사실상 StyleGAN2 모델은 포기한 상태이다.
3일 동안 진행되던 학습이 중단됐다.
- 저장된 모델로 학습 재개 → 실패
- 새로운 데이터셋으로 처음부터 학습 → 실패
모두 같은 에러가 발생해 진행할 수 없었다.
Traceback (most recent call last):
File "C:\Users\user\IN-ISP\Hyeongjun\stylegan2-ada-pytorch\train.py", line 17, in <module>
import torch
File "C:\Users\user\anaconda3\lib\site-packages\torch\__init__.py", line 123, in <module>
raise err
OSError: [WinError 1455] 이 작업을 완료하기 위한 페이징 파일이 너무 작습니다. Error loading "C:\Users\user\anaconda3\lib\site-packages\torch\lib\caffe2_detectron_ops_gpu.dll" or one of its dependencies.RAM 부족으로 발생한 문제 같은데,
내 환경에서는 가상머신 서버에 접근할 수 없어 해결이 불가능할 것 같다.
모르는 거 붙잡고 끙끙대지 말라던 선배님께 오랜만에 질문 한 번 드려야겠다.
Diffusion Model 알아보기 시작했다.
교수님께서 참고 자료를 많이 보내주셨다.
Stable Diffusion web-ui 를 이용해 이미지를 직접 생성해보았다.
아래 링크를 참고하여 Colab에서 웹앱을 직접 실행할 수 있었다.
Stable-Diffusion-webui
img2img :
prompt에 기입된 텍스트와 업로드한 이미지를 기반으로, AI 모델의 처리를 거쳐 이미지를 생성하는 기능을 제공한다.
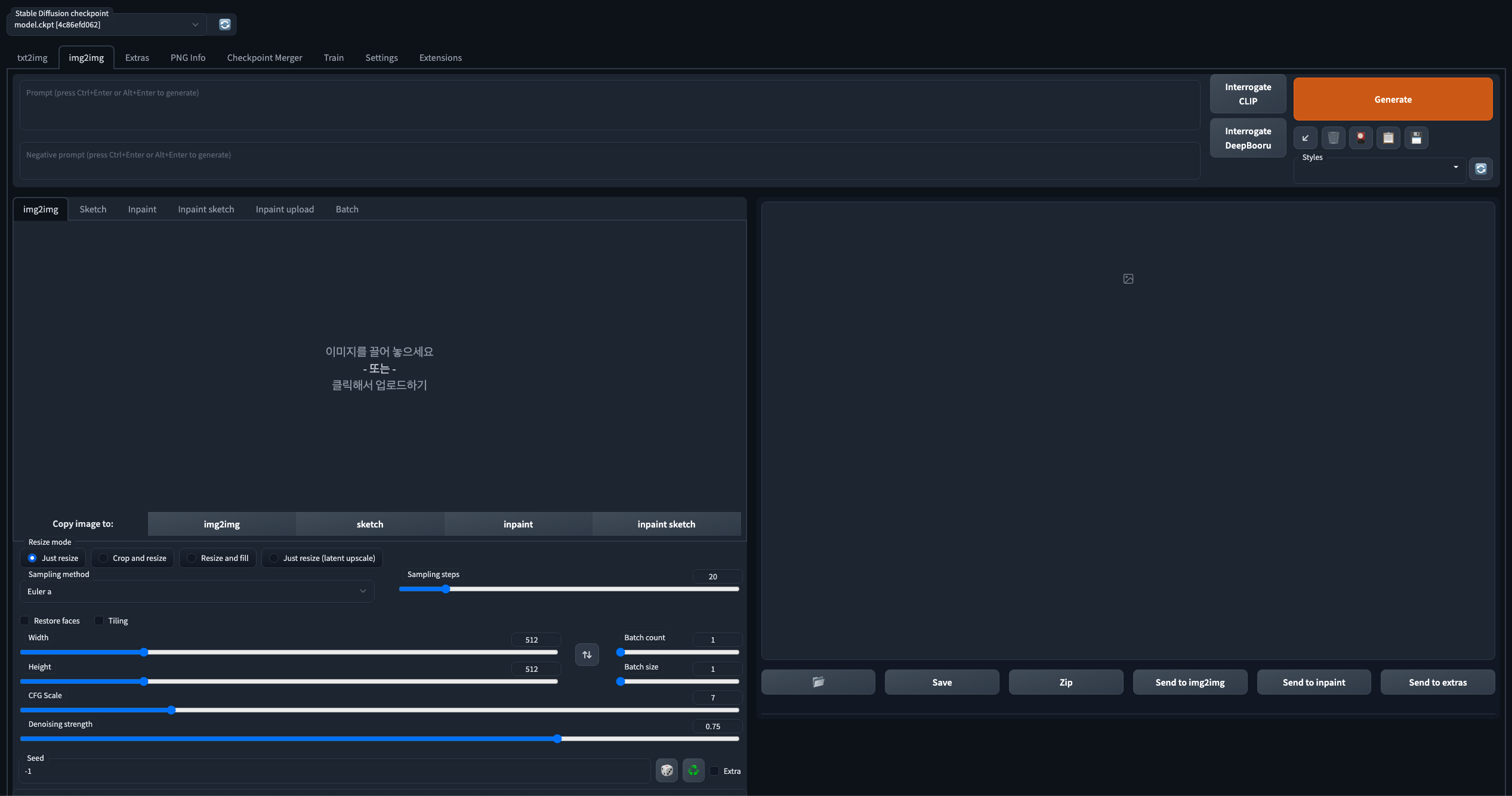
기본 사용법
-
prompt : 단어 혹은 문장 입력
-
Width / Height : 생성될 이미지의 너비 / 높이 설정
-
Sampling steps : 피드백 공정을 실시하는 횟수 (높을수록 정교한 이미지)
-
Batch count / Batch size : 생성될 이미지의 수 설정
-
CFG Scale : AI가 prompt 입력값(텍스트)을 참고하는 정도 (낮을수록 관계없는 이미지 생성)
-
Denoising strength : AI가 업로드된 이미지를 참고하는 정도 (높을수록 관계없는 이미지 생성)
-
생성된 이미지는 구글 드라이브 /sd/stable_diffusion_webui/output/ 에 자동으로 저장됨
이미지 생성
다양한 이미지를 넣어보며 감을 익히고, 적절한 파라미터 값들을 찾았다.
-
prompt :
"road with fine cracks"
("small cracks" 보다 "fine cracks" 가 더 잘 나옴) -
Sampling steps : 30
(2D 이미지의 경우, 25~35) -
CFG Scale : 11
(7~12) -
Denoising strength : 0.2
(클수록 크랙이 과장되게 나옴, 0.15~0.3)
결국 크랙이 있는 도로 이미지를 생성할 수 있었다.
부자연스러운 이미지도 있지만, 이미지 생성 속도나 품질은 GAN을 압도하는 것 같다.
web-ui 이용해 성능을 맛 봤으니, 이제는 자동으로 증강하고 저장할 수 있도록 코드를 짜 봐야겠다.