서론

성공과 실패를 결정하는 1%의 네트워크 원리를 읽고 정리해보는 시간을 가져보려고한다.
한주에 4개의 Story를 읽으면서 인상깊은 내용 위주로 정리해보려고한다.
또한 대략적으로 이해하고있는 내용보다는 생소하고 말로 표현하기 어려웠던 내용에 대해 알기 쉽게 정리하는 연습도 같이 하려고 한다.
1-1. HTTP 리퀘스트 작성
웹 브라우저의 통신과정을 알아보자.
URL 해독
웹 브라우저는 URL을 해독한다.
http:// pium.life /home/index.html
프로토콜, 웹 서버명, 데이터 출처의 경로
http://pium.life 로 접속했을 때 서버들은 기본적으로 index.html 혹은 default.html을 바라보도록 설정해두곤 한다. http://pium.life/index.html 과 같은 의미로 다가온다는 이야기이다.
대표적인 예로 nginx의 index 옵션이 생각난다.
HTTP 프로토콜
HTTP 프로코톨이란 클라이언트와 서버가 주고받는 메시지의 내용이나 순서를 정한 것이다.
리퀘스트 메시지에는 URI 와 메소드가 존재한다.
무엇을(URI) 어떻게(메소드) 하기를 원한다고 요청하는것이 HTTP 리퀘스트 메시지라고 볼 수 있겠다.
이후 웹 서버는 응답을 반환한다. 이때 응답의 앞부분에 스테이터스 코드를 제공한다.
TMI : OPTIONS, TRACE, CONNECT 메소드는 HTTP 1.1 이상의 버전에서 사용 가능하다.
HTTP 1.0에서는 GET, POST, HEAD 메소드에 대해서만 ‘사용’ 으로 정의하고있으며 이 외에 PUT, DELETE 메소드는 부가기능으로 사양이 정의되어있다.
요즘에도 남아있을 지 모르겠지만 HTTP 1.0 통신을 기반으로 하는 개발을 진행할 경우 GET, POST로 모든 요청을 나타내는것이 좋아보인다.
CGI (Common Gateway Interface)
웹 서버 소프트웨어에서 프로그램을 호출할 때의 규칙을 정한 것이 CGI다.
CGI는 어디까지나 인터페이스이며, 특정 플랫폼에 의존하지 않고, 웹 서버 등으로부터 외부 프로그램을 호출하는 조합을 가리킨다.
HTTP 메시지 포멧
Request Message
첫 행을 Request Line이라고 칭한다.
다음은 nginx의 acces.log 파일을 확인한 예시다.
GET /bundle.js HTTP/1.1" 200 ...
POST /pet-plants HTTP/1.1" 201 …
위와 같이 Request Line 예시를 확인할 수 있다. 한 행으로 리퀘스트의 대략적인 내용을 알 수 있다.
POST 요청의 경우 다음과 같이 서버로 요청을 보내기 위한 메시지 본문이 (Request Payload) 포함되어있는 것을 알 수 있다.
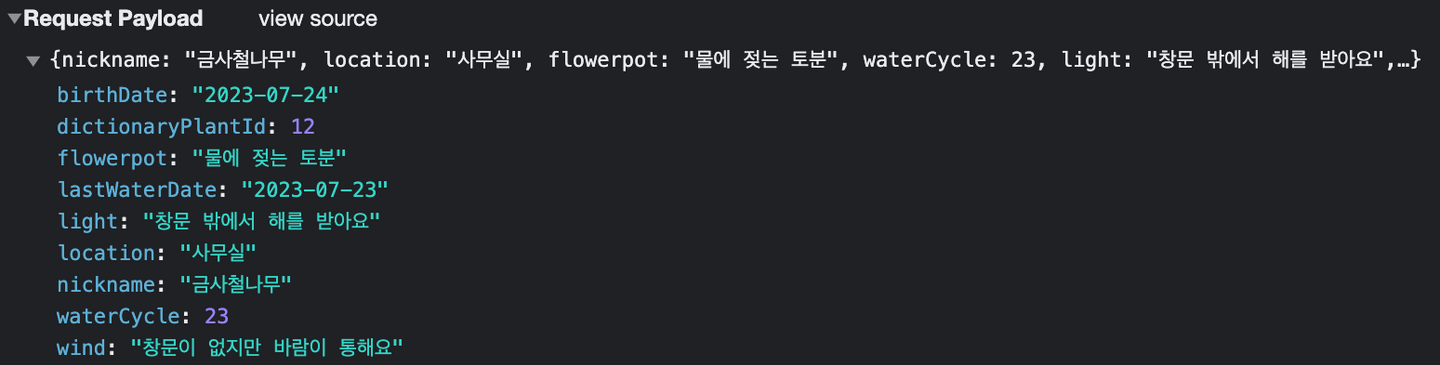
Response Message
응답 메시지에는 스테이터스 코드가 포함되어있다.
- 1xx : 처리의 경과 상황 등을 통지한다
- 2xx : 정상 종료
- 3xx : 무언가 다른 조치가 필요하다.
- 4xx : 클라이언트 측의 오류
- 5xx : 서버측의 오류
1-2. IP 주소를 DNS서버에 조회
HTTP 요청을 하면 OS는 URL 안에 쓰여있는 서버의 도메인 명에서 IP 주소를 조사한다.
1-3. DNS 서버 동작
DNS 조회 메시지
DNS를 조회하는 메시지에는 다음 세가지 정보가 포함된다.
- 이름
- 서버나 메일 호스트(junho5336@gmail.com 에서의 gmail.com)와 같은 이름이다.
- 클래스
- 인터넷 이외의 네트워크를 식별하기위해 존재했으나 현재는 인터넷 이외의 네트워크가 소멸되었다고한다.
- 클래스는 통상 인터넷을 나타내는 ‘IN’이라는 값이 된다.
- 타입
- 이름에 어떤 종류의 정보가 지원되는지 나타낸다.
위와 같이
DNS 타입
- A : 이름에 IP 주소가 지원되는 것을 나타낸다.
- MX : 이름에 메일 호스트가 지원된다.
- PTR : IP 주소에서 이름을 조사할 때 사용한다.
- CNAME : 도메인 이름에 별칭을 붙인다.
- NS : DNS 서버의 IP 주소를 등록한다.
- SOA : 도메인 자체의 속성 정보를 등록한다.
도메인 이름, 클래스, 타입, 클라이언트에 회답하는 항목을 리소스 레코드라고 부른다.
DNS 서버는 캐싱을 한다
DNS 서버는 최상위 루트 도메인으로부터 순서대로 도메인을 해석한다.
매번 루트 도메인부터 조회하는 방식은 꽤나 비효율적이기 때문에 DNS 서버는 한번 조회한 이름에 대해 캐싱을 한다. 이로 인해 보다 빠른 방식으로 도메인을 조회할 수 있다는 장점이 있다.
간혹가다 DNS Target IP를 갱신했을 때 브라우저를 껐다 켜지않으면 같은 주소로 향하는 이유가 이 때문이다.
1-4. 프로토콜 스택
프로토콜은 웹 뿐만 아니라 모든 네트워크 애플리케이션에 해당하는 내용이다.
OS 내부의 프로토콜 스택에 메시지 송신 동작을 요청할 때 Socket 라이브러리를 정해진 순서대로 호출한다.
이에 소켓의 동작 흐름에 대해 알아본다.
소켓
서버에서 데이터가 이동하는 파이프 (소켓)을 만들고 이 경로를 통해 데이터를 송, 수신한다.
소켓 통신은 다음과 같은 방식으로 진행된다.
- 소켓을 만든다
- 서버측의 소켓에 파이프를 연결한다
- 데이터를 송, 수신한다
- 파이프를 분리하고 소켓을 말소한다.
위 네가지 동작을 실행하는 것은 OS 내부의 프로토콜 스택이다.
소켓의 생성
소켓은 다음과 같은 단계로 만들어진다.
클라이언트 측에서소켓 라이브러리의 socket이라는 프로그램을 호출한다.
이후 동작은 socket 내부에 제어가 넘어가 소켓이 만들어지고 이 작업이 끝났을 때 다시 애플리케이션에 제어권이 돌아온다.
socket의 내부 동작은 2장에서 자세히 설명한다.
소켓 생성 이후 디스크립터(고유한 key값이라고 생각하면 된다)가 반환되고 애플리케이션은 이를 메모리에 기록한다.
이후 클라이언트 소켓이 서버측의 소켓에 접속하도록 프로토콜 스택에 요청한다.
Sokect 라이브러리의 connect 함수를 호출해 요청을 수행한다.
이 때 connect 함수는 디스크립터, IP 주소, 포트 번호를 필요로한다.
- 생각해보면 클라이언트에서 서버로 접속하는데 소켓 고유번호(디스크립터), 서버의 IP 주소 (목적지), 포트번호는 당연히 필요하겠다.
다시 정리하면 connect 함수를 호출하여 프로토콜 스택이 접속을 수행한다.
그리고 연결되면 프로토콜 스택은 상대측의 IP 주소나 포트번화와 같은 정보를 소켓에 기록한다.
이를 통해 데이터 송, 수신이 가능한 상태가 된다.
소켓의 데이터 송수신
Sockect 라이브러리는 write라는 함수를 통해 데이터를 송수신한다.
클라이언트가 소켓의 디스크립터와 송신 데이터를 지정하여 write 함수를 호출하면 서버와 연결되어있는 상태이므로 데이터를 서버로 즉시 송신할 수 있다.
별다른 정보 없이 디스크립터만 인자로 받으면 되기 때문에 송,수신 과정이 비교적 간편하다.
서버에 데이터를 전송하고 나면 서버는 메시지를 송신한다.
이 때 클라이언트는 수신 측에서는 read 함수를 호출하여 해당 메시지를 수신한다.
수신한 응답 메시지를 저장하기 위해 수신 버퍼라고 불리는 메모리 영역을 지정하고 여기에 서버에서 반환된 메시를 저장한다.
이때 소켓은 수신 버퍼에 메시지를 저장한 시점에서 메시지를 애플리케이션에 전달한다.
브라우저가 데이터 수신을 완료하면 송, 수신 동작이 끝난다.
이후 Socket 라이브러리의 close 함수를 호출하여 연결을 끊는다.
이 때 소켓 사이의 연결이 끊어지고 소켓도 말소된다.
HTTP 동작과 비교
HTTP 프로토콜은 1개의 데이터를 읽을 떄 마다 접속, 리퀘스트 메시지 송신, 응답 메시지 수신, 연결 끊기 라는 동작을 반복한다.
많은 데이터가 포함된 웹 페이지에서 위 과정을 여러번 반복하는 것은 비효율적이므로 한번 접속을 만들고 연결을 끊지 않으면서 복수의 요청과 응답을 주고받는 방법도 HTTP 1.1에서 사용할 수 있게 되었다.
이 때는 요청할 데이터가 없어진 상태에서 브라우저가 close 동작을 수행한다.
후기
일주일에 스토리 4개읽기 1주차 성공!
앞선 Http, DNS 통신에 대한 부분은 최대한 가볍게 정리해봤다.
소켓통신에 대한 내용은 생소해서 비교적 자세히 정리해봤다.
근데 이 책 번역체가 너무 심하다… 번역체 해석하면서 읽느라 오래걸렸다.
대략적으로 읽으면서 이 책에서 표현하는 말을 조금 필터링해서 볼 필요가 있다.
(애플리케이션은 Socket 라이브러리의 connect라는 프로그램 부품을 호출하여 이 의뢰 동작을 실행합니다.)
→ Sokect 라이브러리의 connect 함수를 호출해 요청을 수행한다.
프로그램 부품… 의뢰 동작… 구체적으로 다음과 같이 합니다… 번역체 때문에 가독성이 심각하게 떨어지는 책이다…ㅠㅠ
용어 정리
- URL : Uniform Resource Location
- URI : Uniform Resource Identifier



정리는 주노가 하고 난 이거보고 공부해야지