최근 Meta에서 출시한 SAM(Segment Anything Model)을 알아보았다. SAM
데모도 잘 되어있고, Segmentation 속도도 매우 빨라서 신기했다.
직접 객체를 클릭해 분리하는 방법, Box로 해당 영역 객체를 분리하는 방법, 전체 이미지를 알아서 분리하는 방법이 있다.
Demo 페이지에서 도로 크랙 데이터를 업로드 해보았다.
대부분의 이미지에서 우리가 원하는 크랙에 대해서는 Segmentation을 잘 하지 못 했다.
하지만, 확실히 눈에 띄는 포트홀의 경우 분리를 잘 해내는 것을 확인했다.



현재는 Segmentation 보다 Detection이 우선인 상황이기도 하여, 이것과 관련해 조금 더 찾아보았다.
SAM 웹페이지에서 text-to-object segmentation이 가능하다는 것을 확인했다.

탐색 결과 Language SAM 오픈소스를 찾을 수 있었다. Language Segment-Anything
굉장히 사용하기 쉬운 형태로 제공되어 금방 돌려볼 수 있었다.
먼저 WebUI 형태로 사용하고 싶었지만, Colab 내에서 웹페이지 접속이 허용되지 않아 사용할 수 없었다.
이미지와 텍스트를 입력으로 주면, 객체의 위치를 예측해 Bounding Box 좌표를 포함한 Object Detection 결과를 반환한다.
텍스트를 Class에 대한 정보로 인식할 것으로 예상했고, 그렇게 몇 번 테스트를 해보았다.
(1) Prompt : 'pothole'




눈에 띄는 포트홀에 대해서 깔끔하게 모두 감지해냈다.
Prompt에 단독으로 'crack'을 입력했을 경우, 잘 수행해내지 못 하여 실망했지만 'pothole'로 바꿔 사용해보니 매우 잘 예측해냈다.
(2) Prompt : 'pothole, cracks'




포트홀과 크랙을 동시에 감지해냈다.
하지만, 일부 이미지에서 포트홀만 단독으로 예측했을 때보다 포트홀에 대한 예측이 떨어지는 것을 볼 수 있었다.
'crack'을 단독으로 사용하는 것보다는 더 나은 성능을 보였다.
'crack'보다는 'cracks'를 사용할 때 더 나은 성능을 보였다.
(3) Prompt : 'pothole, cracks, cars'

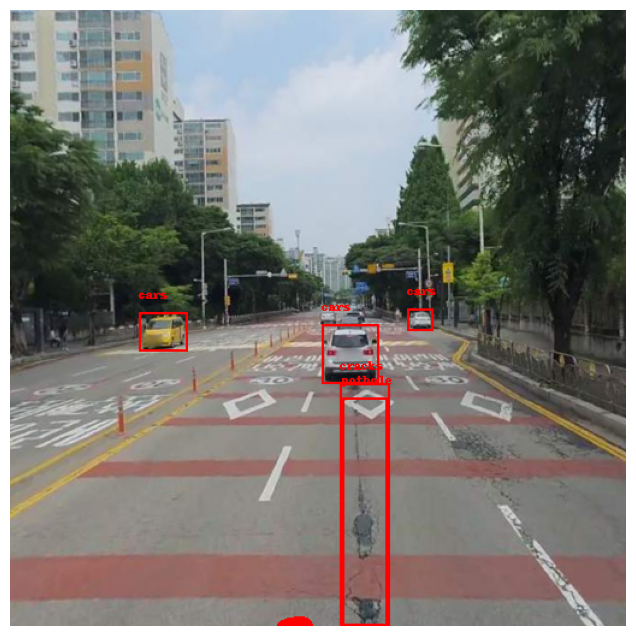


포트홀과 크랙, 차량까지 동시에 감지하도록 시도해보았지만 성능이 썩 좋진 않았다.
빨간색으로 채워진 경우가 종종 있는데, 원인은 잘 모르겠다.
'cars' 대신 'building'으로 했을 때도 비슷한 현상이 나타났다.
현재까지는 Prompt로 'pothole'을 단독으로 사용하거나, 'pothole, cracks' 이렇게 사용하는 것이 가장 좋은 성능을 보이는 것 같다.
마스킹 된 이미지도 한 번 출력해보았다.



확실히 크랙보다는 포트홀을 더 잘 인식하는 경향이 있는 것 같다.
분석 속도도 훌륭하고, 성능 또한 우수하다.
이렇게 탐지가 잘 되면 이전의 계획들이 다 무슨 의미가 있을까 생각이 들기도 했다.
우선은 보류해두고 원래 계획인 학습 데이터 증강에 집중해봐야겠다.
