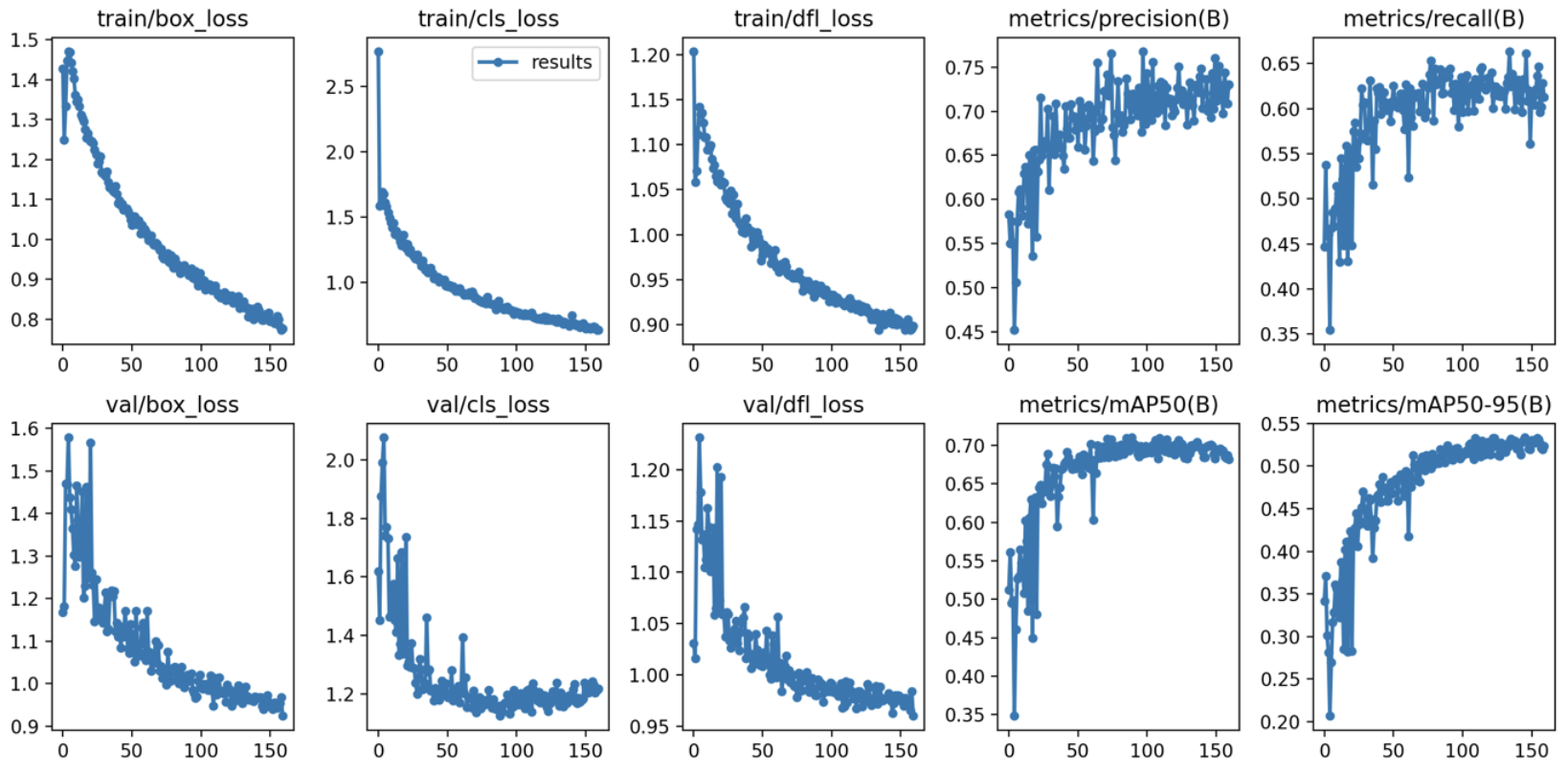
학습 데이터셋에 따른 YOLOv8 Object Detection 결과를 비교해보았다.
실험 내용을 정리해보면 다음과 같다.
(1) 원본 이미지는 300장이다.
(2) Stable Diffusion을 이용한 이미지 생성으로 데이터셋을 증강시킨다.
(3) 각 데이터셋을 사용하여 YOLOv8 모델을 학습시킨다.
(4) 평가 지표 및 객체 탐지 결과를 비교한다.
실험 환경은 다음과 같다.
- Google Colab, GPU NVIDIA A100-SXM4-40GB
- YOLOv8
- batch size = 16 / epochs = 500 / EarlyStopping(patience = 50)
- 모든 이미지는 512x512 크기로 Resize 되었음
실험 결과
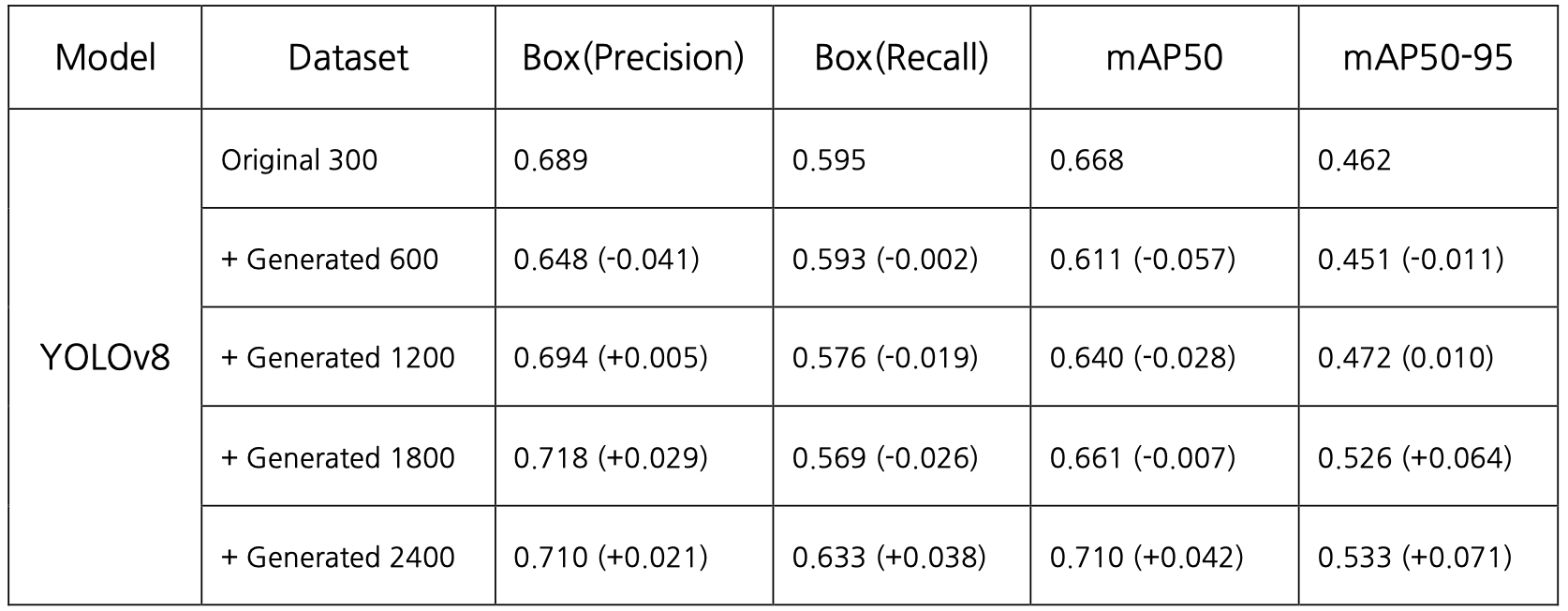
(1) 원본 이미지 300장
학습 결과 :
- Box(Precision) : 0.656
- Box(Recall) : 0.51
- mAP50 : 0.546
- mAP50-95 : 0.386
- 추론 속도 : 2.6ms
- 학습 소요 시간 : 43분 15초
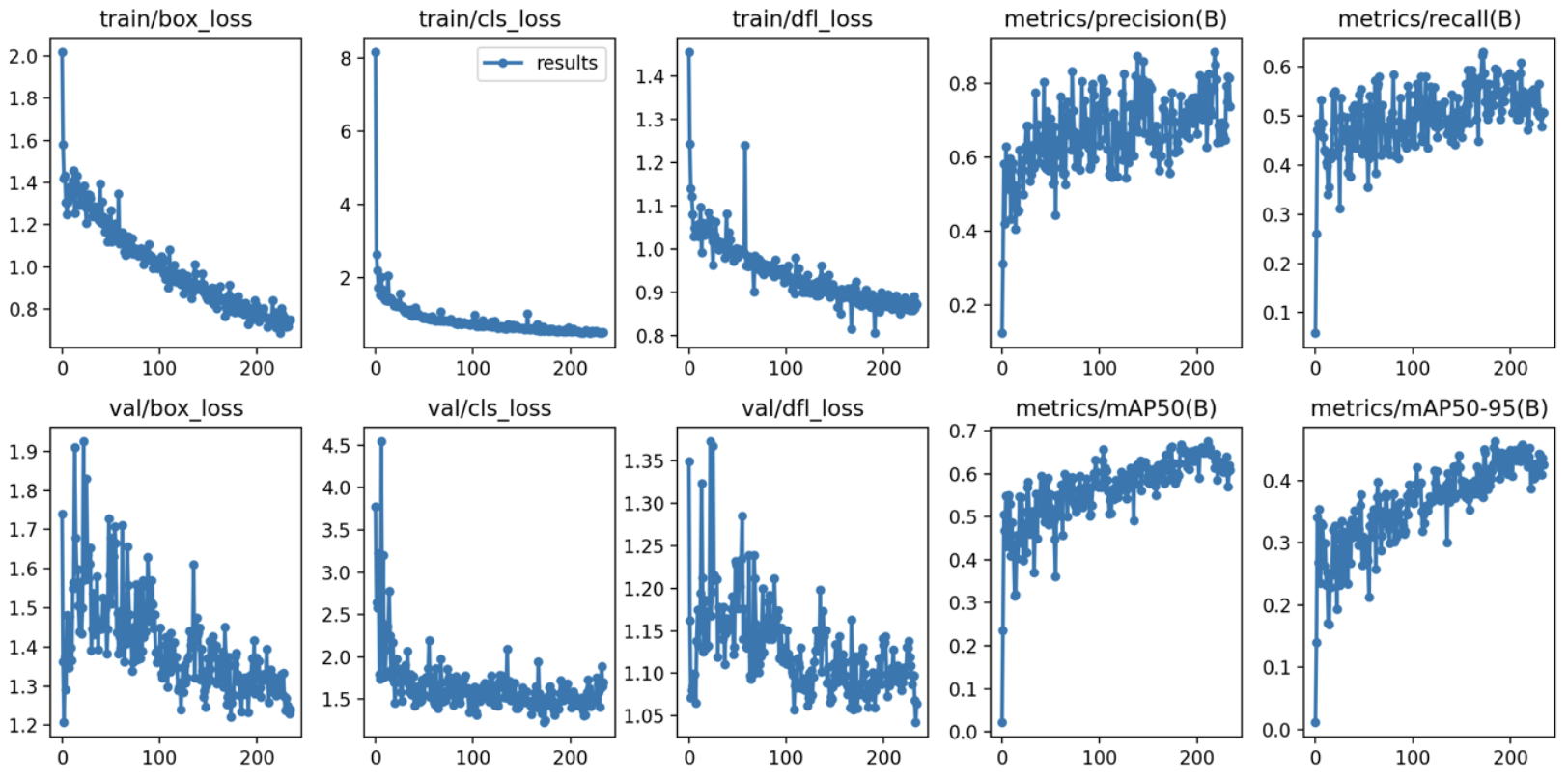
(2) 원본 이미지 300장 + 생성 이미지 300장(이미지 당 1장씩 생성)
학습 결과 :
- Box(Precision) : 0.656
- Box(Recall) : 0.51
- mAP50 : 0.546
- mAP50-95 : 0.386
- 추론 속도 : 2.6ms
- 학습 소요 시간 : 43분 15초
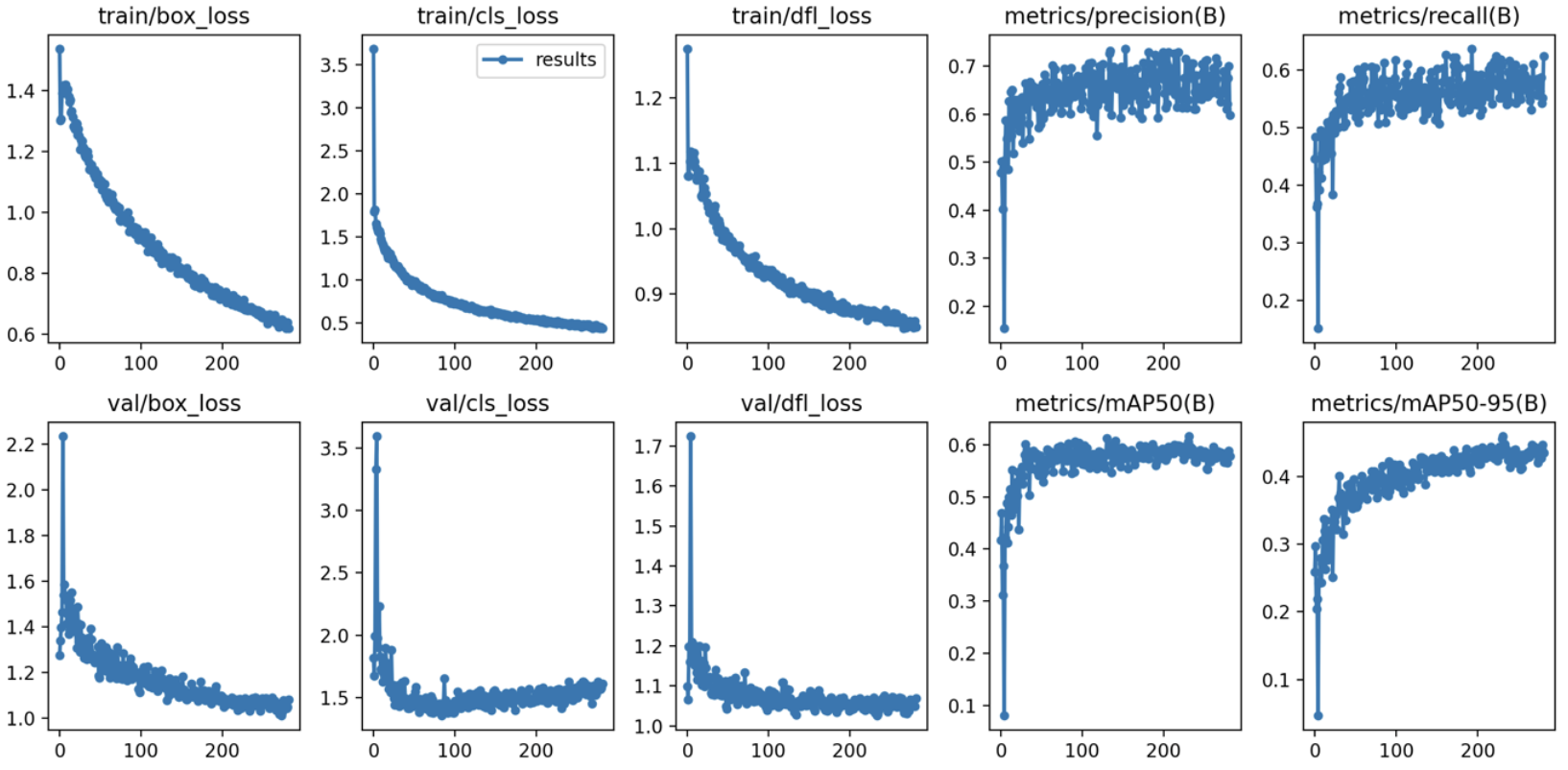
(3) 원본 이미지 300장 + 생성 이미지 600장(이미지 당 2장씩 생성)
학습 결과 :
- Box(Precision) : 0.648
- Box(Recall) : 0.593
- mAP50 : 0.611
- mAP50-95 : 0.451
- 추론 속도 : 3.0ms
- 학습 소요 시간 : 41분 35초
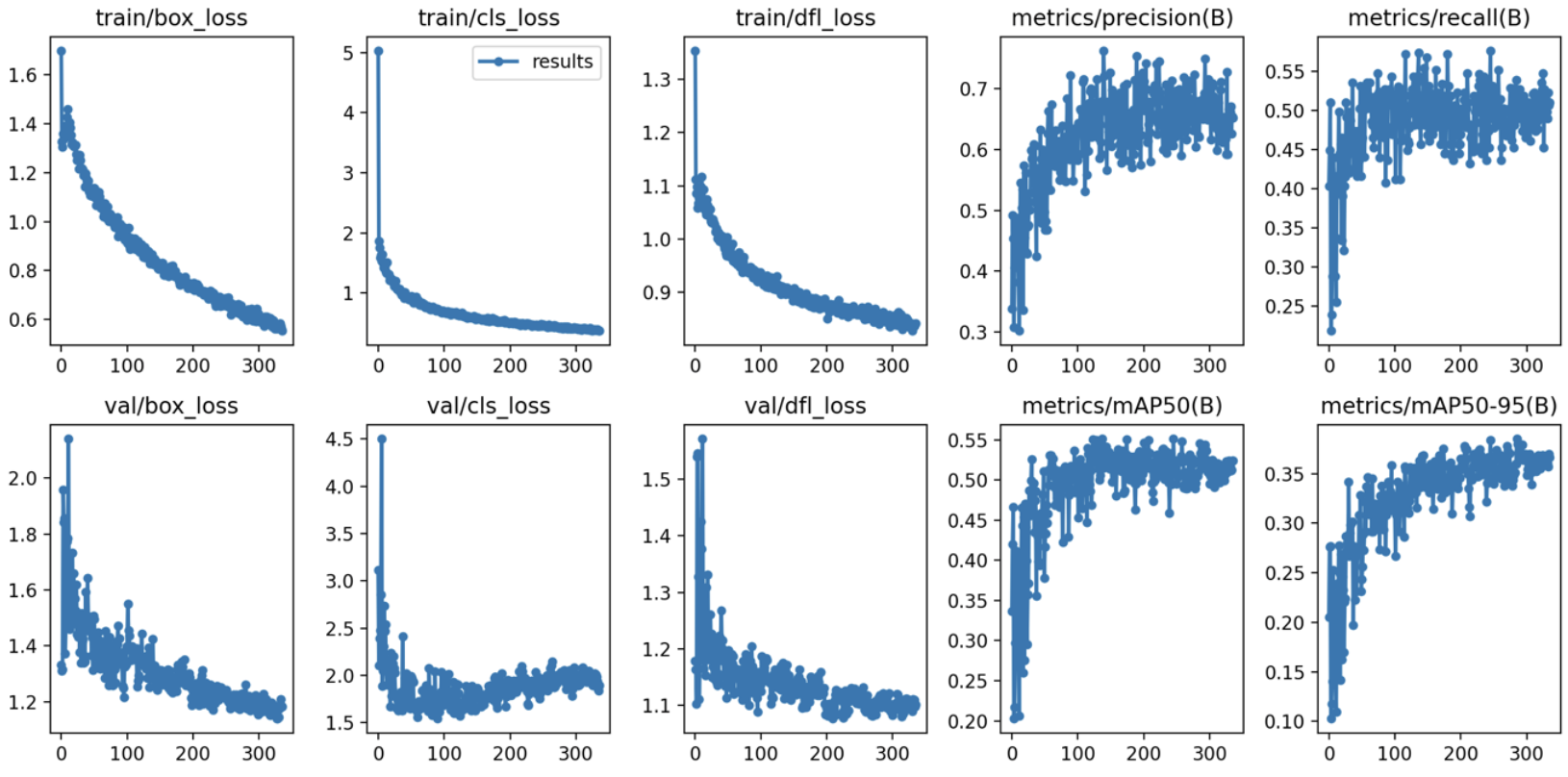
(4) 원본 이미지 300장 + 생성 이미지 900장(이미지 당 3장씩 생성)
학습 결과 :
- Box(Precision) : 0.684
- Box(Recall) : 0.579
- mAP50 : 0.616
- mAP50-95 : 0.459
- 추론 속도 : 2.9ms
- 학습 소요 시간 : 1시간 6분
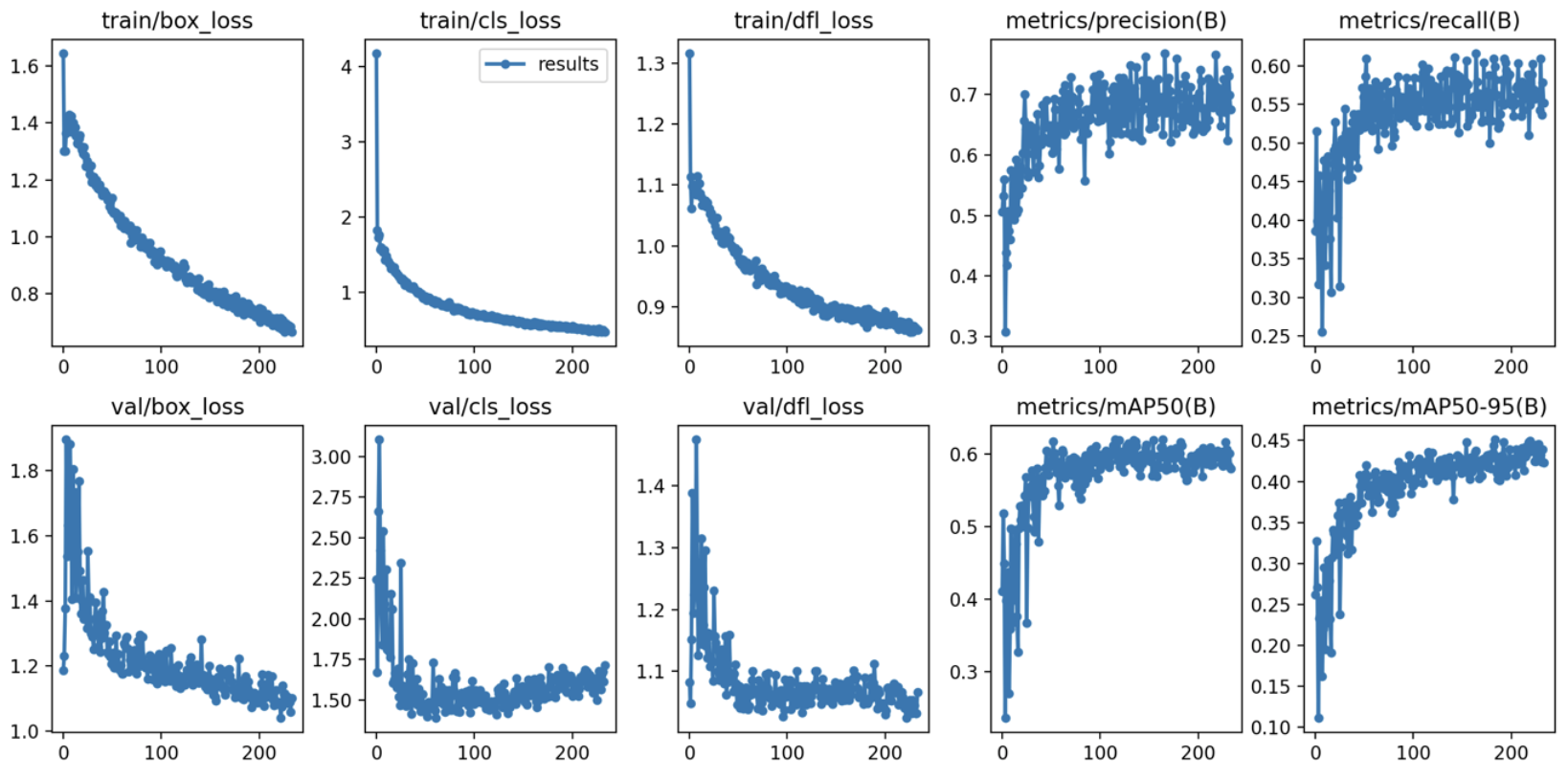
(5) 원본 이미지 300장 + 생성 이미지 1200장(이미지 당 4장씩 생성)
학습 결과 :
- Box(Precision) : 0.694
- Box(Recall) : 0.576
- mAP50 : 0.64
- mAP50-95 : 0.472
- 추론 속도 : 2.8ms
- 학습 소요 시간 : 53분 47초
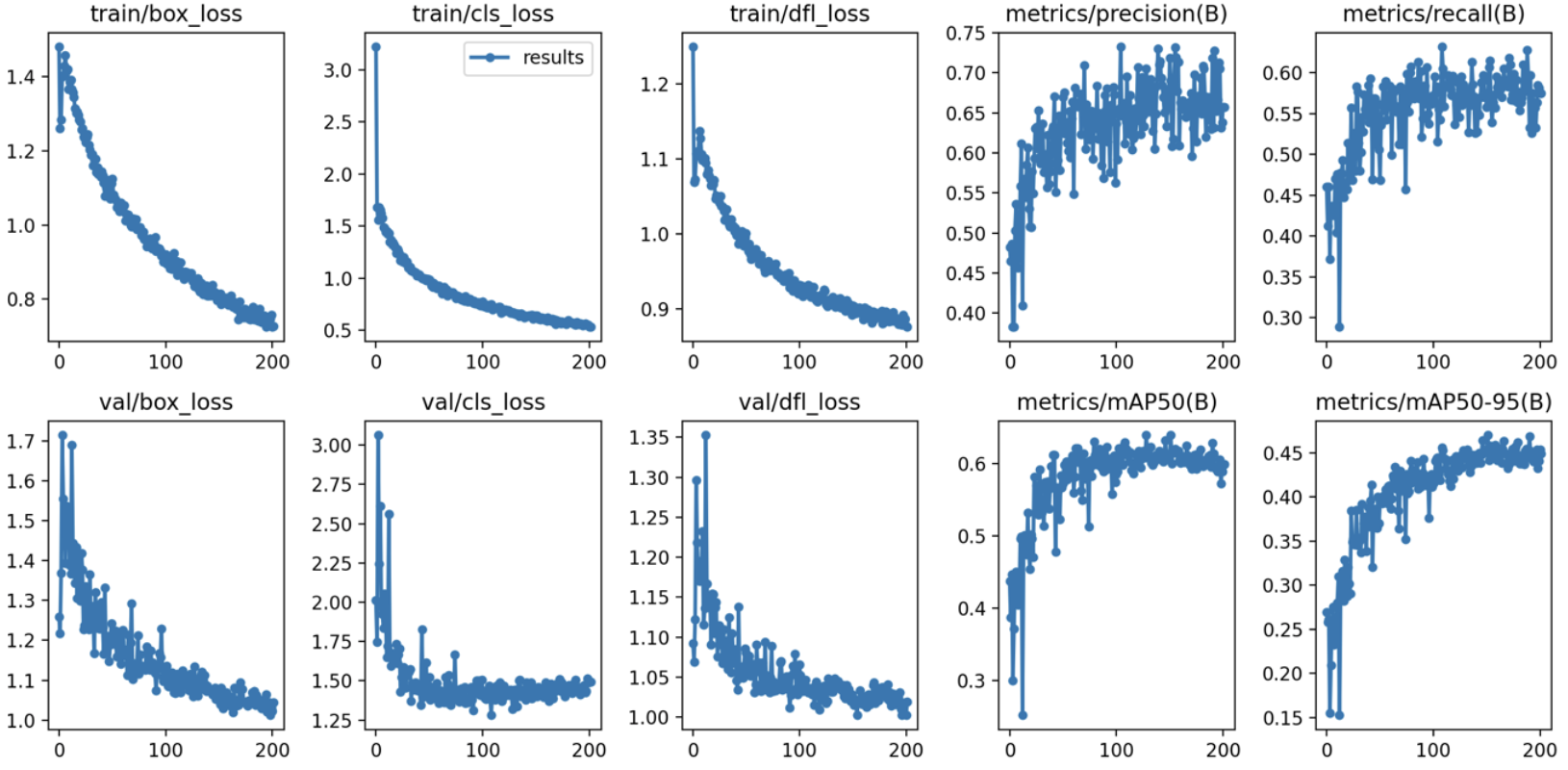
(6) 원본 이미지 300장 + 생성 이미지 1500장(이미지 당 5장씩 생성)
학습 결과 :
- Box(Precision) : 0.672
- Box(Recall) : 0.565
- mAP50 : 0.615
- mAP50-95 : 0.489
- 추론 속도 : 2.8ms
- 학습 소요 시간 : 2시간 18분 31초
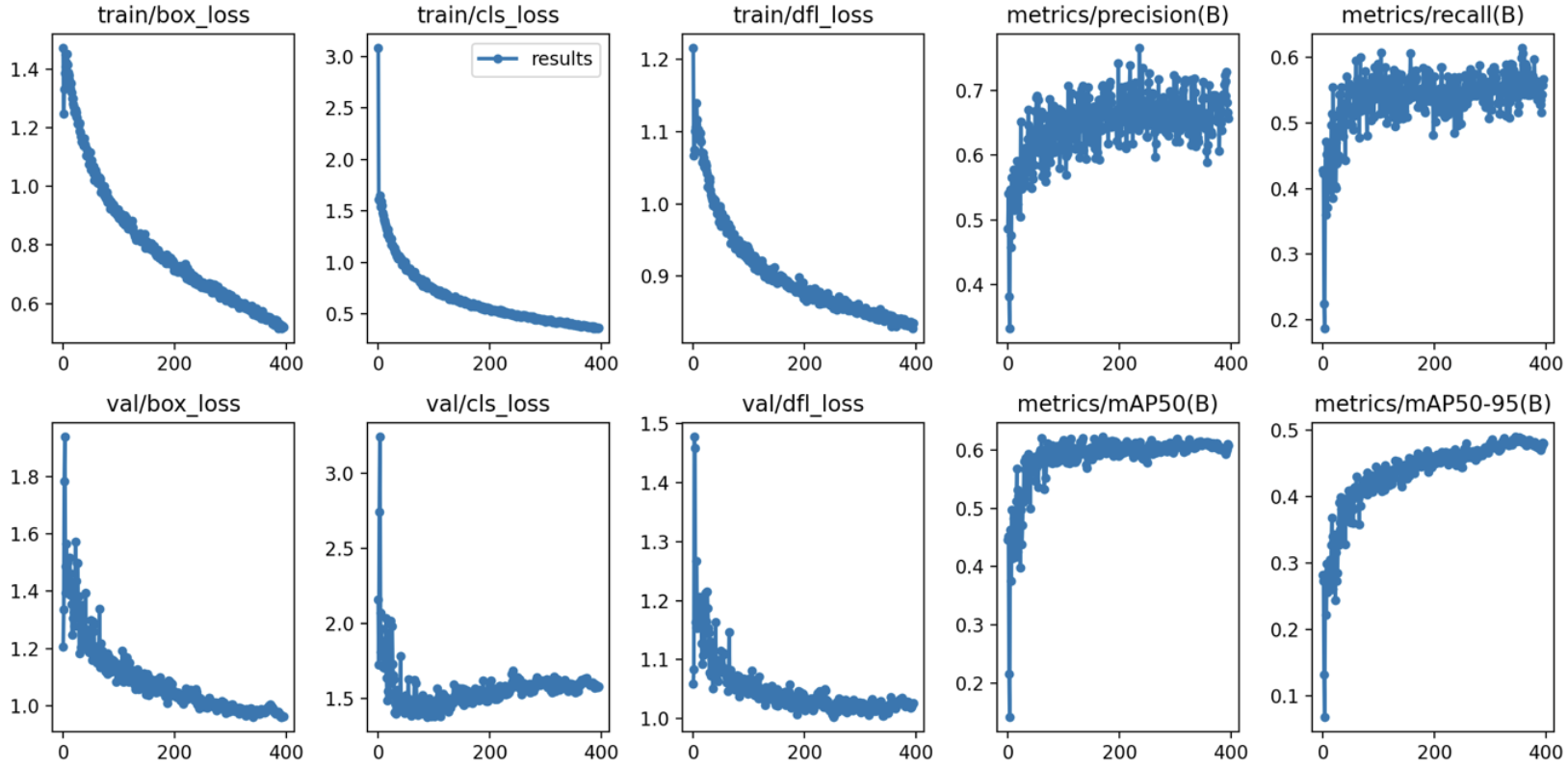
(7) 원본 이미지 300장 + 생성 이미지 1800장(이미지 당 6장씩 생성)
학습 결과 :
- Box(Precision) : 0.718
- Box(Recall) : 0.569
- mAP50 : 0.661
- mAP50-95 : 0.526
- 추론 속도 : 2.9ms
- 학습 소요 시간 : 2시간 4분 6초
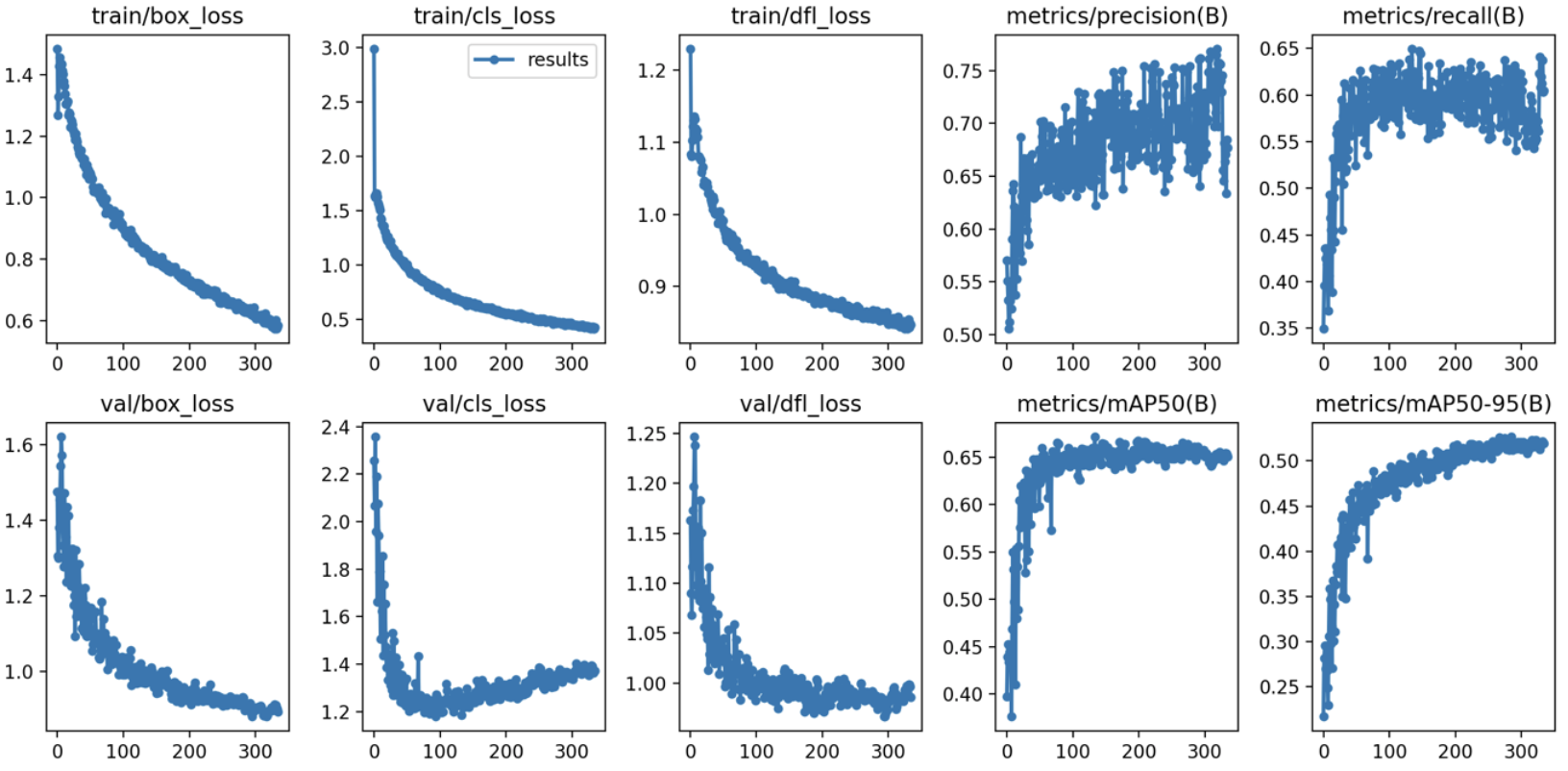
(8) 원본 이미지 300장 + 생성 이미지 2100장(이미지 당 7장씩 생성)
학습 결과 :
- Box(Precision) : 0.665
- Box(Recall) : 0.609
- mAP50 : 0.651
- mAP50-95 : 0.51
- 추론 속도 : 2.8ms
- 학습 소요 시간 : 2시간 6분 29초
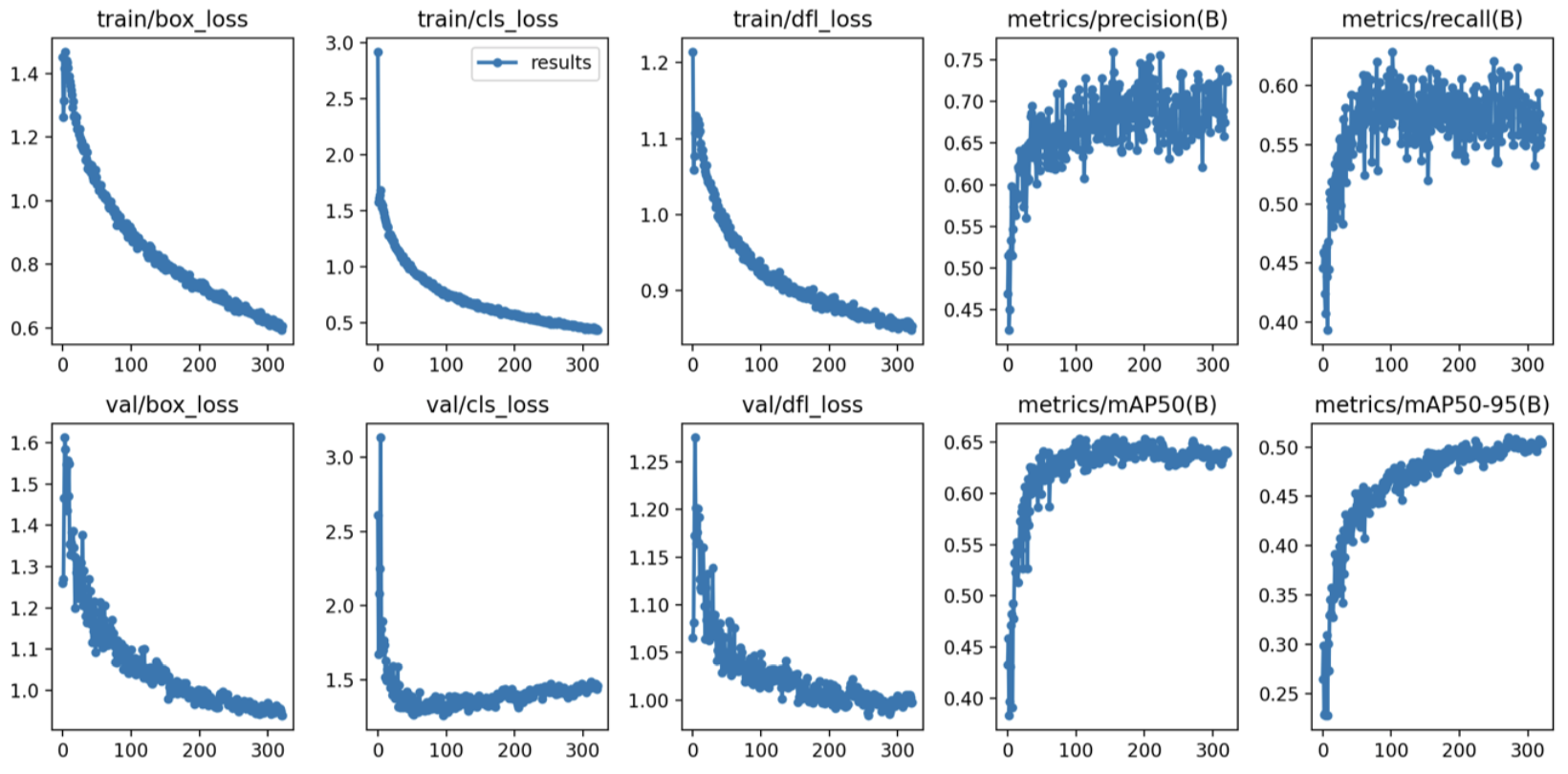
(9) 원본 이미지 300장 + 생성 이미지 2400장(이미지 당 8장씩 생성)
학습 결과 :
- Box(Precision) : 0.710
- Box(Recall) : 0.633
- mAP50 : 0.71
- mAP50-95 : 0.533
- 추론 속도 : 2.8ms
- 학습 소요 시간 : 1시간 20분 10초
이미지 생성 결과



결론
테스트 이미지
(1) vs (9) 모델 테스트 시 다음과 같은 차이를 확인할 수 있었다.

실험 결과
데이터셋 증강에 따른 결과를 비교하기 위해 다음과 같이 정리했다.
데이터셋 증강이 객체 탐지의 정확도 향상에 긍정적인 영향을 줄 수 있다고 기대할 수 있다.
이를 정확하게 입증하기 위해서는 real-world 데이터에 여러 번 테스트하여 모델이 과적합 된 것은 아닌지 확인해야 할 것이다.
또한, 다음과 같은 실험을 통해 연구를 더욱 발전시킬 수 있을 것이다.
- 원본 이미지 재수집
- 고품질 학습 데이터셋 탐색
- Object Detection SOTA 모델들로 학습 결과 비교
- Faster R-CNN, DETR, Dectron2 등
- batch size, learning rate 등을 조절하며 결과 비교
- 이미지 전처리에 따른 비교
- 계산 효율성을 위한 Resize
- Crop, Flip 등 증강 기법
