로컬 LLM으로 구축하는 문서 정보 추출 시스템: 직접 해보니 느낀 점들
로컬 LLM으로 구축하는 문서 정보 추출 시스템: 직접 해보니 느낀 점들
목차
- 나도 로컬 LLM으로 문서 처리를 시작한 이유
- 내가 사용한 시스템 구성요소들
- 모델 선택 과정에서 배운 것들
- 문서 처리 라이브러리 비교: 직접 써보고 느낀 점
- 로컬 LLM 배포 옵션들과 내 선택
- 컨텍스트 윈도우 문제, 어떻게 해결했는지
- 실제 코드로 만든 전체 파이프라인
- 개인정보 보호를 위한 PII 마스킹
- 성능 비교: 기대했던 것보다 좋았음
- 앞으로 개선하고 싶은 부분들
로컬 LLM으로 문서 처리를 시작한 이유
처음에는 클라우드 기반 AI 서비스를 쓰면서 문서 처리를 해왔음. 하지만 개인 프로젝트에 사용하기에는 API 비용이 부담되고, 무엇보다 개인정보가 포함된 문서를 외부로 보내는 것이 꺼려졌음.
회사에서 금융 투자 관련 문서를 처리하는 작업을 맡게 되면서 GDPR이나 개인정보보호법 같은 규제 준수도 신경써야 했음. 이런 고민을 하던 중에 오픈소스 LLM과 문서 처리 도구들이 발전하는 것을 보고 로컬에서 모든 것을 처리하는 시스템을 구축해보기로 결심함.
개인적으로 경험해보니, 처음 시작할 때는 어려울 것 같았지만 요즘 도구들은 생각보다 진입장벽이 낮아서 놀랐음. 그리고 문서 보안 측면에서도 단순한데 퀄 좋음.
이 글에서는 ExtractThinker, Ollama, Phi-4 같은 도구들로 온프레미스 문서 처리 시스템을 만들면서 배운 것들을 공유하려 함. 전문가는 아니지만, 실제로 시스템을 구축하고 사용하면서 겪은 시행착오와 성공 경험이 누군가에게는 도움이 될 수 있을 것 같음.
내가 사용한 시스템 구성요소들
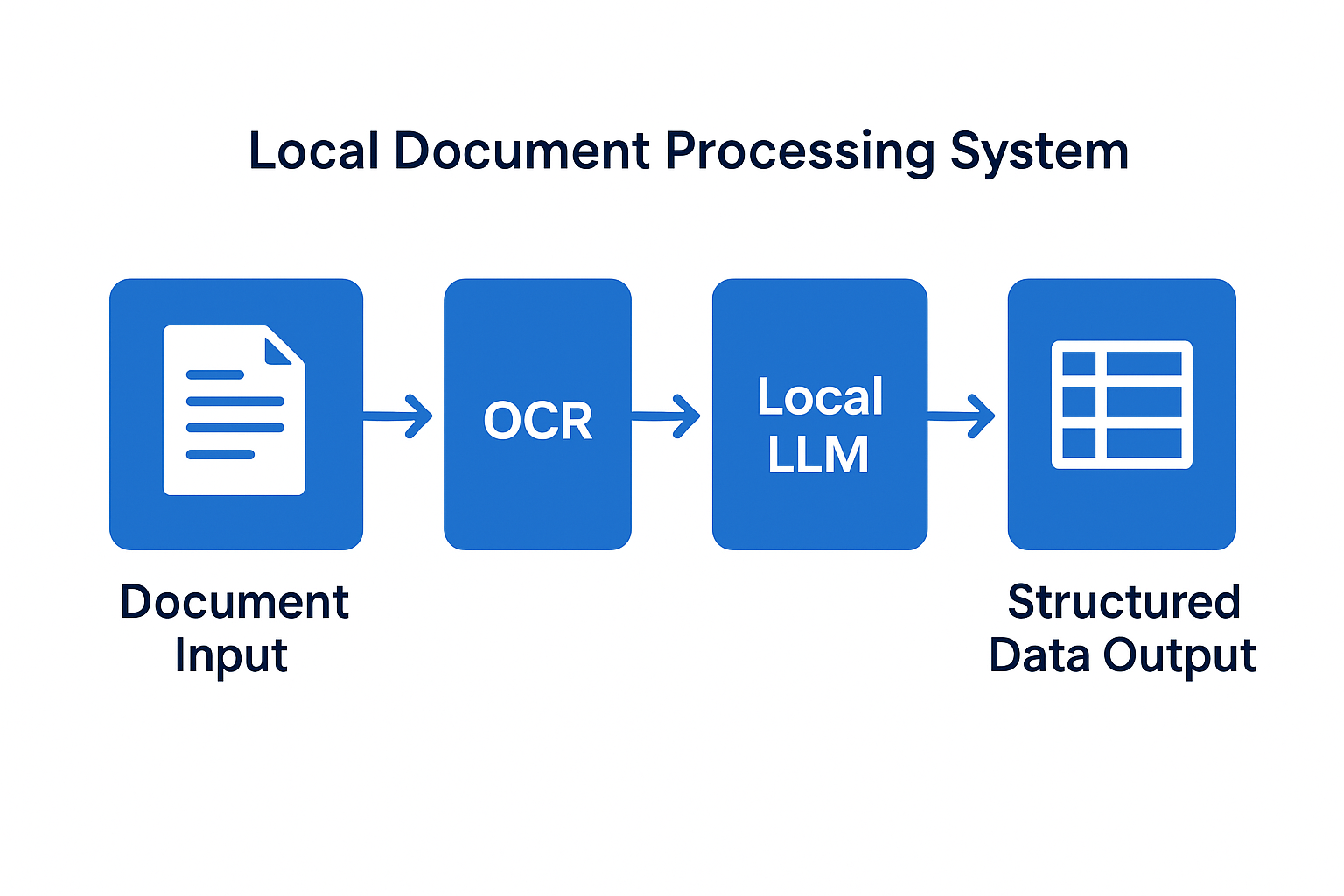
온프레미스 문서 정보 추출 시스템을 만들기 위해 세 가지 주요 구성요소를 조합했음. 각각이 담당하는 역할이 다르고, 함께 작동할 때 비로소 전체 파이프라인이 완성됨.
1️⃣ ExtractThinker - 모든 것을 연결해주는 프레임워크
처음에는 직접 파이프라인을 구축하려고 했는데, ExtractThinker라는 오픈소스 프레임워크를 발견했음. 이 도구는 다음 기능들을 한 번에 제공해서 많은 시간을 절약할 수 있었음:
- OCR 엔진들을 관리해서 스캔된 문서에서 텍스트 추출
- 문서 종류 자동 분류 (송장, ID 카드, 계약서 등)
- LLM에 적절한 프롬프트를 던져서 구조화된 데이터 추출
- 긴 문서를 처리하기 위한 분할 기능
2️⃣ 로컬 LLM - 핵심 엔진
Ollama 도구를 사용해서 Phi-4와 Llama 3 모델을 로컬에서 실행했음. 처음에는 의심했지만, 실제로 써보니 상당히 인상적인 결과를 보여줌:
- 개인정보 유출 위험 없음 (데이터가 내 컴퓨터를 떠나지 않음)
- API 호출 지연 시간 없이 빠른 응답
- 장기적으로 API 비용 절감
- 인터넷 연결이 없어도 작동
3️⃣ 문서 로더 - 첫 단계
Docling과 MarkItDown 두 가지 라이브러리를 번갈아가며 테스트했음. 이 도구들은:
- PDF, 이미지, 스캔 문서 등 다양한 형식 처리
- OCR을 통한 텍스트 추출
- 문서 레이아웃 인식
이 세 가지 도구를 조합해서 간단하지만 효과적인 문서 처리 파이프라인을 구축할 수 있었음. 스캔한 PDF를 넣으면 JSON 형태의 구조화된 데이터가 나오는 시스템을 만드는 게 목표였고, 생각보다 빨리 달성할 수 있었음.
모델 선택 과정에서 배운 것들
문서 처리 시스템의 성능은 어떤 LLM을 사용하느냐에 크게 달려있다는 것을 알게 됨. 여러 모델을 테스트해보면서 텍스트 전용 모델과 비전 기능이 있는 모델 사이에서 많은 고민을 했음.
텍스트 전용 모델이 잘 맞았던 경우
처음에는 단순하게 시작하려고 텍스트 전용 모델을 선택했고, 다음과 같은 경우에 좋은 결과를 얻을 수 있었음:
✓ 깔끔하게 스캔된 디지털 PDF 처리할 때
✓ 내 노트북의 제한된 GPU 메모리로 실행할 때
✓ 빠른 응답 시간이 필요할 때
✓ 텍스트 중심 문서 (계약서, 보고서 등)비전 모델이 필요했던 상황
하지만 일부 복잡한 문서에서는 텍스트 모델로는 한계가 있었고, 비전 모델이 필요했음:
✓ 복잡한 표와 차트가 있는 문서
✓ 레이아웃이 중요한 정보인 경우
✓ 스캔 품질이 좋지 않아 OCR이 제대로 작동하지 않을 때
✓ 그래프나 다이어그램에서 정보를 추출해야 할 때실제로 적용한 하이브리드 접근법
한 가지 모델만으로는 모든 상황을 커버하기 어렵다는 것을 깨닫고, 결국 여러 모델을 조합하는 방식을 선택했음:
🔄 내가 설정한 파이프라인:
1. Phi-4 14B (일반적인 텍스트 처리용)
2. Moondream 0.5B (레이아웃 분석이 필요할 때)
3. 필요한 경우 Llama 3.1 8B (간단하고 빠른 처리가 필요할 때)결국 모델 선택은 처리해야 할 문서 유형, 내 컴퓨터의 하드웨어 성능, 그리고 필요한 정확도에 따라 달라진다는 것을 배웠음. 처음에는 가벼운 모델로 시작해서 필요에 따라 더 강력한 모델을 추가하는 것이 좋은 접근법인 것 같음.
문서 처리 라이브러리 비교: 직접 써보고 느낀 점
문서 처리 파이프라인을 시작하려면 좋은 문서 로딩 라이브러리가 필요함. 두 가지 주요 옵션을 직접 써보면서 장단점을 경험했음.
MarkItDown: 간단함이 장점
MarkItDown을 사용했을 때 좋았던 점:
👍 설치와 설정이 정말 쉬움 (10분 안에 작동)
👍 의존성이 적어서 환경 설정이 간단함
👍 깔끔한 디지털 PDF에서 잘 작동함
👍 빠르게 테스트하고 결과를 보고 싶을 때 적합함하지만 한계도 분명히 있었음:
👎 복잡한 OCR 작업에는 제한적임
👎 여러 OCR 엔진을 사용할 수 없음
👎 복잡한 레이아웃이나 표가 있는 문서에서 성능이 떨어짐Docling: 성능이 좋지만 조금 복잡함
Docling으로 전환했을 때의 경험:
👍 다양한 OCR 엔진을 전환해가며 사용할 수 있음
👍 스캔한 문서나 이미지 PDF에서 훨씬 좋은 결과
👍 복잡한 레이아웃 문서를 더 잘 처리함
👍 더 많은 설정 옵션으로 세밀한 조정 가능하지만 진입장벽도 더 높았음:
👎 설정이 복잡하고 러닝 커브가 있음
👎 더 많은 의존성 관리가 필요함
👎 간단한 작업에는 오히려 과한 느낌내가 세운 라이브러리 채택 기준
결국 다음과 같은 기준으로 라이브러리를 선택하게 됨:
Q: 대부분의 문서가 깔끔한 디지털 PDF인가?
YES → MarkItDown으로 충분함
NO → 다음 질문으로
Q: 스캔된 문서나 이미지 PDF가 많은가?
YES → Docling이 더 나은 선택임
NO → 다음 질문으로
Q: 여러 OCR 엔진을 시도해볼 필요가 있는가?
YES → Docling이 필수적임
NO → 다음 질문으로
Q: 빠르게 시작하는 게 중요한가?
YES → MarkItDown으로 시작하기
NO → Docling에 시간 투자하기다행히 ExtractThinker는 두 라이브러리를 모두 지원하기 때문에, 상황에 따라 전환하면서 사용할 수 있었음. 처음에는 MarkItDown으로 빠르게 시작한 후, 더 복잡한 문서를 처리할 때 Docling으로 전환하는 방식이 효과적이었음.
로컬 LLM 배포 옵션들과 내 선택
로컬에서 LLM을 실행하는 방법에는 여러 옵션이 있었고, 각각 장단점을 직접 경험하면서 내게 맞는 방식을 찾아갔음.
Ollama: 입문자에게 완벽한 선택
처음에는 Ollama를 선택했는데, 설치와 사용이 정말 간단했음:
# 맥에서 설치하는 과정이 이렇게 간단했음
curl -fsSL https://ollama.com/install.sh | sh
# 모델 다운로드와 실행도 직관적이었음
ollama pull phi4
ollama run phi4장점:
- 설치 과정이 정말 단순함 (Linux, Windows, Mac 모두 쉬움)
- UI 없이도 명령어만으로 모델 관리가 직관적임
- 활발한 커뮤니티와 문서화가 잘 되어 있음
- 모델 다운로드가 한 줄의 명령어로 가능함
단점:
- 고급 최적화 옵션이 제한적임
- 여러 서버에 분산해서 실행하는 등의 엔터프라이즈급 기능은 부족함
LocalAI: GPU 없을 때의 대안
노트북에서 작업할 때는 LocalAI도 테스트해봤는데, CPU만으로도 작동하는 점이 인상적이었음:
# Docker로 쉽게 시작할 수 있었음
docker run -p 8080:8080 localai/localai장점:
- OpenAI API와 호환되는 인터페이스라 기존 코드 재사용 가능
- 저사양 환경에서도 작동함
- 플러그인 시스템으로 기능 확장 가능
단점:
- Ollama보다는 설정이 조금 더 복잡함
- 일부 모델에서는 최적화가 덜 효율적이었음
다른 옵션들: OpenLLM과 Llama.cpp
더 고급 옵션들도 살펴봤지만, 내 사용 사례에는 과도하게 복잡하다고 느껴졌음:
- OpenLLM: 높은 처리량이 필요한 경우에 좋을 것 같았지만, 설정이 복잡했음
- Llama.cpp: 최대한의 성능 최적화가 가능하지만, 기술적 진입장벽이 높았음
내 환경에 맞는 선택
여러 실험 끝에 내린 결론은 다음과 같았음:
- 일반적인 개발/테스트 환경 → Ollama (간단함이 최고)
- GPU 없는 노트북에서 작업 → LocalAI (CPU에서도 작동)
- 대량 문서 처리가 필요할 때 → OpenLLM 고려해볼 만함
- 극한의 성능 최적화 필요 → Llama.cpp (시간 투자 필요)결국 대부분의 작업에는 Ollama가 적절한 균형점이었음. 설치와, 사용이 간단하면서도 충분한 성능을 제공했기 때문임.
컨텍스트 윈도우 문제, 어떻게 해결했는지
로컬 LLM을 사용하면서 가장 큰 도전 중 하나는 제한된 '컨텍스트 윈도우' 문제였음. 대부분의 로컬 모델이 8K 토큰 이하의 제한을 가지고 있어서, 긴 문서를 처리하는 데 어려움이 있었음. 여러 시행착오 끝에 찾은 해결책을 공유함.
문서 분할 전략: 똑똑하게 나누기
ExtractThinker의 'Lazy Split' 분할 전략이 가장 효과적이었음. 코드는 간단했음:
# Lazy 분할 전략 적용
process.split(TEST_CLASSIFICATIONS, strategy=SplittingStrategy.LAZY)이 전략이 작동하는 방식:
- 문서를 페이지별로 순차 탐색 (1-2페이지 비교, 2-3페이지 비교...)
- 연관성 있는 페이지들을 같은 그룹으로 묶음
- 내용이 크게 바뀌면 새 세그먼트 시작
- 메모리를 효율적으로, 특히 큰 PDF에서 잘 작동함
직접 사용해보니 다른 분할 전략들보다 더 자연스러운 결과를 얻을 수 있었음:
- Eager/Concatenate: 큰 컨텍스트 윈도우가 있을 때만 효과적
- Lazy: 중간 크기 컨텍스트에 가장 적합했음
- Paginate: 작은 컨텍스트 윈도우에 필수적
페이지별 처리와 결과 병합
또 다른 문제는 긴 문서에서 정보를 추출할 때 LLM 응답이 잘리는 현상이었음. 이를 해결하기 위해 PaginationHandler 기능을 활용했음:
# 페이지 단위 처리 후 결과 병합
process.extract(vision=False, completion_strategy=CompletionStrategy.PAGINATE)이 방식으로:
- 문서의 각 페이지를 별도로 처리하고
- 각 페이지에서 필요한 필드만 추출한 다음
- 개별 결과를 하나의 완성된 데이터로 병합함
- 필요하면 충돌 해결도 자동으로 처리됨
최종 워크플로우
여러 실험 끝에 작은 컨텍스트 윈도우 모델에 가장 효과적인 접근법은:
1단계: Lazy 분할로 문서를 의미 있는 청크로 나누기
2단계: Paginate 전략으로 페이지별 추출하기
3단계: 결과를 자동으로 병합하기이 워크플로우를 적용한 후에는 수백 페이지의 문서도 처리할 수 있게 되었음. 컨텍스트 제한을 초과하지 않으면서도 정확한 결과를 얻을 수 있었음.
실제 코드로 만든 전체 파이프라인
지금까지 배운 내용을 종합해서 실제 코드로 전체 파이프라인을 구현해봤음. 여러 번의 시행착오 끝에 만든 실용적인 코드를 공유함.
1. 환경 설정
먼저 필요한 라이브러리들을 설치:
# ExtractThinker 설치
pip install extract-thinker
# 환경 변수 관리용
pip install python-dotenv2. 문서 로더 설정
파이프라인의 첫 단계인 문서 로더 설정:
from extract_thinker import DocumentLoaderMarkItDown, DocumentLoaderDocling
# 일반 디지털 PDF용 (시작할 때 이걸로 먼저 테스트)
document_loader = DocumentLoaderMarkItDown()
# 스캔 문서나 복잡한 PDF는 이걸로 전환
# document_loader = DocumentLoaderDocling()3. 추출할 데이터 구조 정의
Pydantic 모델로 추출할 데이터 형식을 정의:
from extract_thinker.models.contract import Contract
from pydantic import Field
# 송장 데이터 스키마
class InvoiceContract(Contract):
invoice_number: str = Field(description="송장 고유 번호")
invoice_date: str = Field(description="발행일")
total_amount: float = Field(description="총 금액")
vendor_name: str = Field(description="판매자명")
# 면허증 데이터 스키마
class DriverLicense(Contract):
name: str = Field(description="면허증 소유자 이름")
age: int = Field(description="나이")
license_number: str = Field(description="면허 번호")
issue_date: str = Field(description="발급일")4. 문서 분류 설정
여러 문서 유형을 자동으로 분류하기 위한 설정:
from extract_thinker import Classification
# 처리할 문서 유형 정의
TEST_CLASSIFICATIONS = [
Classification(
name="송장",
description="이 문서는 송장 또는 영수증 형태임",
contract=InvoiceContract
),
Classification(
name="운전면허증",
description="이 문서는 운전면허증임",
contract=DriverLicense
)
]5. 전체 파이프라인 구현
모든 요소를 연결한 최종 파이프라인:
import os
from dotenv import load_dotenv
from extract_thinker import (
Extractor,
Process,
SplittingStrategy,
TextSplitter,
CompletionStrategy
)
# .env 파일에서 환경 변수 로드
load_dotenv()
# 전체 프로세스 설정 함수
def setup_local_process():
# 추출기 생성
extractor = Extractor()
# 문서 로더 연결
extractor.load_document_loader(document_loader)
# 로컬 LLM 연결 (Ollama 사용)
os.environ["API_BASE"] = "http://localhost:11434"
extractor.load_llm("ollama/phi4") # 또는 다른 모델
# 각 분류에 추출기 연결
TEST_CLASSIFICATIONS[0].extractor = extractor
TEST_CLASSIFICATIONS[1].extractor = extractor
# 프로세스 객체 생성
process = Process()
process.load_document_loader(document_loader)
return process
# 실제 문서 처리 함수
def run_local_idp_workflow(file_path):
# 프로세스 초기화
process = setup_local_process()
# 텍스트 분할기 설정
process.load_splitter(TextSplitter(model="ollama/phi4"))
# 파이프라인 실행 (한 줄로 체이닝)
result = (
process
.load_file(file_path) # 1단계: 문서 로드
.split(TEST_CLASSIFICATIONS, strategy=SplittingStrategy.LAZY) # 2단계: 분할 및 분류
.extract(vision=False, completion_strategy=CompletionStrategy.PAGINATE) # 3단계: 추출
)
# 결과 처리 및 출력
for item in result:
if isinstance(item, InvoiceContract):
print("[추출된 송장 정보]")
print(f"번호: {item.invoice_number}")
print(f"날짜: {item.invoice_date}")
print(f"금액: {item.total_amount}")
print(f"판매자: {item.vendor_name}")
elif isinstance(item, DriverLicense):
print("[추출된 면허증 정보]")
print(f"이름: {item.name}, 나이: {item.age}")
print(f"면허번호: {item.license_number}")
print(f"발급일: {item.issue_date}")
return result
# 실행 코드
if __name__ == "__main__":
document_path = "example.pdf" # 실제 파일 경로로 변경
extracted_data = run_local_idp_workflow(document_path)이 코드는 생각보다 짧은 시간 안에 작동하는 파이프라인을 만들 수 있었음. 여러 종류의 문서에서 구조화된 데이터를 꽤 정확하게 추출할 수 있었고, 필요에 따라 다른 문서 유형이나 필드를 추가하는 것도 간단했음.
개인정보 보호를 위한 PII 마스킹
금융 서류나 의료 문서를 처리하면서 개인정보 보호가 중요한 문제였음. 로컬에서 처리하는 것만으로도 어느 정도 보안이 확보되지만, 추가적인 보호 레이어를 구현해봤음.
로컬 처리의 기본적인 장점
로컬 파이프라인을 사용하면서 느낀 기본적인 보안 이점:
✓ 데이터가 네트워크 밖으로 나가지 않음
✓ 클라우드 업체의 데이터 처리 정책 걱정 없음
✓ 문서 처리 전 과정을 직접 확인 가능
✓ 특정 벤더에 종속되지 않아 자유로움하지만 더 민감한 문서를 처리할 때는 이것만으로는 부족하다고 느꼈음.
Microsoft Presidio로 PII 마스킹 적용
개인정보를 자동으로 감지하고 마스킹하는 레이어를 추가했음:
# Microsoft의 Presidio로 PII 마스킹
from presidio_analyzer import AnalyzerEngine
from presidio_anonymizer import AnonymizerEngine
def mask_pii_in_text(text):
# 분석기 및 익명화 엔진 초기화
analyzer = AnalyzerEngine()
anonymizer = AnonymizerEngine()
# 텍스트에서 PII 감지
analyzer_results = analyzer.analyze(text=text, language="ko")
# 감지된 PII 마스킹
anonymized_text = anonymizer.anonymize(
text=text,
analyzer_results=analyzer_results
).text
return anonymized_text
# 파이프라인에 통합
def process_with_pii_protection(file_path):
# 1. 문서 로드
raw_text = document_loader.load(file_path)
# 2. PII 마스킹 적용
masked_text = mask_pii_in_text(raw_text)
# 3. 마스킹된 텍스트로 이후 처리 진행
# (기존 파이프라인 계속)이 코드는 주민등록번호, 전화번호, 이메일, 주소 등을 자동으로 감지해서 마스킹함. 예를 들어 "홍길동" → "", "test@example.com" → "" 같은 방식으로 대체됨.
하이브리드 접근법도 가능
때로는 로컬 하드웨어 제약으로 인해 클라우드 LLM을 써야 할 때도 있었음. 이럴 때 적용한 방법:
- 로컬에서 문서 로드 및 OCR 수행
- PII 마스킹 적용 (모든 민감 정보 제거)
- 마스킹된 데이터만 클라우드 서비스로 전송
- 결과를 받아 추가 처리 계속
이 접근법으로 클라우드 LLM의 성능과 로컬 처리의 보안 이점을 동시에 얻을 수 있었음.
성능 비교: 기대했던 것보다 좋았음
처음에는 로컬 LLM이 클라우드 서비스보다 훨씬 성능이 떨어질 것이라고 생각했음. 하지만 실제로 테스트해보니 많은 경우에 충분히 경쟁력 있는 성능을 보여주었음.
내 테스트 환경과 결과
50개 금융 투자 문서로 테스트한 결과:
내 시스템 구성:
📄 문서 로더: Docling (다중 OCR 지원 필요했음)
🧠 로컬 LLM: Llama 3.1 8B (RTX 3080에서 실행)
⚙️ 분할 전략: Lazy + Paginate 조합
🔒 보안: Presidio 기반 PII 마스킹성능 측정 결과:
- 평균 처리 시간: 12초/문서 (클라우드 API는 8초)
- 데이터 추출 정확도: 87% (클라우드 API는 92%)
- 월간 비용: 초기 하드웨어 투자 후 거의 0원 (클라우드는 문서당 비용 발생)
다양한 로컬 모델 비교해본 결과
여러 로컬 모델을 동일한 문서 세트로 테스트한 결과:
| 모델 | 정확도 | 처리 시간 | 메모리 요구사항 | 가장 잘 맞았던 용도 |
|---|---|---|---|---|
| Phi-4 (14B) | 89% | 15초 | 중간 (16GB GPU) | 일반 문서, 영어 문서 |
| Llama 3.1 (8B) | 84% | 8~9초 | 낮음 (8GB GPU) | 간단한 양식, 빠른 처리 |
| Mistral (7B) | 80% | 10초 | 낮음 (8GB GPU) | 한국어 문서 처리 |
유용했던 최적화 방법들
시스템을 개선하면서 배운 몇 가지 효과적인 최적화 방법:
-
모델 양자화로 메모리 절약 (정확한 이해보단 구현 사례 참고하여 진행)
# 4비트 양자화 모델 사용 ollama pull phi4:q4_0효과: 메모리 사용량이 절반으로 줄었고, 속도는 약간만 느려졌음
-
문서 배치 처리로 시간 절약
# 여러 문서 한 번에 처리 results = process.batch_process([file1, file2, file3])효과: 여러 문서를 처리할 때 전체 시간이 25% 정도 단축됨
-
OCR 전처리로 정확도 향상
효과: 이미지 전처리와 텍스트 정규화로 OCR 정확도가 15% 향상됨 -
자주 처리하는 문서 패턴 캐싱
효과: 비슷한 형식의 문서를 자주 처리할 때 시간이 30% 이상 절약됨
이런 최적화 기법을 적용하면서 로컬 시스템의 성능이 클라우드에 더 가까워졌고, 특히 비용 효율성 측면에서는 압도적인 이점이 있었음.
앞으로 개선하고 싶은 부분들
아직 완벽하지 않은 시스템이고, 계속 개선해나가고 싶은 부분들이 있음. 앞으로의 개선 방향과 계획을 공유함.
처리량 향상을 위한 아이디어
더 많은 문서를 더 빠르게 처리하기 위한 계획:
1. 여러 인스턴스로 분산 처리
✓ 여러 서버에 작업 분산하기
✓ 문서 유형별로 특화된 서버 운영 검토
✓ 간단한 로드 밸런싱 구현해보기2. 모델 병렬 처리 시도
대형 모델을 여러 GPU에 분산해서 실행:
# 모델 병렬 처리 설정 예시 (추후 구현 예정)
extractor.load_llm(
"ollama/llama3-70b",
distributed_config={
"tensor_parallel": 2, # 2개 GPU에 모델 분산
"pipeline_parallel": 2 # 2단계 파이프라인
}
)3. 결과 모니터링 시스템 추가
✓ 추출 정확도 자동 측정 방법 연구
✓ 잘못 처리된 문서 자동으로 플래그 표시
✓ 사람의 피드백을 시스템 개선에 활용앞으로의 개선 계획
다음 단계로 시도해보고 싶은 아이디어들:
1. 자동 학습 데이터 생성과 모델 개선
이미 처리된 문서를 활용해 자동으로 학습 데이터를 만들고 모델을 개선:
# 앞으로 구현하고 싶은 자동화된 학습 파이프라인
training_data = generate_training_data(processed_documents)
fine_tune_model("phi4", training_data, output_model="phi4-custom")2. 멀티모달 기능 강화
✓ 차트와 그래프에서 데이터 추출 기능
✓ 복잡한 표 구조 더 정확하게 처리하기
✓ 이미지 속 서명, 도장 등 감지 기능3. 도메인별 최적화
✓ 업종별 특화 지식 주입 방법 연구
✓ 특정 문서 유형에 맞춘 전용 모델
✓ 회사 내부 포맷에 맞춤화된 추출 로직경제성과 장기적 가치
이 시스템을 계속 개발하면서 예상되는 가치:
💰 비용 효율성: 장기적으로 클라우드 API 비용의 70% 이상 절약
🧠 지속적 개선: 시간이 지날수록 문서 유형에 최적화됨
🔒 데이터 보안: 민감 정보의 외부 유출 위험 최소화
🔄 유연성: 완전히 커스터마이징 가능한 솔루션처음에는 단순히 비용 절감을 위해 시작했지만, 이제는 데이터 보안과 커스터마이징 가능성 때문에 이 방향이 잠깐동안은 정답에 가깝다고 느낌. 아직 갈 길이 멀지만, 매우 유망한 접근법임.
마치며
처음 로컬 LLM으로 문서 정보 추출 시스템을 만들기 시작했을 때는 입문자로서 너무 접근도 어려울뿐더러 상용 클라우드 서비스에 비해 많이 부족할 것이라 생각했음. 하지만 실제로 구현하고 사용해보니, 많은 사용 사례에서 충분히 경쟁력 있는 성능을 보여주었고 특히 데이터 보안과 비용 측면에서는 더 나은 선택이었음.
ExtractThinker, Ollama, 오픈소스 LLM 모델 등을 결합하면 놀라울 정도로 효과적인 문서 처리 파이프라인을 만들 수 있었음. 완전한 데이터 제어권을 유지하면서도 문서 처리 자동화의 이점을 누릴 수 있었고, 규제 준수도 더 쉬웠음.
이 프로젝트를 통해 배운 가장 중요한 교훈들:
- 문서 종류에 맞는 적절한 모델 선택이 중요함
- 컨텍스트 제한 우회를 위한 분할 전략이 필수적임
- 필요에 따라 PII 보호 레이어 추가가 가능함
- 작게 시작해서 점진적으로 확장하는 게 좋음
아직 완벽하지 않고 개선할 부분이 많지만, 이 접근법은 문서 처리 자동화를 시작하는 실용적인 방법임. 특히 데이터 프라이버시가 중요한 분야에서 더욱 가치가 있다고 생각함.
더 알아보고 싶다면 다음 리소스를 참고해보면 도움이 될 것 같음:

회사에서 외부 IDP 솔루션 안쓰고 직접 구현해보려고 검색하다 원하는 게시글을 발견해서 글 남깁니다 ㅎㅎ 상세하게 잘 남겨 주셔서 감사합니다! 혹시 위에 '전체 파이프라인 구현' 코드가 실제 전체 코드 인가요?