Spring Data Jpa
김영한님의 실전 Spring Data Jpa를 수강하고 정리한 문서 입니다. 강추! 최고최고.
인프런 김영한님 실전 스프링 데이터 JPA 링크
프로젝트 환경설정
딴거는 다 모르겠고, 기록할 부분만 기록해야겠다.
1) h2
-h2 데이터베이스 권한주기 : chmod 755 h2.sh
-데이터 베이스 파일 생성 방법 :
a. jdbc :h2~/datajpa~
b.~/datajpa.mc.db~ 파일 생성 확인
c.이후 tcp 접속
2) 스프링 데이터 jpa 설정
#application.yml
spring :
datasource: #연결할 디비의 이름
url: jdbc:h2:tcp://localhost/~/datajpa
username: sa
password:
driver-class-name : org.h2.Driver #디비 종류
jpa : #jpa 종류
hibernate:
ddl-auto : create #app 로딩 시점에 테이블 다 드랍하고 새로시작, 끝나도 그대로 남아있음
properties:
hibernate :
#show_sql : true #콘솔에 로그가 나옴
format_sql : true #이쁘게 해줌
logging.level:
org.hibernate.SQL: debug #콘솔에 남기는게 아니라 로그로 남음.
org.hibernate.type : trace #바인딩된 파라미터까지 볼 수 있스프링 부트를 통해서 복잡한 설정이 다 자동화 되어, persistence.xml 이런것도 없고 안써도됨.
3) 쿼리 파라미터 남기기
sql 로그를 보면 항상 ???로 찍히는데 다 볼 수 있게 하는 외부 라이브러리!
implementation 'com.github.gavlyukovskiy:p6spy-spring-boot-starter:1.5.7'
개발 단계에서는 편리하게 사용하되, 운영 시스템에 적용하기 위해서는 성능 테스트를 하고 사용하자.
도메인 모델
1) Member
- @Setter는 실무에서 사용하지 말고, 비즈니스 로직을 반영해서 만들자!
- @NoArgsConstructor(access=AccessLevel.PROTECTED) : 기본 생성자는 막아야 하는데, jpa에서 프록시를 만들기 위해서는 protected까지는 열어놓아야 함.
- @ToString에서 연관관계 매핑되어 있는 친구들은 제외하기.
- changeTeam()으로 양방향 연관관계 한번에 처리하기!*
@ManyToOne(fetch = FetchType.LAZY) // 항상 lazy로 처리!
@JoinColumn(name="team_id")
private Team team;
public void changeTeam(Team team) {
this.team = team;
//반대쪽의 멤버도 바꿔줘야함.
team.getMembers().add(this);
}2) Team
- Member와 Team은 양방향 연관관계로, Member.team이 외래키를 관리하는 주인, Team.members는 연관관계의 주인이 아님.
- 따라서 @mappedBy 사용하고, Team에서는 읽기만 가능하게.
Repository - 순수 jpa 기반 repository, 스프링 데이터 jpa repository
영한님 강의에서 가장 좋은건, 항상 이렇게 더 추상화 되어 있는 인터페이스를 쓰기 전에 java나 jpa로 먼저 구현을 하고, 여기서 뭐가 더 편리해졌는지를 따라갈 수 있어서 좋은것 같습니다. 빌드업이 지리심.
참고로, jpa에서 수정은 더티체킹 기능을 사용하면 됩니다. Jpa에서는 영속성 컨텍스트로 불러올 떄 그 스냅샷을 찍어놓고서 만약 이 엔티티를 변경한 다면, 트랜잭션 종료 시점에 update sql을 날려주기 때문이져. 데이터를 마치 객체 관리하듯이 쓸 수 있게 해줍니다. 리스트에서 원소 꺼내서 바꾸고 다시 넣고 그러진 않잖아여?
순수 jpa 기반 repository는 생략하겠습니다. 그냥 @Repository랑 EntityManager 써서 그대로 구현하면 됩니다. em.createQuery하면서 안에 jpql 잘 쓰면서.
공통 인터페이스
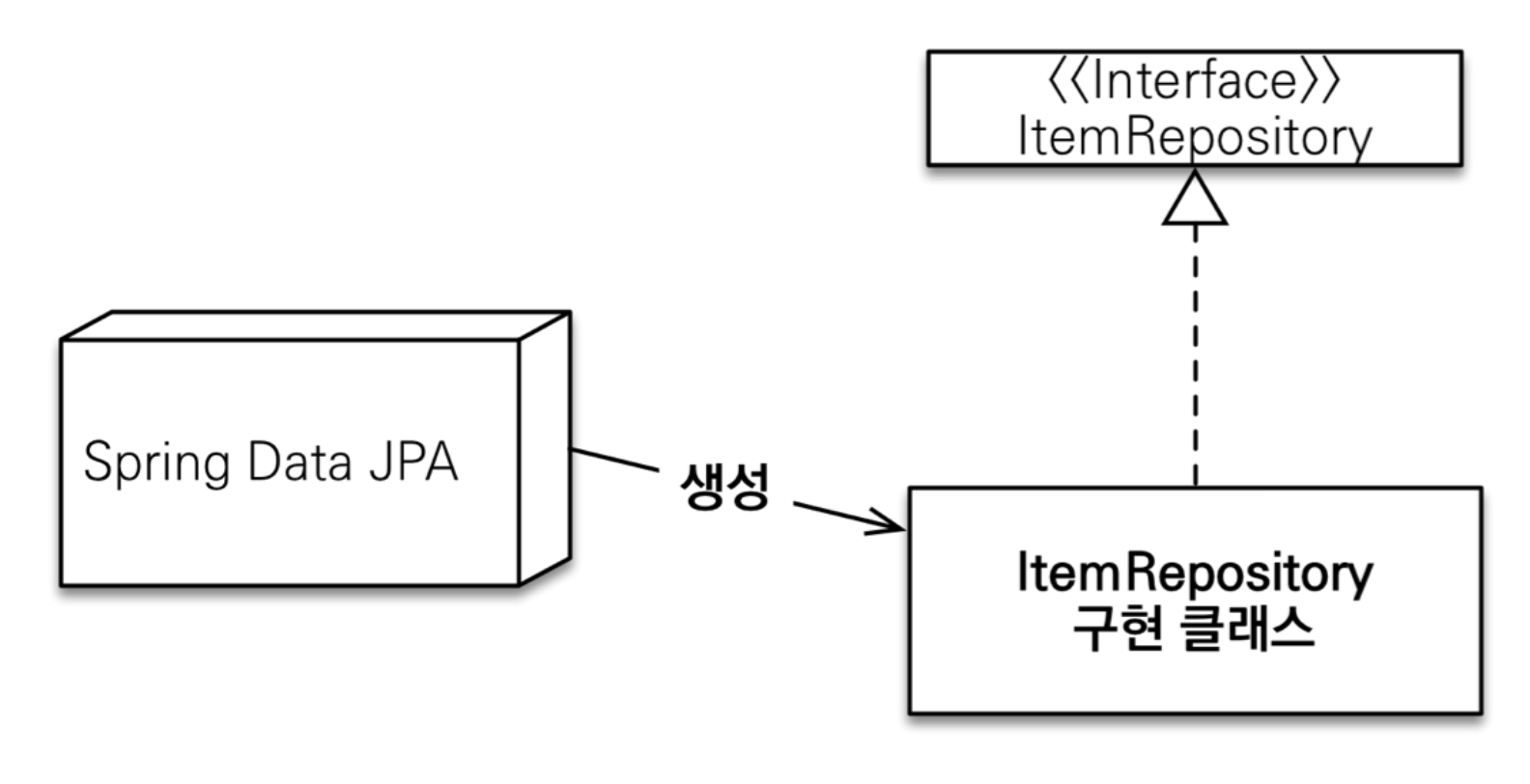
요렇게 스프링 Data Jpa에서 구현 클래스를 만들어준답니다. 우린 인터페이스만 만들고, 그걸 의존성 주입 받아서 사용하면 되져.
1) Spring Data Jpa 기반 MemberRepository
//<Type,PK>
public interface MemberRepository extends JpaRepository<Member, Long> {
}제네릭은 <엔티티 타입, 식별자 타입> 의로 설정하면 됩니다.
이러면 모든 CRUD가 테스트케이스에서 잘 돌아가는걸 볼 수 있져.
2) 주요 메서드
-save(S) : 새로운 엔티티는 저장하고, 있는 엔티티는 병합
-delete(T) : 엔티티 하나를 삭제. 내부에서 EntitiManager.remove() 호출
-findById(Id) : 엔티티 하나를 조회, 내부에서 EntitiManager.find() 호출
-getOne(Id) : 엔티티를 프록시로 조회. EntitiManager.getReference() 호출
-findAll(..) : 모든 엔티티 조회. 정렬이나 페이징 조건 제공 가능.
쿼리 메소드 기능
Spring Jpa가 제공하는 어메이징한 기능…
쿼리 메소드 기능 3가지
1) 메소드 이름으로 쿼리 생성
2) 메소드 이름으로 JPA NamedQuery 호출
3) @Query 어노테이션을 사용해서 레퍼지토리 인터페이스에 쿼리 직접 정의하기!
1. 메소드 이름으로 쿼리 생성하기.
이름과 나이를 기준으로 회원을 조회해보자
그냥 Jpa*
public List<Member> findByUsernameAndAgeGreaterThan(String username, int age) {
return em.createQuery("select m from Member m where m.username = :username and m.age >:age")
.setParameter("username",username)
.setParameter("age",age)
.getResultList();
}
스프링 데이터 JPA
public interface MemberRepository extends JpaRepository<Member,Long> {
List<Member> findByUsernameAndAgeGreaterThan(String username, int age);
}
스프링 데이터 jpa가 메서드의 이름을 분석해서 알아서 쿼리를 날려줍니다. 신기하져.*
- find…By, read…By, query…By, get....By 등등으로 사용 가능 합니다.
- count…By , exists…By, delete…By 등등.
- …에는 이제 알아서 넣어므녀 되ㅐㅂ니다.
- findFirst3, findTop3 등등도 가능!
- 더 많은 기능은 스프링 독스 참고!
그리고, 만약 엔티티의 필드명이 바뀌면 어플리케이션 실행 시점에 오류가 발생하져. 아주 큰 장점.
2. JPA NamedQuery
1) @NamedQuery 어노테이션으로 미리 정의해놓기
@Entity
@Getter @Setter @NoArgsConstructor(access = AccessLevel.PROTECTED)
@ToString(of={"id","username","age","team"})
@NamedQuery(
name = "Member.findByUsername",
query = "select m from Member m where m.username =:username"
)
@NamedEntityGraph(name = "Member.all", attributeNodes = @NamedAttributeNode("team"))
public class Member extends BaseEntity {
...
}2) jpa or 스프링 데이터 Jpa로 호출해서 사용하기
List<Member> resultList =
em.createNamedQuery("Member.findByUsername", Member.class)
.setParameter("username", username)
.getResultList();@Query(name = "Member.findByUsername")
List<Member> findByUsername(@Param("username") String username);매우 간단하져.
@Query를 생략하고, 위에서 했던 것 처럼 메서드 이름만으로도 NamedQuery 호출 가능
- 스프링 데이터 JPA는 “도메인 클래스 + . + 메서드이름)” 으로 파싱해서 네임드 쿼리를 찾아서 실행.
- 만약 실행할 네임드 쿼리가 없으면 이제 1번에서 했던 걸로 사용함.
- 사실 잘 안씁니다. 걍 @Query 쓰지.
@Query, 리퍼지토리에 메소드 쿼리 직접 정의하기
1) 메서드에 jpql 쿼리 작성하기
@Query("select m from Member m where m.username= :username and m.age = :age")
List<Member> findUser(@Param("username") String username,@Param("age") int age);
- 실행하는 메서드에 정적 쿼리를 직접 작성하기 때문에 “이름없는 Named Query”의 느낌임.
- JPA NamedQuery처럼 어플리케이션 실행 시점에 문법 오류를 발견할 수 있음!!
실무에서 가장 많이 쓰입니다.
@Query, 값, DTO 조회하기
단순히 값 하나를 조회
@Query("select m.username from Member m")
List<String> findUsernameList();@Embedded도 이 방식으로 조회할 수 있음
DTO로 직접 조회*
@Query("select new study.datajpa.repository.MemberDto(m.id,m.username,t.name" + "from Member m join m.team t")
List<MemberDto> findMemberDto();DTO로 직접 조회하려면 JPA의 new 명령어를 사용해야 함. 그리고 생성자가 맞는d dto가 있어야함.
파라미터 바인딩
앵간하면 이름 기반으로 파라미터 바인딩 합시다. 위치로 하면 순서가 바뀌면 골치아파짐.
public interface MemberRepository extends JpaRepository<Member, Long> {
@Query("select m from Member m where m.usernmae = :name")
Member findMembers(@Param("name") String username);
}@Query("select m from Member m where m.username in :names")
List<Member> findMembers(@Param("names) List<String> names);
컬렉션도 삽가능
### 반환 타입
스프링 데이터 JPA는 유연한 반환 타입을 지원한답니다.
```java
List<Member> findListByUsername(String username); //컬렉션
Member findMemberByUsername(String username); //단건
Optional<Member> findOptionalByUsername(String username); //옵셔널
조회 결과가 많거나 없으면?
- 컬렉션 : 결과가 없으면 빈 컬렉션 반환.
- 단건 조회 : 결과가 없으면 - Null / 결과가 2건 이상 - NonUniqueResultException 반환.
페이징과 정렬
: 스프링 데이터 JPA의 마법같은 페이징과 정렬..
순수 jpa로만 페이징과 정렬을 한다면?
- 나이가 10살 이상이고, 이름으로 내림차순을 하고, 페이징 조건은 한 페지당 데이터 3개, 첫 페이지만 보여줘!
public List<Member> findByPage(int age, int offset, int limit) {
return em.createQuery("select m from Member m where m.age=:age order by m.username desc",Member.class)
.setParameter("age",age)
.setFirstResult(offset) //몇번째부터?
.setMaxResults(limit) //몇명까지?
.getResultList();
}
//카운트를 가져오는데 소팅을 할 필요가 없지.
public long totalCount(int age) {
return em.createQuery("select count(m) from Member m where m.age= :age",Long.class)
.setParameter("age",age)
.getSingleResult();
}
테스트 코드
@Test
public void paging() {
memberJpaRepository.save(new Member("member1",10));
memberJpaRepository.save(new Member("member2",10));
memberJpaRepository.save(new Member("member3",10));
memberJpaRepository.save(new Member("member4",10));
memberJpaRepository.save(new Member("member5",10));
int age =10;
int offset = 1;
int limit = 3;
//when
List<Member> byPage = memberJpaRepository.findByPage(age, offset, limit);
long totalCount = memberJpaRepository.totalCount(age);
//페이지 계산 공식 적용
//total page = totalCount/size....
//마지막 페이지..
//최초 페이지....
//이런거 다 계산해야됨.
//then
assertThat(byPage.size()).isEqualTo(3);
assertThat(totalCount).isEqualTo(5);
}스프링 데이터 JPA 페이징과 정렬.
- org.springframework.data.domain.Sort 정렬 기능
- org.springframework.data.domain.Pageable 페이징 기능
특별한 반환 타입
- org.springframework.data.domain.Page : 추가 count 쿼리 결과를 포함하는 페이징
- org.springframework.data.domain.Slice : 추가 count 쿼리 없이 다음 페이지만 확인 가능 -> 내부적으로 limit+1 조회. 약간 어플리케이션 더보기 할 때 눈 속임 같은 느낌. 카운트가 필요 없음.
//repository에 이중에서 쓰면 됨.
Page<Member> findByUsername(String name, Pageable pagealbe);
// count 쿼리 알아서 나감
Slice<Member> findByUsername(String name, Pageable pageable);
//count 쿼리 안나감
List<Member> findByUsername(String name, Pageable pageable);
//count 쿼리 나감.
List<Member> findByUsername(String name,Sort sort);/*
실행 코드
*/
//when
PageRequest pageRequest = PageRequest.of(0,3,Sort.by(Sort.Direction.DESC,"username"));
Page<Member> Page = memberRepository.findByAge(10,pageRequest);
//then
List<Member> content = page.getContent(); //조회된 데이터
assertThat(content.size()).isEqualTo(3);
assertThat(page.getTotalElements()).isEqualTo(3);
....
- Pagable은 인터페이스임. 이 구현체가 PageRequest. 이거 임포트를 org.springfamework.data.domain.PageRequest로 받아야지 딴거로 받으면 안됩니다..
- PageRequest는 (현재 페이지, 조회할 데이터 수, 정렬 정보) 이렇게 넘겨주면 됩니다.
- 페이지는 0부터 시작.
count 쿼리 분리 가능. 사실 totalCount는 join이 필요 없잖아. 나는 totalCount만 가져오고 싶어.
@Query(value = "select m from Member m",
countQuery = "select count(m.usernmae) from Member m")
Page<Member> findMemberAllCountBy(Pageable pageable);페이지를 유지하면서 엔티티를 DTO로 변환하기!
Page<Member> page = memberRepository.findByAge(10,pageRequest);
Page<MemberDto> dtoPage = page.map(m -> new MemberDto(m.getId(), m.getUsername(), null));요렇게 내부를 dto로 바꿈.
페이지는 dto로 넘겨도 괜찮음.
Slice<Member> slicePage = memberRepository.findByAge(age,pageRequest);
//카운트 쿼리 안ㄴ나가고 1개만 살짝 넘어옴.벌크성 수정 쿼리
jpa를 사용한 벌크성 수정 쿼리
public int bulkAgePlus(int age) {
int resultCount = em.createQuery(
"update Member m set m.age = m.age+1" +
"where m.age >= :age")
.setParameter("age",age)
.executeUpdate(); //이걸 해줘야 업데이트 쿼리가 나감
return resultCount
}스프링 데이터 Jpa를 사용한 벌크성 수정 쿼리
@Modifying(clearAutomatically=true) //얘를 해야 executeUpdate가 나감.
@Query("update Member m set m.age = m.age+1 where m.age>= :age")
int bulkAgePlus(@Param("age") int age);- 벌크 쿼리는 이제 디비에 바로 때려 박는 거라서 정작 영속성 컨텍스트에는 이게 반영이 안될 수도 있음
- 따라서 clearAutomatically=true를 넣어 줘서 정리해줘야함.
- 이게 업데이트만 딱 하고 말면 상관 없는데 만약 다음 로직이 남아 있다면 위처럼 주의해서 써줘야 함.
@EntityGraph
만약 멤버가 팀을 참조하고 있고, 지연로딩 관계라면?
List<Member> members = memberRepository.findAll();
for(Member member : members) {
System.out.println("member.getTeam().getName()")
}
이렇게 했을 때, 분명 멤버를 찾기 위해 쿼리가 한번 나가고 (findAll) (1)
루프를 돌면서 각각의 멤버의 팀 프록시를 찾기 위한 커리가 한번씩 더나감 (N)
=> N+1의 문제.
**따라서, 연관된 엔티티를 한번에 조회하려면 fetch join을 사용해야 한다!**
```java
//jpql fetch join
@Query("select m from Member m left join fetch m.team")
List<Member> findMemberFetchJoin();스프링 데이터 JPA는 @EntityGraph 기능을 지원, 편리하게 사용할 수 있도록 해줌
@Override //공통 메서드 오버라이드
@EntityGraph(attributePaths = {"team"})
List<Member> findAll();
//Jpql + 엔티티그래프
@EntityGraph(attributePaths = {"team"})
@Query("select m from Member m")
List<Member> findMemberEntityGraph();
//메서드 이름으
@EntityGraph(attributePaths = {"team"})
List<Member> findByUsername(@Param("username") String username)
- 쉽게 페치 조인을 하게 해줌!
#### NamedEntityGraph
```java
@NamedEntityGraph(name = "Member.all", attributeNodes = @NamedAttributeNode("team"))
@Entity
public class Member {
}
@EntityGraph("Member.all")
@Query)("select m from Member m")
List<Member> findMemberByEntityGraph();
//근데 굳이?
JPA HInt & Lock
JPA의 구현체에게 힌트를 제공하자.
쿼리 힌트
@QueryHints(value = @QueryHint(name = "org.hibernate.readOnly",value = "true"))
Member findreadOnlyByUsername(String username);
- 영속성 컨텍스트에서 스냅샷을 안만들어서, 변경이 안된다고 가정하고 다 무시해버림!
@QueryHints(value = {@QueryHint(name = "org.hibernate.readOnly", value = "true)},forCounting = true)
Page<Member> findByUsername(String name, Pagable pageable);반환 타입이 page이면 count 쿼리도 쿼리 힌트 적용.
사실 이런거 한다고 성능 최적화가 되는게 아니라, 진짜 중요하고 트래픽이 많은 api 몇개에만 넣는거지, 중요한건 복잡한 쿼리가 아님.
Lock
Jpa lock 참조
확장기능
사용자 정의 리포지토리 구현
만약, 인터페이스의 메서드를 직접 구현하고 싶다면..?
- 가령 Querydsl을 쓴다거나..?
- 근데 그렇다고 스프링이 주는 구현체를 안쓰고 직접 구현을 한다면 구현할게 너어어어어어어엉어어어엉무 많음
- 그럴 때는?
1) 사용자 정의 인터페이스 만들기
public interface MemberRepositoryCustom {
//내가 추가 할 메서드
List<Member> findMemberCustom();
}
이름은 맘대로 해도 상관없음.
2) 사용자 정의 인터페이스 구현 클래스 만들기
@RequiredArgsConstructor
public class MemberRepositoryImpl implements MemberRepositoryCustom {
private final EntityManager em;
@Override
public List<Member> findMemberCustom() {
return em.createQuery("select m from Member m")
.getResultList();
}
}- MemberRepository + impl이라고 해야 스프링 데이터가 jpa가 이걸 나중에 잘 q빈으로 조립해줌
3) 사용자 정의 인터페이스 상속
public interface MemberRepository extends JpaRepository<Member,Long> , MemberRepositoryCustom{
}
이렇게 하면 스프링 데이터 JPA가 잘 붙여줌. 이게 인터페이스가 다른 인터페이스 상속은 오케이 그럴수 있는데 막 그 구현체를 붙여주는게 이상하지만, Java가 해주는게 아니라 스프링 데이터가 해주는거라서 굳.
최신 버전에서는 사용자 정의 인터페이스 구현체를 사용자정의 인터페이스이름 + impl로 해도 된다고 합니다.
Auditing
- 등록일 수정일 등록자 수정자를 모든 엔티티에 다 쓰고 싶다면?
//그냥 jpa
@MappedSupperclass
@Getter
public class BaseEntityu {
@Column(updatable=false)
private LocalDateTime createdDate;
private LocalDateTime updatedDate;
@PrePersist // persist 전 이벤트
public void prePersist() {
LocalDateTime now = LocalDatetime.now();
this.createdDate = now;
this.updatedDate = now;
}
@PreUpdate
public void preUpdate() {
LocalDateTime now = LocalDatetime.now();
this.updatedDate = now;
}
//하고 다른 엔티티가 이걸 상속스프링 데이터 JPA Auditing
- @EnableJpaAuditing : 스프링 부트 설정 클래스에 적용해야함
- @EntityListeners(AuditingEntityListener.class) : 엔티티에 적용해야
@EntityListeners(AuditingEntityListener.class)
@MappedSupperclass
@Getter
public class BaseTimeEntity {
@CreatedDate
@Column(updatable = false)
private LocalDatetime createdDate;
@LastModifiedDate
private LocalDateTime lastModifiedDate;
}
`java
@EntityListeners(AuditingEntityListener.class)
@MappedSupperclass
@Getter
public class BaseEntity extends BaseTimeEntity {
@CreatedBy
@Column(updatable = false)
private String createdBy;
@LastModifiedBy
private String lastModifiedBy;
}
이 두개를 잘 섞어서 쓰면 됨. 어떤 엔티티는 수정자가 필요할 수도 있고 어떤 엔티티는 아닐 수도 있으니까.
- 이제 등록자, 수정자를 처리해주는 AuditorAware를 스프링 빈으로 등록.
@Bean
public AuditorAware<String> auditorProvider() {
return () -> Optional.of(UUID.randomUUID().toString());
}
//랜덤으로 넣는 코드 실제는 세션 정보나 스프링 시큐리티 로그인 정보에서 아이디를 받음.

좋은 내용 잘 보고 갑니다!