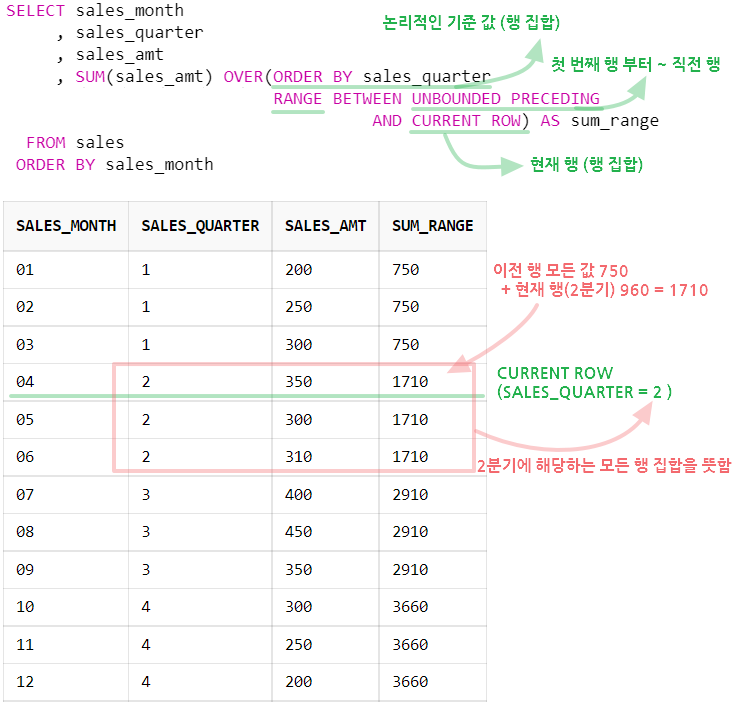
WINDOWING 절 : WINDOWING 절은 함수의 대상이 되는 행 기준의 범위를 강력하게 지정할 수 있습니다.
예를 들어, ROWS는 물리적인 결과 행의 수를,
RANGE는 논리적인 값에 의한 범위를 나타내는데,
둘 중의 하나를 선택해서 사용할 수 있습니다.
다만, WINDOWING 절은 SQL Server에서는 지원하지 않습니다.
순위 관련 함수
-
RANK : 동일한 값에 대해서는 동일한 순위를 부여 (1,2,2,4)
-
DENSE_RANK : 동일한 순위를 하나의 등수로 간 주(1,2,2,3)
-
ROW_NUMBER : 동일한 값이라도 고유한 순위 부 여 (1,2,3,4)
일반 집계 함수
-
SUM : 파티션별 윈도우의 합 구할 수 있습니다.
예) 같은 매니저를 두고 있는 사원들의 월급 합 -
MAX, MIN : 파티션별 윈도우의 최대, 최소 값을 구할 수 있습니다.
예) 같은 매니저를 두고 있는 사원들 중 최대값
-
AVG : 원하는 조건에 맞는 데이터에 대한 통계 값
예) 같은 매니저 내에서 앞의 사번과 뒤의 사번의 평균 -
COUNT : 조건에 맞는 데이터에 대한 통계 값
예)본인의 급여보다 50 이하가 적거나 150 이하로 많은 급여를 받는 인원수
window 절 키워드
ROW/RANGE
ROW

RANGE
출처:https://gent.tistory.com/473
행 순서 관련 함수
SQL Server 지원X
-
FIRST_VALUE : 파티션별 윈도우의 처음 값
-
LAST_VALUE : 파티션별 윈도우의 마지막 값
-
LAG : 파티션별 윈도우에서 이전 몇 번째 행의 값
-
LEAD : 파티션별 윈도우에서 이후 몇 번째 행의 값
그룹 내 비율 관련 함수
-
RATIO_TO_REPORT : 파티션 내 전체 SUM에 대한 행별 칼럼 값의 백분율을 소수점으로 구할 수 있습니다.
범위) > 0, <=1 -
PERCENT_RANK : 파티션별 윈도우에서 처음 값을 0, 마지막 값을 1로 하여 행의 순서별 백분율을 구합니다.
범위) 0 >=,<=1 -
CUME_DIST : 현재 행보다 작거나 같은 건수에 대한 누적백분율을 구합니다.
범위) > 0, <=1 -
NTILE : 파티션별 전체 건수를 인수 값으로 N등분한 결과를 구할 수 있습니다.
DCL
유저를 생성하고 권한을 제어할 수 있는 DCL(DATA CONTROL LANGUAGE) 명령어입니다.
Oracle과 SQL Server의 사용자 아키텍처 차이
- Oracle : 유저를 통해 DB에 접속을 하는 형태, ID와 PW 방식으로 인스턴스에 접속을 하고 그에 해당하는 스키마에 오브젝트 생성 등의 권한을 부여받게 됨
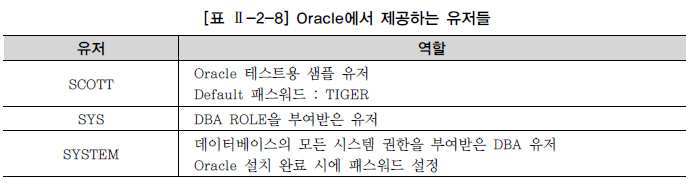
- SQL Server : 인스턴스에 접속하기 위해 로그인이라는 것을 생성하게 되며, 인스턴스 내에 존재하는 다수의 DB에 연결하여 작업하기 위해 유저를 생성한 후 로그인과 유저를 매핑해주어야 한다. Windows 인증 방식과 혼합 모드 방식이 존재함
유저 생성과 시스템 권한 부여
사용자가 SQL 문을 실행하기 위해 필요한 적절한 권한
-
GRANT : 권한 부여
-
REVOKE : 권한 취소
GRANT CREATE USER TO SCOTT;
CREATE USER PJS IDENTIFIED BY KOREA7;
GRANT CREATE SESSION TO PJS;
GRANT CREATE TABLE TO PJS;
REVOKE CREATE TABLE FROM PJS;모든 유저는 각각 자신이 생성한 테이블 외에 다른 유저의 테이블에 접근하려면 해당 테이블에 대한 오 브젝트 권한을 소유자로부터 부여받아야 합니다.
OBJECT에 대한 권한 부여
오브젝트 권한은 특정 오브젝트인 테이블, 뷰 등에 대한 SELECT, INSERT, DELETE, UPDATE 작업 명령어를 의미합니다.
모든 유저는 각각 자신이 생성한 테이블 외에 다른 유저의 테이블에 접근하려면 해당 테이블에 대한 오브젝트 권한을 소유자로부터 부여받아야 합니다.
INSERT INTO MENU VALUES (1, '화이팅');
GRANT SELECT ON MENU TO SCOTT;
SELECT * FROM PJS.MENU;Role을 이용한 권한 부여
유저를 생성하면 기본적으로 CREATE SESSION, CREATE TABLE, CREATE PROCEDURE 등 많은 권한을 부여해야 합니다.
데이터베이스 관리자는 유저가 생성될 때마다 각각의 권한들을 유저에게 부여하는 작업을 수행해야 하며 간혹 권한을 빠뜨릴 수도 있으므로 각 유저별로 어떤 권한이 부여되었는지를 관리해야 합니다.
하지만 관리해야 할 유저가 점점 늘어나고 자주 변경되는 상황에서는 매우 번거로운 작업이 될 것이기 때문에, 이와 같은 문제를 줄이기 위하여 많은 데이터베이스에서 유저들과 권한들 사이에서 중개 역할을 하는 ROLE을 제공합니다.

CREATE ROLE LOGIN_TABLE;
GRANT CREATE SESSION, CREATE TABLE TO LOGIN_TABLE;
GRANT LOGIN_TABLE TO JISUNG;
CREATE TABLE MENU2( MENU_SEQ NUMBER NOT NULL, TITLE VARCHAR2(10));
DROP USER JISUNG CASCADE;
- CASCADE : 하위 오브젝트까지 삭제 지성이 만든 테이블 삭제절차형 SQL
절차형 SQL이란?
SQL문의 연속적인 실행이나 조건에 따른 분기처리를 이용하여 특정 기능을 수행하는 저장 모듈을 생성할 수 있습니다.
저장 모듈에는 Procedure, User Defined Function, Trigger 등이 있습니다.
저장 모듈
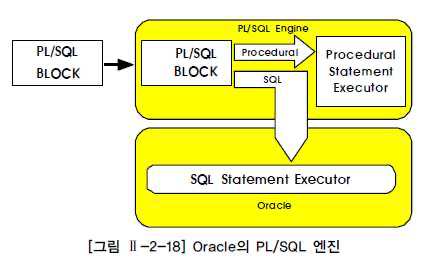
PL/SQL 문장을 DB 서버에 저장하여 사용자와 애플리케이션 사이에서 공유할 수 있도록 만든 일종의 SQL 컴포넌트 프로그램입니다.
독립적으로 실행 되거나 다른 프로그램으로부터 실행될 수 있는 완전 한 실행 프로그램이라고 할 수 있습니다.
PL/SQL 특징
-
Block 구조로 되어있어 각 기능별로 모듈화 가능
-
변수, 상수 등을 선언하여 SQL 문장 간 값을 교환
-
IF, LOOP 등의 절차형 언어를 사용하여 절차적인 프로그램이 가능하도록 한다.
-
DBMS 정의 에러나 사용자 정의 에러를 정의하여 사용할 수 있다.
-
PL/SQL은 Oracle에 내장되어 있으므로 호환성이 좋다
-
응용 프로그램의 성능을 향상시킨다.
-
Block 단위로 처리 -> 통신량을 줄일 수 있다.
PL/SQL의 구조

- DECLARE : BEGIN~END 절에서 사용될 변수와 인수에 대한 정의 및 데이터 타입 선언부
- BEGIN~END : 개발자가 처리하고자 하는 SQL문과 여러 가지 비교문, 제어문을 이용 필요한 로직 처리 필수적입니다.
- EXCEPTION : BEGIN~END 절에서 실행되는 SQL문이 실행될 때 에러가 발생하면 그 에러를 어떻게 처리할지 정의하는 예외 처리부 비필수적입니다.
T-SQL
근본적으로 SQL Server를 제어하는 언어입니다.
T-SQL의 구조
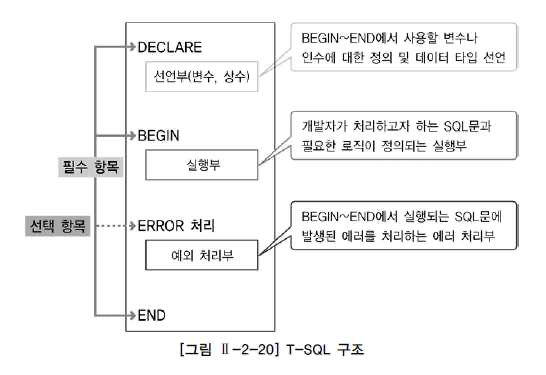
- DECLARE : BEGIN ~ END 절에서 사용될 변수와 인수에 대한 정의 및 데이터 타입을 선언하는 선언부입니다.
- BEGIN ~ END : 개발자가 처리하고자 하는 SQL문과 여러 가지 비교문, 제어문을 이용하여 필요한 로직을 처리하는 실행부입니다. T-SQL에서는 BEGIN, END 문을 반드시 사용해야하는 것은 아니지만 블록 단위로 처리하고자 할 때는 반드시 작성해야 합니다.
- ERROR 처리 : BEGIN ~ END 절에서 실행되는 SQL문이 실행될 때 에러가 발생하면 그 에러를 어떻게 처리 할 것인지를 정의하는 예외 처리부입니다. 마찬가지로 비필수적입니다.
Trigger
특정한 테이블에 INSERT, UPDATE, DELETE와 같은 DML문이 수행되었을 때, DB에서 자동으로 동작하도록 작성된 프로그램, 사용자 호출이 아닌 DB 자동 수행합니다.
프로시저와 트리거의 차이점
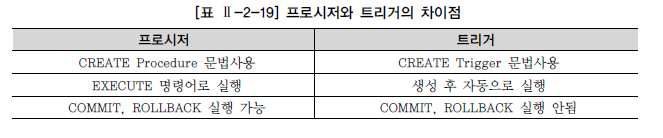
출처: SQL 전문가 가이드 서적
