Google Calendar 연동 프로젝트에 LLM API 붙이기
개요
TaskFlow Calendar에 Gemini 기반 LLM 기능을 통합하면서 주간 요약, 우선순위 추천, 자연어 Task 검색을 제품 수준으로 만들기까지 겪은 설계와 트러블슈팅을 정리했습니다. API를 붙이는 일보다 입력 데이터 정리와 운영 이슈 대응이 훨씬 더 어려웠습니다.
목차
- 왜 이 기능을 만들었는가
- sync state를 반영한 주간 요약 만들기
- 토큰과 문체를 함께 고려한 decoding 실험
- 설명 가능한 우선순위 추천 설계
- 자연어 Task 검색에서 배운 역할 분리
- 마무리
1. 왜 이 기능을 만들었는가
처음에는 단순하게 생각했습니다. 프로젝트 안의 Task를 읽어 요약을 만들고, 중요한 일을 추천하면 끝이라고 봤습니다.
하지만 실제로 구현을 시작해보니 문제는 텍스트 생성보다 훨씬 넓었습니다. 어떤 Task는 description이 길고, 어떤 Task는 제목만 있었습니다. 어떤 Task는 캘린더에 반영됐지만 최신 상태가 아니었고, 어떤 Task는 outbox가 실패한 상태였습니다. 입력 데이터를 먼저 제품 관점에서 정리하지 않으면 LLM 호출이 의미 있는 결과를 내지 못했습니다.
목표는 두 가지였습니다. 하나는 Google Calendar에 반영된 일정과 아직 반영되지 않은 업무를 구분해서 보여주는 주간 요약이고, 다른 하나는 프로젝트 맥락 안에서 어떤 업무를 먼저 봐야 하는지 설명 가능한 형태로 보여주는 우선순위 추천이었습니다. 이후에는 자연어 Task 검색까지 범위가 확장됐습니다.
2. sync state를 반영한 주간 요약 만들기
주간 요약은 POST /api/projects/{projectId}/weekly-summary API로 구현했습니다.
핵심 결정은 요약을 동기화된 일정과 미동기화 일정 두 섹션으로 분리하는 것이었습니다. 사용자는 "이번 주 일정이 어떻게 진행되고 있나"와 "아직 캘린더에 반영되지 않은 일은 무엇인가"를 같은 문장으로 섞어 읽는 것보다, 두 관점을 분리해서 보는 편이 훨씬 직관적이라고 판단했습니다.
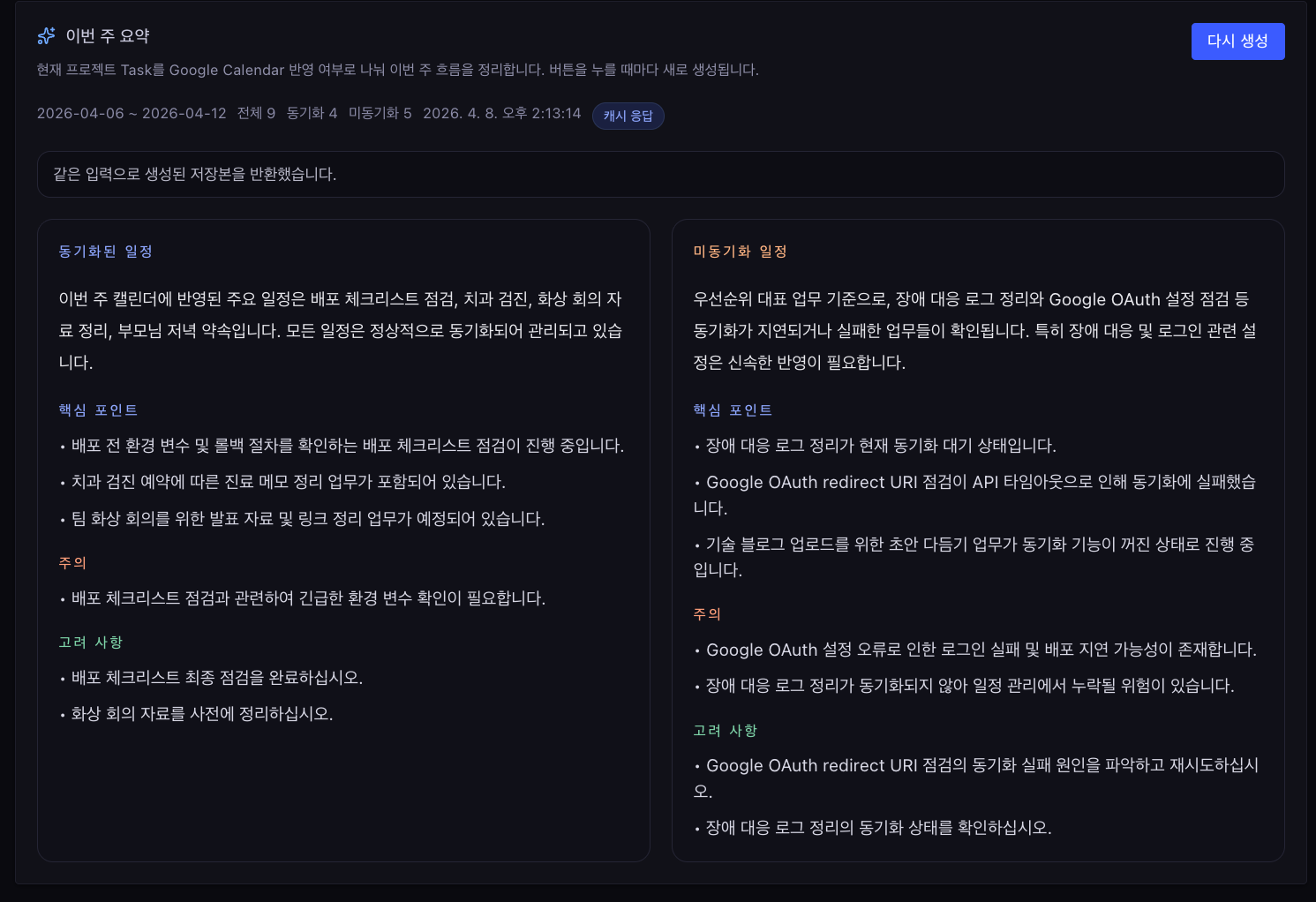
주간 요약 UI는 동기화된 일정과 미동기화 일정을 분리해 각 섹션에 별도 요약을 붙입니다.
또 하나 중요했던 건 sync state 판정 기준입니다. 단순히 calendarEventId 존재 여부만 보면 실제 상태와 어긋나는 경우가 있었습니다. 그래서 최신 outbox의 opType과 status까지 함께 보고 sync state를 판정하는 구조를 만들었습니다.
| 결과 | 의미 |
|---|---|
SYNCED | Calendar에 정상 반영된 상태 |
PENDING_SYNC | 동기화 대기 또는 진행 중 |
FAILED_SYNC | 동기화 시도 후 실패 |
SYNC_DISABLED | 동기화가 꺼진 상태 |
DELETE outbox에 대해서도 동일한 패턴으로 DELETE_PENDING과 DELETE_FAILED를 둡니다. 핵심은 calendarEventId 존재 여부만 보지 않고 latest outbox의 opType과 status, 그리고 calendarSyncEnabled를 함께 본다는 것입니다.
이 덕분에 LLM은 단순 제목 목록이 아니라 실제 운영 상태를 반영한 snapshot을 받게 됐습니다.
설계 초기에는 SYNCED와 UNSYNCED를 각각 호출해 두 번의 Gemini 요청이 발생했지만, 한 번의 요청으로 두 섹션을 함께 생성하도록 구조를 바꿨습니다.
프롬프트도 여러 번 줄였습니다. 처음에는 pretty JSON과 중복 필드가 많아 비용이 컸는데, compact JSON 기반으로 바꾸고 description 전체 대신 descBrief + descSignals를 사용하도록 줄였습니다. 섹션별 included task budget도 도입했습니다. synced는 최대 6개, unsynced는 최대 4개, done task는 섹션당 최대 1개로 제한했습니다.
3. 토큰과 문체를 함께 고려한 decoding 실험
Phase 2에서 가장 어려웠던 문제는 "요약이 거짓인가"보다 포함된 task subset이 프로젝트 전체를 충분히 대표하는가였습니다.
일부 Task만 포함하고도 요약 문장이 전체 프로젝트를 설명하는 것처럼 보이면 사용자 입장에서 과장으로 느껴질 수 있습니다. 이를 줄이기 위해 partial coverage일 때는 우선순위 대표 업무 기준이라는 범위 한정 힌트를 넣어 모델이 섹션 전체를 단정하지 않도록 유도했습니다.
다음 문제는 문체였습니다. 사실성 제약을 강화하면 과한 표현은 줄어들지만, 사용자-facing 문구가 너무 딱딱해지는 경향이 있었습니다.
그래서 summary decoding 실험을 따로 만들었습니다. temperature, topK, topP를 조합해 A/B/C/D 시나리오로 live 호출을 비교했고, 토큰 비용과 문구 품질을 함께 봤습니다.
여기서 중요한 점은 topK와 topP를 비용 절감용 숫자로만 보지 않았다는 것입니다. topK=20은 다음 토큰 후보를 상위 20개로 제한해 과도하게 튀는 표현을 줄입니다. topP=0.8은 누적 확률 상위 표현 위주로 출력해 희귀 표현과 문체 흔들림을 줄입니다. 두 값 모두 토큰 최소화보다는 사용자-facing 문체 안정화가 목적이었습니다.
네 조합은 temperature / topK / topP 순서로 구성했습니다.
- A는
0.2 / – / – - B는
0.2 / 20 / 0.8 - C는
1.0 / 20 / 0.8 - D는
1.0 / 40 / 0.95
| 시나리오 | A | B | C | D | 비고 |
|---|---|---|---|---|---|
release-and-sync-risk | 1520 | 1469 | 1432 | 1468 | C가 가장 낮음 |
onboarding-and-ops-followup | 1509 | — | 1523 | — | A가 14 tokens 낮음 |
C 조합이 항상 가장 낮지는 않았지만, release 시나리오에서는 가장 낮았고 onboarding 시나리오에서도 A와 차이가 14 tokens 수준이었습니다. 이 정도 편차는 1회 요약 규모 대비 미세한 수준이라고 판단했고, 문체 품질은 일관되게 C가 더 자연스러웠습니다.
결국 요약 기본 decoding은 C 조합으로 채택했습니다. 가장 싼 설정을 고른 것이 아니라, 토큰 편차가 감당 가능한 범위 안에서 사용자에게 더 잘 읽히는 문체를 택한 결과입니다.
gemini:
summary:
temperature: ${GEMINI_SUMMARY_TEMPERATURE:1.0}
top-k: ${GEMINI_SUMMARY_TOP_K:20}
top-p: ${GEMINI_SUMMARY_TOP_P:0.8}이 시점에 모델 선택 문제도 정리했습니다. AI Studio에는 gemini-3.1-flash-lite로 보였지만, generateContent에서 유효한 실제 모델 ID는 gemini-3.1-flash-lite-preview였습니다. models.list를 직접 조회해 확인했고, 이 모델 기준 요약 live 호출은 promptTokens=1036, totalTokens=1353 수준입니다.
gemini-2.5-flash는 free tier 기준 RPD 한도가 낮아 실험을 지속하기 어려웠기 때문에 RPD 여유가 큰 preview lite 모델을 선택했습니다.
4. 설명 가능한 우선순위 추천 설계
추천은 GET /api/projects/{projectId}/task-recommendations API로 구현했습니다.
핵심 결정은 추천을 완전한 규칙 기반 정렬로 두지 않고, 서버 후보 압축과 LLM 재정렬을 결합한 것입니다. 서버는 DONE을 제외한 미완료 Task에서 후보군을 최대 8개로 압축하고, LLM은 그 후보를 다시 비교해 우선순위, 태그, 이유를 생성합니다. 추천 개수는 ceil(미완료 Task 수 × 0.3)이며 최대 5개입니다.
이렇게 하면 토큰과 안정성을 통제하면서도, 추천 기능의 핵심인 비교와 설명은 LLM에게 맡길 수 있습니다.
처음에는 추천을 자동 조회로 두었습니다. 페이지에 들어가면 바로 추천을 생성하고, Task 생성·수정·상태 변경·삭제 후에도 자동으로 다시 호출했습니다.
그런데 이 구조는 두 가지 문제를 만들었습니다. 첫째, LLM 호출이 페이지 진입의 부수효과가 되면서 쿼터를 과도하게 소모했습니다. 둘째, 재조회가 실패해도 React Query가 이전 성공 데이터를 들고 있어 stale 추천 카드가 계속 남을 수 있었습니다.
쿼터 문제는 같은 키로 요약과 추천을 함께 돌리면 빠르게 한도에 부딪히는 구조였기 때문에, 요약·추천·검색 기능별로 Gemini 키를 분리해 해결했습니다.
UI 차원에서는 추천을 수동 생성과 수동 새로고침으로 바꿨습니다. 초기 상태에는 빈 섹션과 추천 생성 버튼만 보이고, 사용자가 직접 눌렀을 때만 LLM을 호출합니다.
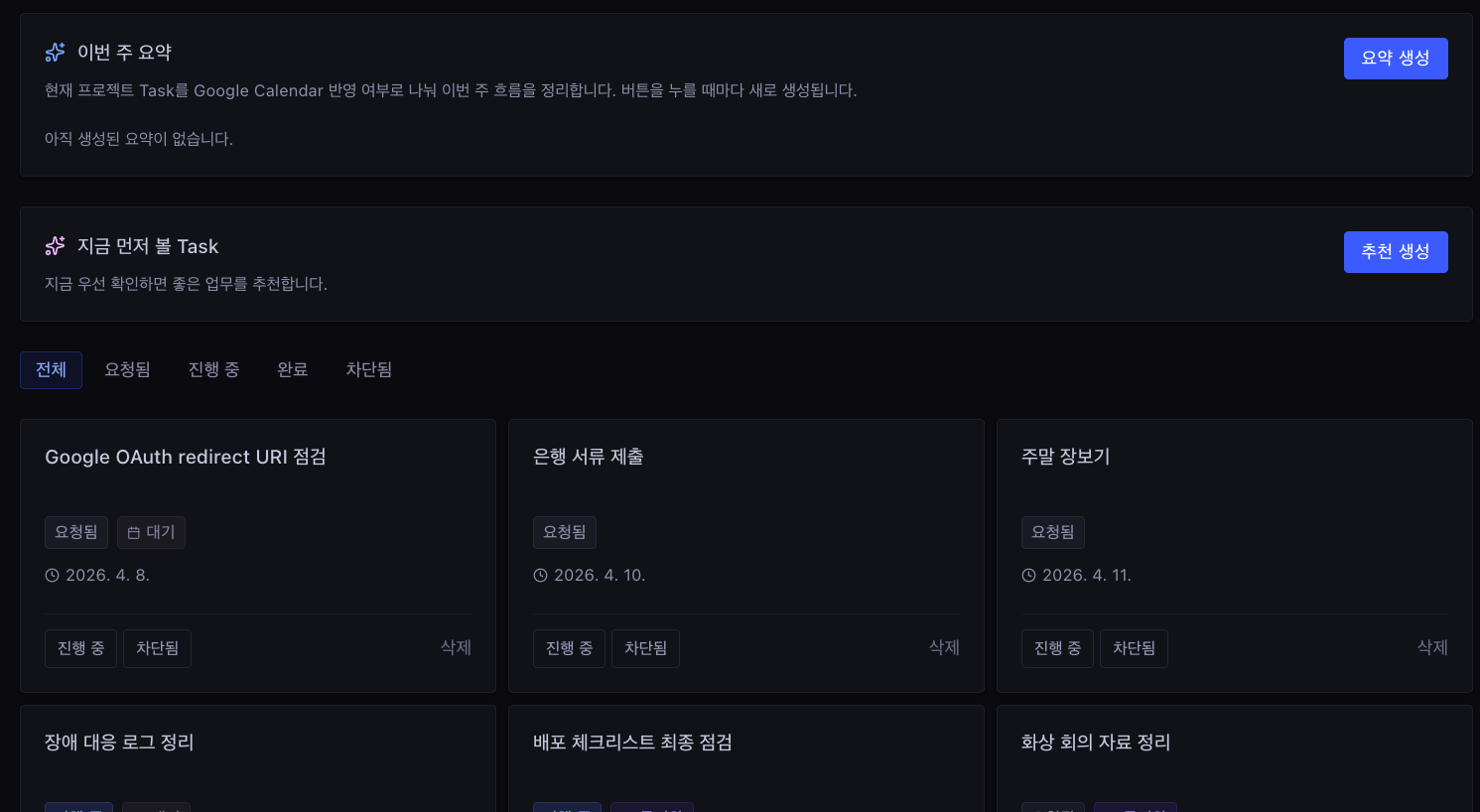
요약과 추천 모두 초기 상태에서는 빈 섹션과 생성 버튼만 노출됩니다. 사용자가 직접 누를 때까지 LLM을 호출하지 않습니다.
한 번 성공한 뒤에도 Task 변경 시 자동으로 재생성하지 않고 outdated 안내만 띄웁니다. 그리고 재요청이 실패하면 이전 추천 카드는 숨기고 에러 상태만 보여줍니다.
추천처럼 우선순위 기능은 stale 데이터를 애매하게 보여주는 것보다 실패를 분명히 드러내는 쪽이 더 신뢰할 수 있다고 판단했습니다. 추천 캐시는 Redis 기반 TTL 90초로 짧게 유지했습니다.
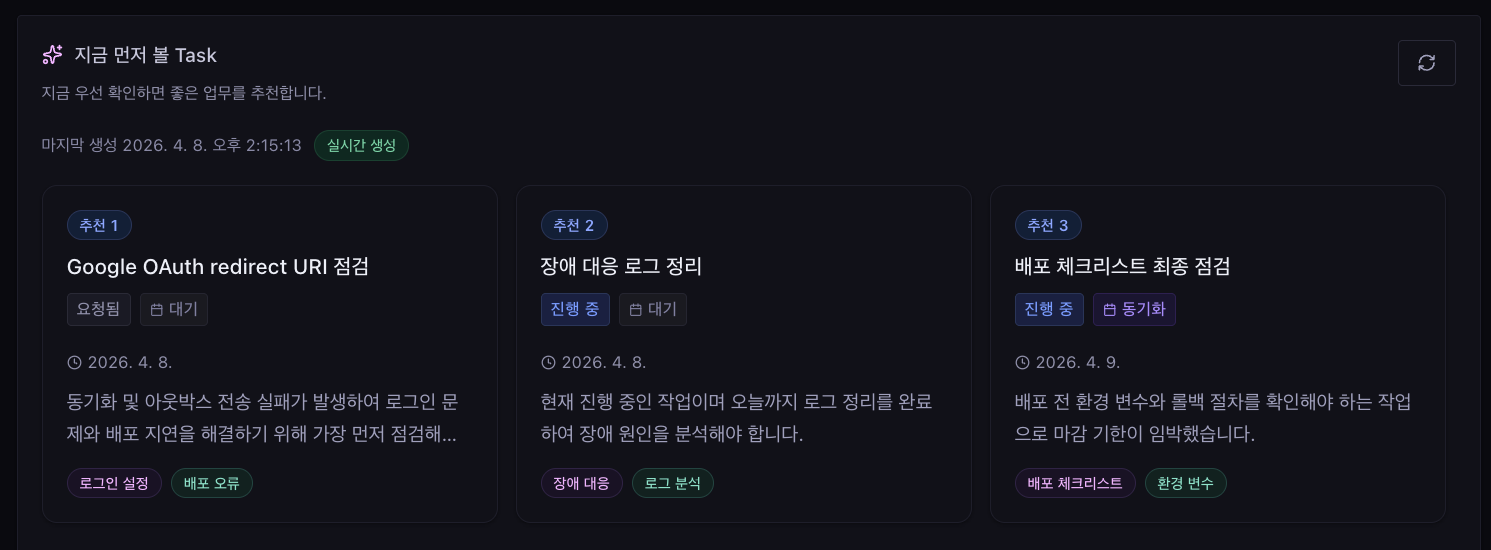
추천 생성 후에는 우선순위, 태그, 이유가 함께 노출되어 추천 근거를 바로 확인할 수 있습니다.
추천 생성 흐름을 도식화하면 아래와 같습니다.

버튼 클릭 뒤 바로 LLM을 호출하지 않고, 서버가 먼저 미완료 Task를 점수화하고 후보를 압축한 뒤 결과를 카드 형태로 보여줍니다.
토큰 비용도 측정했습니다. gemini-2.5-flash 기준 추천 live 호출은 totalTokens=955 수준이었고, gemini-3.1-flash-lite-preview 기준으로는 promptTokens=802, candidateTokens=219, totalTokens=1021로 약 6.9% 증가했습니다.
토큰은 늘었지만 RPD 여유가 훨씬 커서 실험 지속 가능성 측면에서 preview lite 모델을 채택했습니다.
5. 자연어 Task 검색에서 배운 역할 분리
자연어 검색은 POST /api/search/tasks API와 /projects 화면 검색 UI로 구현했습니다.
자연어 검색은 구조화된 질의 추출 문제로 보였습니다. LLM이 topicTerms, actionIntent, participantTerms를 반환하면 서버는 그 결과로 검색하면 된다고 생각했습니다. 하지만 실제 구현을 하면서 문제는 자연어 파싱 그 자체보다 LLM이 어디까지 결정해야 하는가에 있었습니다.
처음에는 parser가 queryType, relationPolicy, confidence까지 많은 걸 결정하도록 프롬프트를 두껍게 만들었습니다. 이 방식은 겉보기에 빨라 보이지만, 검색 정책까지 프롬프트에 묶이면서 새로운 버그가 생겼습니다.
예를 들어 화상 회의 일정들 같은 단순 topic query가 PREFER_ALL로 잘못 분류돼 retrieval 전에 fallback되는 문제가 나타났습니다. 이 경험 이후 구조를 다시 나눴습니다. 현재 핵심 원칙은 LLM은 언어 해석, 서버는 검색 정책과 정렬과 fallback입니다.
| 항목 | 수정 전 | 수정 후 |
|---|---|---|
| parser 책임 | 정책 결정 포함 | 언어 단서 추출만 |
| 서버 책임 | parser 결과 직접 사용 | parser 결과 재정규화 |
| topic 질의 처리 | RELATIONAL_SEARCH로 오분류 가능 | TOPIC_SEARCH로 보정 |
| relational 질의 처리 | TOPIC_SEARCH에 머물 수 있음 | RELATIONAL_SEARCH로 승격 |
| raw query 보강 | parser 결과에 의존 | 서버가 participant·location·action 재추출 |
이 원칙에 맞춰 검색 정책을 query type별로 분리했고, query type 판정 외에 fallback 조건도 함께 두었습니다.
| query type | must-match 조건 | semantic 처리 | relation policy |
|---|---|---|---|
TOPIC_SEARCH | topic term 있으면 topicScore > 0, 없으면 main action 필요 | topic match가 있을 때만 boost | ALLOW_PARTIAL |
RELATIONAL_SEARCH | topic·participant·companion·location·main action 모두 통과 | 위 조건 중 하나라도 맞을 때만 boost | PREFER_ALL |
BROAD_SEARCH | 위 조건 중 하나라도 통과 | base score 사용 가능 | ALLOW_PARTIAL |
structured signal이 0개이거나 1개이면서 confidence가 0.55 미만이면 검색 대신 suggested queries를 반환합니다.
검색 품질은 프롬프트를 더 길게 적는 것으로 해결하지 않고, 서버가 must match와 boost를 분리한 공통 구조로 해결하는 방향을 택했습니다.
semantic recall은 pgvector 기반으로 추가했습니다. task_search_embeddings 테이블에 projectName + title + description을 source text로 저장하고, Task 생성·수정·삭제 후 after-commit 이벤트로 갱신합니다.
다만 semantic은 주 엔진이 아니라 보조 recall 층으로만 썼습니다. topic이 분명한 질의에서는 topic anchor를 먼저 통과한 후보 안에서만 semantic과 action이 순위 보정으로 작동하도록 했습니다. 이 구조를 넣은 이유는 화상 회의 일정들에 친구 만남 약속 조율 같은 action-only 후보가 semantic 점수만으로 살아남는 현상을 막기 위해서입니다.
예를 들어 배포 준비 일정을 검색했을 때 생활 일정이 끼어드는 문제가 있었는데, 이는 앞서 말한 topic anchor와 must·boost 분리로 해결됐습니다.
누군가와 병원 가기를 검색했을 때는 설명에 아무개랑 같이가서가 들어 있는 일정을 찾지 못했습니다. 원인은 누군가를 literal participant string으로 처리한 것이었습니다. 동행은 사람 이름이 아니라 역할 조건으로 봐야 해결됩니다.
그래서 친구 같은 specific participant와 누군가와, 같이, 함께 같은 generic companion을 분리했습니다. 특정 participant가 있으면 exact-ish role match로 보고, generic companion은 동행 흔적이 있는 같은 Task를 찾는 조건으로만 사용했습니다. 반대로 누군가 어떤 일 하기처럼 구체 앵커가 없는 broad query는 검색을 강행하지 않고 fallback으로 보냅니다.
자연어 검색 UI는 질의 해석 결과와 task 결과를 함께 보여주고, 필요할 때는 suggested query도 제안합니다.
6. 마무리
이번 작업에서 가장 크게 느낀 점은 LLM 기능은 API를 붙이는 순간보다 제품 기능으로 만들기 위해 주변을 정리하는 과정이 훨씬 어렵다는 것입니다.
sync state를 어떻게 판정할지, 어떤 Task를 포함시킬지, stale 데이터를 어떻게 숨길지, 캐시를 얼마나 유지할지, free tier quota 안에서 어떻게 실험을 지속할지 같은 문제들이 실제 완성도를 좌우했습니다.
요약과 추천, 자연어 검색은 모두 동작하는 기능이 됐지만, 그보다 더 중요한 건 이후 확장을 위한 기반을 만든 것입니다. 현재 구조는 기능별 모델과 키 분리, Redis 캐시, prompt 실험 구조 위에 structured intent와 semantic recall을 얹는 단계까지 왔습니다.
프로젝트의 broad personal/social discovery 정책을 어떻게 정리하고, 운영 샘플 기반으로 fallback과 recall 균형을 어떻게 맞춰갈지 다뤄볼 생각입니다.
