
쿠버네티스 클러스터에서 etcd는 클러스터를 운영하는 데에 필요한 중요한 정보들을 보관하는 key-value 저장소이다. etcd가 손상되고 복구할 수 없을 경우에는 클러스터를 기존 상태로 되돌리거나 다시 사용할 수 없다.
따라서 가용성이 중요한경우 etcd를 분산된 환경에 구성하는 것이 필요하며 분산된 etcd는 동일한 상태를 공유할 수 있도록 raft 합의 알고리즘을 사용한다.
Raft(뗏목) 합의 알고리즘?
분산 시스템 환경에서 모든 노드가 동일한 상태를 유지하도록 하고, 일부 노드에 결함이 생기더라도 전체 시스템이 문제 없이 동작하도록 만들기 위해 고안된 합의 알고리즘이다.
로그 복제 동작 과정
Raft 알고리즘에서 노드는 3가지 역할이 존재한다.
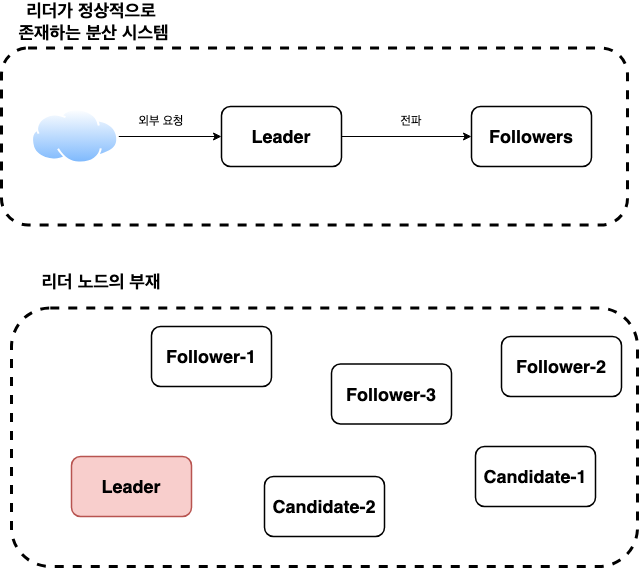
- Leader (리더): 클러스터를 대표하는 하나의 노드이다. 리더는 클러스터로 온 모든 명령의 수신 및 전파, 그리고 응답을 전담한다.
- Read-Write
- Follower (팔로워): 리더를 제외한 나머지 노드이다. 리더로부터 전파된 명령을 처리하는 역할을 담당한다.
- Read Only
- Candidate (후보): 리더가 없는 상황에서 새 리더를 정하기 위해 전환된 팔로워의 상태이다. 일정 시간 이상 리더의 안정 신호(Heart Beat)를 받지 못한 경우 팔로워는 후보자로 전환된다.
위 역할 간 상호작용을 기반으로 로그 복제 및 분산 환경에서의 노드 동기화 동작 과정을 알아보자.
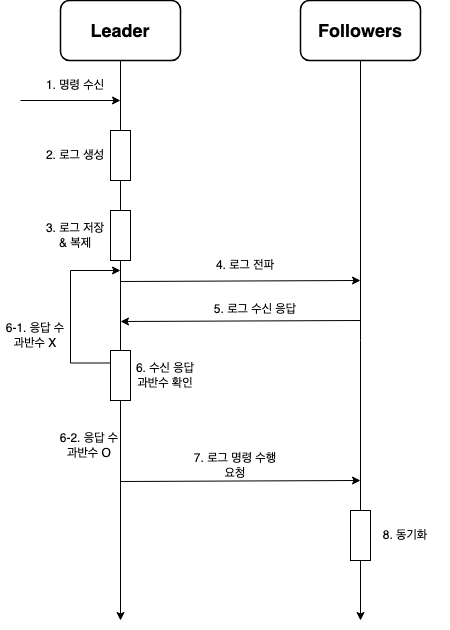
- 리더는 수신된 명령에 대한 로그(log)를 생성하여 로컬에 저장한 뒤 모든 팔로워에게 복제하여 전달한다. 각 팔로워는 전달받은 로그에 대한 응답을 다시 리더에게 보낸다.
- 리더가 수신한 정상 응답 수가 클러스터 전체 노드의 과반수에 이르면, 리더는 정상적으로 로그를 팔로워에게 전달한 것으로 판단하고 로그를 통해 전파된 명령을 클러스터의 모든 노드가 동일하게 수행하도록 명령한다.
- 최신 로그를 전체 노드가 모두 보유할 때까지 위 단계를 반복한다.
- 연결이 끊어졌다가 재개된 팔로워가 있다면 리더로부터 그 동안의 로그를 전달받아 동기화 시킨다.
리더 선출 동작 과정
리더 노드가 다운 되었을 경우 리더는 자신이 안정적인 상태라는 것을 알리는 Heart Beat(하트비트) 신호를 팔로워에게 전달하지 못하고, raft 알고리즘은 일정 시간 후에 새로운 리더를 선출한다.
- Term (임기): 리더가 선출되기 시작할 때부터 리더로서의 역할을 하는 동안까지의 시간을 나타내는 값이다.
- Election Timeout (선거 타임아웃): 팔로워 상태의 노드가 후보자로 전환되기까지 대기하는 시간으로, 일종의 타이머와 같이 작동한다. 동시에 후보자로 전환되는 것을 방지하기 위해 타임아웃 시간은 팔로워마다 랜덤하게 부여된다.
- Heart Beat (하트비트): 리더가 다른 모든 팔로워에게 일정 시간 간격으로 반복 전달하는 메시지다.
리더 노드가 다운되고 새로운 리더를 선출하는 과정을 살펴보자.
- 클러스터에 리더가 없는 상태에선 모든 노드가 팔로워 상태를 유지하며 각자에게 주어진 선거 타임아웃이 될 때까지 대기한다.
- 선거 타임아웃이 가장 먼저 끝난 노드가 후보자로 전환되고 후보자 노드는 Term이 시작된다. 후보자 노드는 즉시 자신에게 한 표를 준 뒤 다른 노드들에게 투표 요청 메시지를 전송한다.
- 투표 요청 메시지를 수신한 다른 팔로워 노드는 투표 메시지를 후보자에게 전달한다.
- 전체 노드 수의 과반에 해당하는 응답을 얻은 노드는 새로운 리더로 선출된다.
내결함성 있는 최적의 노드 개수
내결함성 (fault tolerance)는 시스템이 하드웨어 또는 소프트웨어의 오류, 장애 또는 고장에도 계속해서 정상적으로 동작하는 능력을 의미한다. 이러한 내결함성을 가지기 위해서 최적화된 노드 개수를 선정하고 관리하는 것이 중요하다.
- Quorum (정족수): 과반수를 의미한다. 전체 노드 개수가 N 이라고 하였을 때 (N+1)/2 보다 크거나 같은 최소의 자연수를 의미한다.
Raft 알고리즘에서는 전체 노드 수를 3개 이상의 홀수로 유지하는 것을 권장한다.
이유를 알아보기 위해 전체 노드수, 정족수, 허용 가능 장애 노드 수 관계를 표로 알아보자.
| 노드 수 | 정족수 | 허용 가능 장애 노드 수 |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 3 | 2 |
| 6 | 4 | 2 |
| 7 | 4 | 3 |
효율성
위 표를 보면 노드 수가 홀수일 경우에 노드 수 대비 장애 허용 노드 수의 비율이 높다. 쉽게 설명하면 아래와 같다.
- 노드 3개로 1개의 노드가 장애가 나도 괜찮은 환경을 구현할 수 있는데 노드 4개를 사용할 이유가 없다.
과반수 실패 방지
네트워크 장애와 같은 이유로 노드 간 통신이 단절될 수 있다. 이러한 상황에서 노드 개수를 짝수로 구성할 경우 과반수 투표가 이루어지지 않아 결국 리더를 선출하는 데에 실패하고 클러스터 전체 장애로 이어질 수 있다.
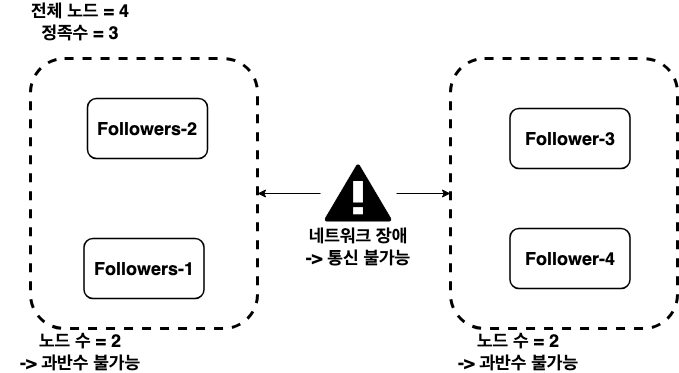
노드 개수를 홀수로 구성하는 경우에는 어떤 방법으로 노드를 분리 하더라도 리더가 선출되는 과반수를 만들어낼 수 있다.
관련 자료
분산 시스템의 내결함성을 높이는 뗏목 합의 알고리즘(Raft Consensus Algorithm)과 정족수(Quorum) 개념 알아보기
