우리의 연구 방향을 다시 한 번 되짚었다.
'이미지 데이터 증강 + Object Detection 모델 개발'을 목적으로 시작했지만, 둘 중 하나에 집중하는게 옳지 않을까 생각이 들었다.
새로운 아키텍처를 제안하는 논문의 경우, 고정된 데이터셋으로 학습 시킨 후 평가지표를 통해 성능을 정량적으로 나타낸다.
예를 들어, ImageNet 또는 COCO 데이터로 학습시킨 모델을 mAP와 IOU를 기반으로 성능을 비교한다.
즉, 우리가 새로운 모델을 제안하려면 제대로 된 성능을 측정하기 위해
충분한 학습이 가능한 대용량 데이터셋이 준비되어야 한다.
기존 크랙 탐지 연구에서 Object Detection 성능이 좋지 못 했던 근본적인 원인은 훌륭한 학습 데이터셋의 부족이다.
데이터가 실제 도로 환경을 반영하지 못 하거나, 세밀하지 않은 라벨링으로 pothole과 crack의 구분이 어렵다는 문제가 대표적이다.
- NHA12D: A NEW PAVEMENT CRACK DATASET AND A COMPARISON STUDY OF CRACK DETECTION ALGORITHMS
- NHA12D Dataset
결국, 우리는 크랙 탐지를 위한 데이터셋 구축에 집중하기로 했다.
Data-Centric AI는 알고리즘이나 모델에만 주목할 것이 아니라 데이터에 더 주목해야 한다는 관점이다.
훌륭한 학습 데이터셋을 구축하고, SOTA 모델에 fine-tuning 한다면 크랙 탐지를 이전보다 잘 해낼 것이라고 생각한다.
하지만, 데이터셋 구축도 결코 쉬운 연구는 아닐 것이다.
연구에 가장 메인이 되는 것은 Stable Diffuion 생성 이미지로 학습 데이터의 양을 늘리는 것이다.
다양한 형태로 생성된 크랙 이미지가 학습에 도움 될 것이라고 생각하지만, 큰 기대는 못 하겠다.
Object Detection은 이미지 속 객체에 대한 class와 bounding box 라벨링이 필요하다.
우리는 이미지 생성부터 라벨링까지 모든 작업을 해내야 하는 것이다.
가장 먼저 시도할 방법은 다음과 같다.
- 약 300장의 이미지에 대해 직접 Annotation 한다. (bounding box)
- Stable Diffusion으로 각 8장씩, 총 2400장의 이미지를 생성한다.
- 생성된 이미지에 원본 이미지와 같은 레이블을 부여한다.
원본 이미지 : (X1, Y1)
생성 이미지 : (X2, Y1), (X3, Y1), (X4, Y1), ... , (X8, Y1) - 구축된 데이터셋으로 YOLOv8 Object Detection을 수행한다.
Stable Diffusion으로 생성된 이미지는 크랙의 형태만 바뀌기 때문에, bounding box 위치는 바뀌지 않음을 이용한다.
위 방법이 실패한다면, semi-supervised learning을 이용한 방법을 생각해봐야겠다.
300장 이미지에 대한 Annotation은 팀원들과 분배하여 진행할 것이다.
그러기에 앞서, 개인적으로 50장에 대해 먼저 테스트 해보았다.
Roboflow를 이용해 데이터셋을 업로드 하고,
다음과 같이 이미지에 직접 bounding box를 표기할 수 있다.
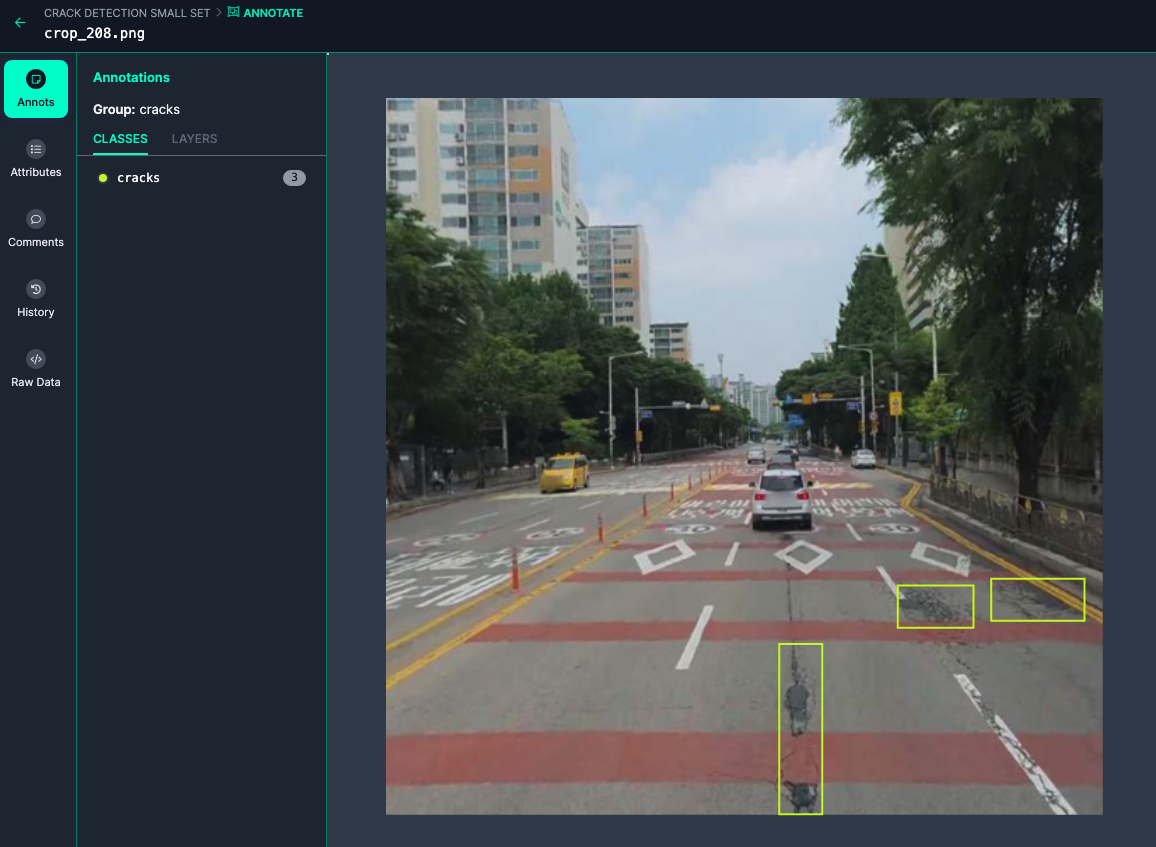
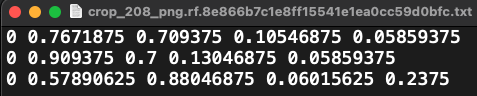
해당 레이블 값은 다음과 같이 저장된다.
bounding box 좌표 :
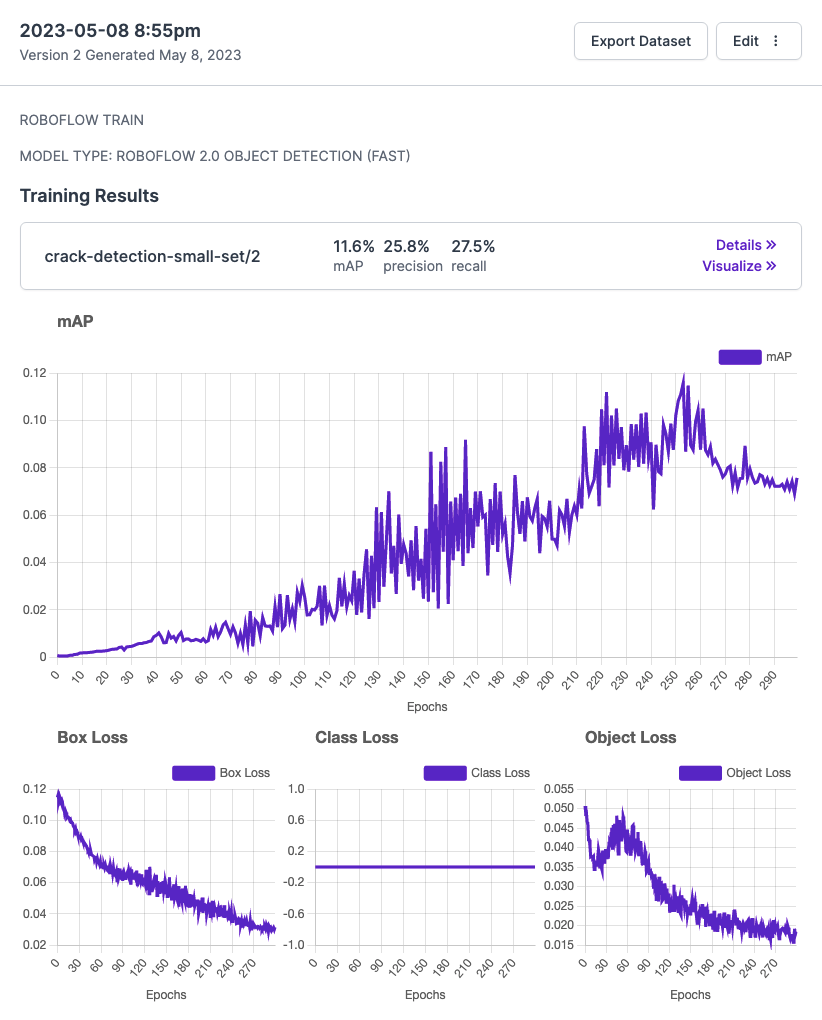
50장의 이미지는 Train/Valid/Test 각 35장/10장/5장으로 나뉘었고, 학습 결과는 다음과 같다.
건물을 크랙으로 잘못 인식한 경우, 크랙을 중복으로 인식한 경우가 발견되었다.



Roboflow는 데이터셋에 증강 기법을 자동으로 적용해주는 기능도 존재한다.
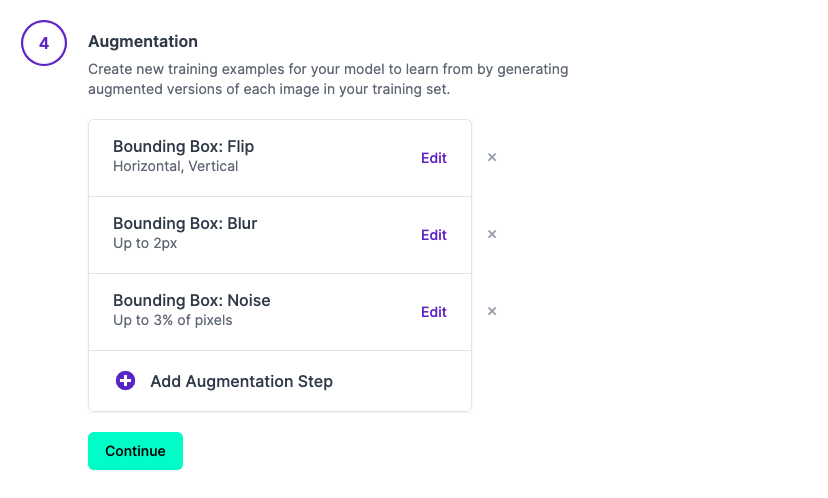
이를 이용했을 때 학습 결과는 다음과 같다.
데이터 증강을 이용했을 시, 학습 데이터 수는 많아지지만 성능은 오히려 더 떨어지는 것을 확인했다.
적절하지 않은 증강 기법을 선택한 것일 수도 있으니 아직 확실하게 판단할 수는 없다.



추가로, Roboflow에는 AutoML 기능도 있다.
데이터셋만 넘겨주면 모든 과정을 자동으로 해주는 기능으로 알고 있다.
학습 및 테스트 결과를 지표로 제공하고, 간단하게 이미지를 업로드 해서 바로 테스트 해 볼 수 있도록 모델도 만들어준다.
무료로 3번까지 이용할 수 있는 듯 하다.
학습 데이터를 충분히 확보한 후에 다시 이용해 볼 생각이다.

이번 주 할 것들 :
- 크랙 탐지 관련 선행연구 조사 (인용 수 많은 것 위주)
- 인원 분배하여 Annotation 완료하기
