
회사에서 Replication에 대해 알게 되었다. 데이터 베이스에도 Master와 Slave가 있고, 각자 맡은 역할이 다르다는 것을 배웠다.
기본적으로 테스트디비 , 운영디비 정도로만 나뉘어져 있는 줄 알았는데 성능 향상을 위해 Replication을 사용하고 있었다. 평소에 전혀 모르던 내용이라 오늘은 정리하려고 한다.
Replication이란?
데이터 베이스에 많은 데이터를 넣고, 조회하다보면 많은 쿼리를 감당해야 할 때가 온다. 그 때 Select를 처리하기 위해 사용하는 것이 Replication이다. 즉 두개 이상의 DBMS를 두고 동일한 데이터를 저장하게 한다.
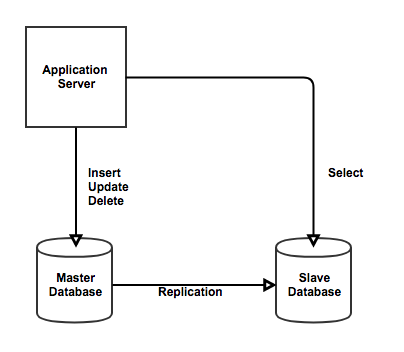
https://nesoy.github.io/articles/2018-02/Database-Replication 이미지 참고말그대로 master와 slave로 나누는데 그림에서 보이는 것처럼 slave는 select를 위주로 처리한다.
내가 생각하는 분산 시스템의 이점은 하나에 문제가 생겨도 다른 하나가 버텨야 하는 것이다. 그리고 1개로 하던 작업을 두개로 하기 때문에 속도가 빨라야 한다.
작동방식
마스터는 변경 사항을 기록하고 그 결과를 슬레이브에게 전달하게 된다. 그래서 모든 데이터 변경은 (insert, update, delete) 마스터에서만 수행되고 슬레이브는 마스터에서 변경된 사항을 받아들이기만 한다. 이렇게 읽기 작업의 부하를 여러 슬레이브로 분산시켜 성능을 향상시킨다.
1. 변경기록 : 마스터 디비는 데이터의 변경 사항을 로그 파일에 기록한다. 이 로그 파일은 바이너리로그(binary log)라고 불린다.
2. 로그 전송 : 마스터는 이 로그를 슬레이브 디비로 전송한다. 슬레이브는 마스터로부터 로그를 주기적으로 수신한다.
3. 로그 적용 : 슬레이브 디비는 받은 로그파일을 적용하여 마스터와 동일한 데이터 상태를 유지한다. 이는 슬레이브 데이터 베이스가 마스터 데이터베이스와 동기화된 상태를 유지하도록 한다.
이렇게 슬레이브는 마스터 디비의 복사본을 유지하게 되고 조회에 사용된다.
Replication 종류
-
동기식 Replication(Synchronous Replication)
- 데이터 변경이 마스터와 모든 슬레이브 동시에 적용
- 데이터의 일관성이 높지만 성능 저하가 있을 수 있다.
- 장애 복구 시 데이터 손실이 없다.
-
비동기식 Replication(Asynchronous Replication)
- 데이터 변경이 마스터에 적용된 후, 슬레이브에 비동기적으로 적용된다.
- 성능이 향상되지만, 장애발생시 데이터 손실의 위험이 있다.
-
반동기식 Replication(Semi-synchronout Replication)
- 마스터는 최대한 하나의 슬레이브가 변경 사항을 수신한 후에만 클라이언트에게 완료를 알린다.
- 동기식과 비동시기의 중간 형태로, 일관성과 성능 사이의 균형을 맞춘다.
장단점
장점
1. 확장성 : 읽기 작업을 여러 슬레이브로 분산하여 읽기 성능을 향상시킬 수 있다.
2. 가용성 : 마스터에 장애가 생기더라도 슬레이브를 이용하여 읽기 작업을 계속 수행할 수 있다.
3. 백업 및 복구 : 슬레이브 데이터베이스를 이용하여 데이터 백업이 가능하다.
단점
1. 데이터 일관성 문제 : 비동기식에서는 데이터 일관성 문제가 발생할 수 있다.
2. 복잡성 증가 : Replication 설정 및 유지 관리 복잡
3. 장애시 데이터 손실 : 비동기식 Replication에서는 마스터 장애시 최근 데이터 변경 사항이 슬레이브에 반영되지 않을 수있다.
마지막으로 데이터 베이스 복제의 알고리즘이다.
Single-Leader Replication
전체 시스템을 관리하기 위해 하나의 리더를 두고 리더가 전부 책임지는 것이다.
가장 많이 사용되는 시스템인거 같은데 주 서버가 데이터를 관리하고, 다른 복제 서버는 주 서버의 변경사항을 받아들이고 동일한 데이터를 유지하게 된다. 하나의 서버가 관리하기 때문에 데이터의 일관성이 유지되고 충돌이 방된다. 하지만 주 서버에 문제가 생기면 시스템 전체에 영향이 발생해 쓰기 요청 처리가 불가능하므로 복제 서버는 데이터를 변경할 수 없다.
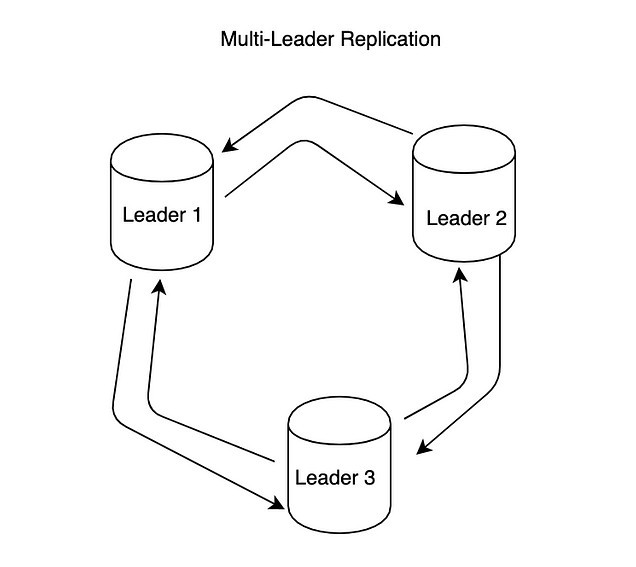
Multi-Leader
여러개의 리더를 두는 방법인데 각 리더는 다른 부분의 데이터를 관리한다. 그리고 리더끼리 서로 수정사항을 공유한다. 그래서 독립적으로 쓰기 작업을 수행할 수 있어 전체 시스템의 처리량을 향상시킨다.
또한 각 리더는 각각의 지역에 배치하여 사용자에게 더 빠른 응답을 줄 수 있고, 하나의 리더가 실패해도 다른 리더가 있기 때문에 시스템의 부분 장애를 견딜 수 있다. 하지만 독립적으로 활동하기 때문에 데이터가 다른 리더에게 공유되기까지 지연이 발생할 수 있다.
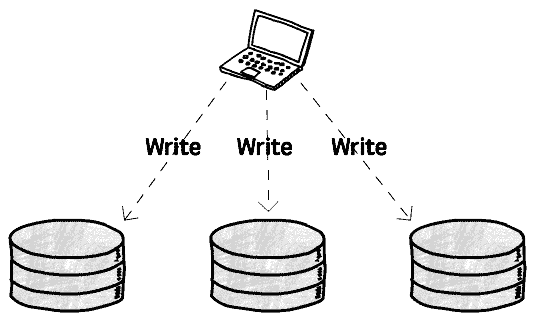
Leaderless
아예 리더가 없는 방법이다. 모든 노드가 동등하게 데이터를 복제하고 변경 사항을 전파한다.
그래서 분산된 결정권이 있고, 자율적으로 동작하여 데이터를 수정, 복제할 수 있다.
하지만 일관성유지와 데이터 병합등의 복잡함을 관리해야한다.
지금 하고 있는 골프 프로젝트에도 아마 Replication을 적용시키려고 하는데 내일은 트랜잭션에 대해 미리 공부해야겠다.

DB 서버 구성까지~ 멋져용