🧩 실험 배경
지난번 포스트에서 fetch join이 오히려 성능을 떨어트리는 원인을 찾아봤습니다. 이번 포스트에서는 해당 문제점을 해결하여 실질적인 성능향상을 이뤘던 내용을 정리해보려합니다.
페치조인이 성능을 떨어트린 이유는 아래 포스트 참고
https://velog.io/@junho_99/JPA-Fetch-Join-%EC%BF%BC%EB%A6%AC-%EB%B6%84%EC%84%9D%EC%9C%BC%EB%A1%9C-%EC%84%B1%EB%8A%A5-%EB%B9%84%EA%B5%90
문제를 요약하면
1. 페치조인으로 유저와 해당유저 게시글을 한번에 가져옴
2. DISTINCT + 정렬 + 페이징 등을 페치조인 쿼리와 함께 사용하면 조인으로 늘어난 row에 대한 계산을 진행해야하므로 성능 저하됨
3. 1:N 관계에서의 페치조인은 row를 N개만큼 중복생성함
⚙️ 초기 실험
위의 문제들을 해결한뒤에
페치조인 사용 전 vs 후 성능 비교를 시도했지만, 성능 차이가 거의 없었습니다.
📌 원인
- 팔로우한 유저 수가 1명뿐이었기 때문!
- 이로 인해 쿼리 횟수가 적고, N+1 문제 체감이 어려웠습니다.
📈 실험 조건 확장
✅ 실험 설정
- 테스트 유저(ID=30000~50000)가 각각 200명(211~400)을 팔로우
- 팔로우한 유저마다 게시글 데이터 4개 삽입
- 각 게시글마다 미디어 파일 데이터 2개 삽입
✅ 테스트 환경
- 동시 접속 유저: 약 2만 명
- 각 유저의 팔로잉 수: 200명
- 각 유저당 게시글 수: 4개
- 각 게시글당 미디어파일 수 2개
🚀 본격 성능 실험
1. User + Post 페치조인만 사용
Post ↔ MediaFile은 Lazy 로딩으로 개별 조회 → N+1 발생- ✅ 성능 개선 일부 확인
2. User + Post는 페치조인
- Post + MediaFile은 IN 절 기반 일괄 조회
MediaFile조회 시WHERE post_id IN (...)사용- 중복 row 없이 메모리에서 그룹핑 후 수동 주입
- ✅ 가장 큰 성능 향상 확인!
3. 모든 관계를 Fetch Join으로 처리
Post ↔ MediaFile도 Fetch Join- 데이터가 많아질수록 row 수 폭증 → 정렬 및 페이징 성능 감소
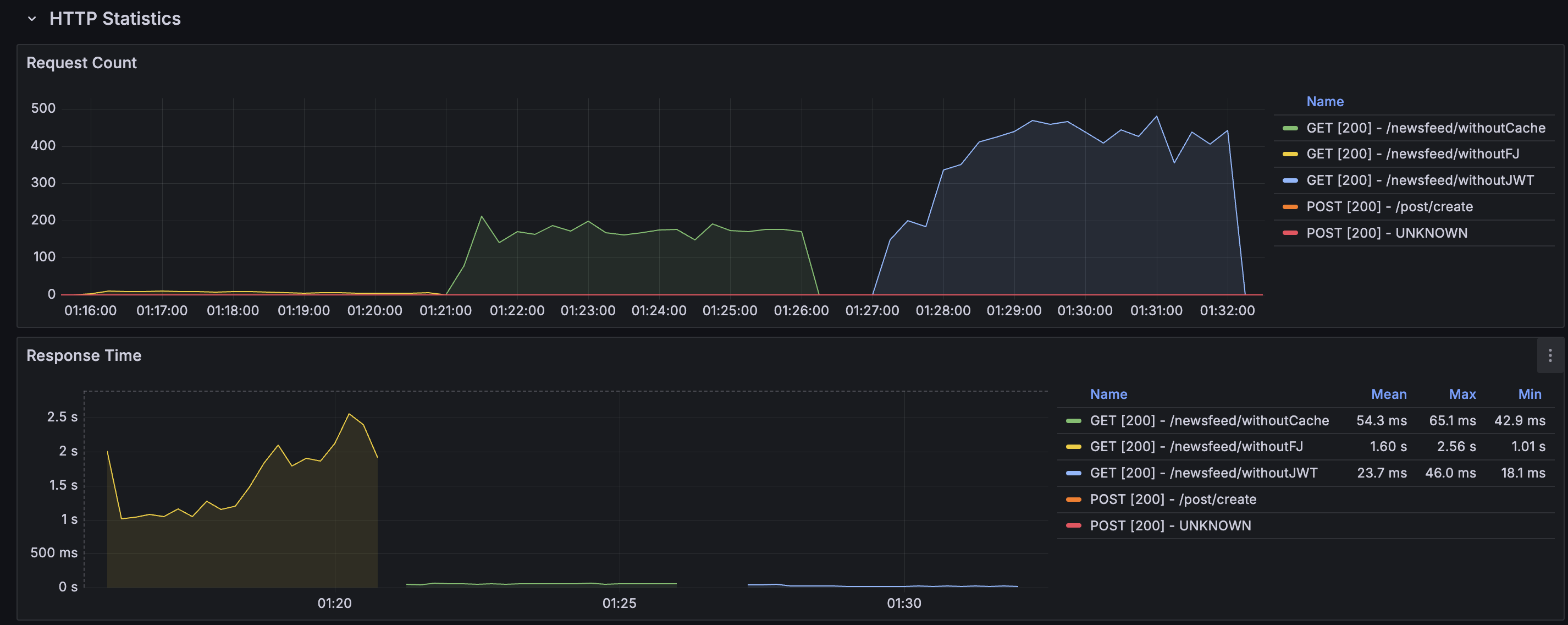
아래의 그래프는 왼쪽부터
쿼리최적화X ----------- 페치조인+IN절 사용 ------- 캐쉬까지 적용
P50, P95, P99 성능지표
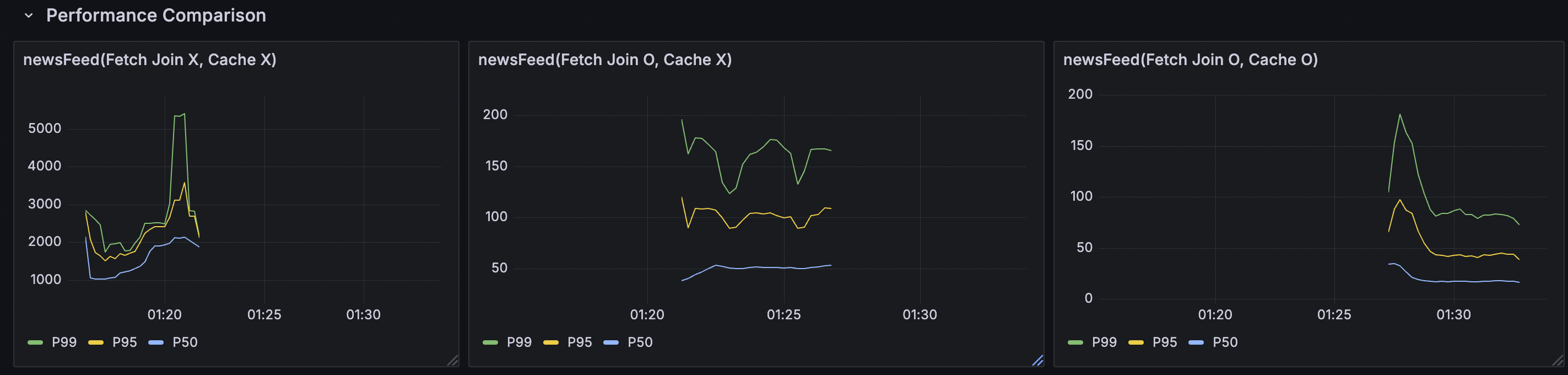
페치조인을 사용했을때와 사용하지 않았을때 성능차이가 거의 20~30배가 났습니다.
nGrinder 부하테스트 결과
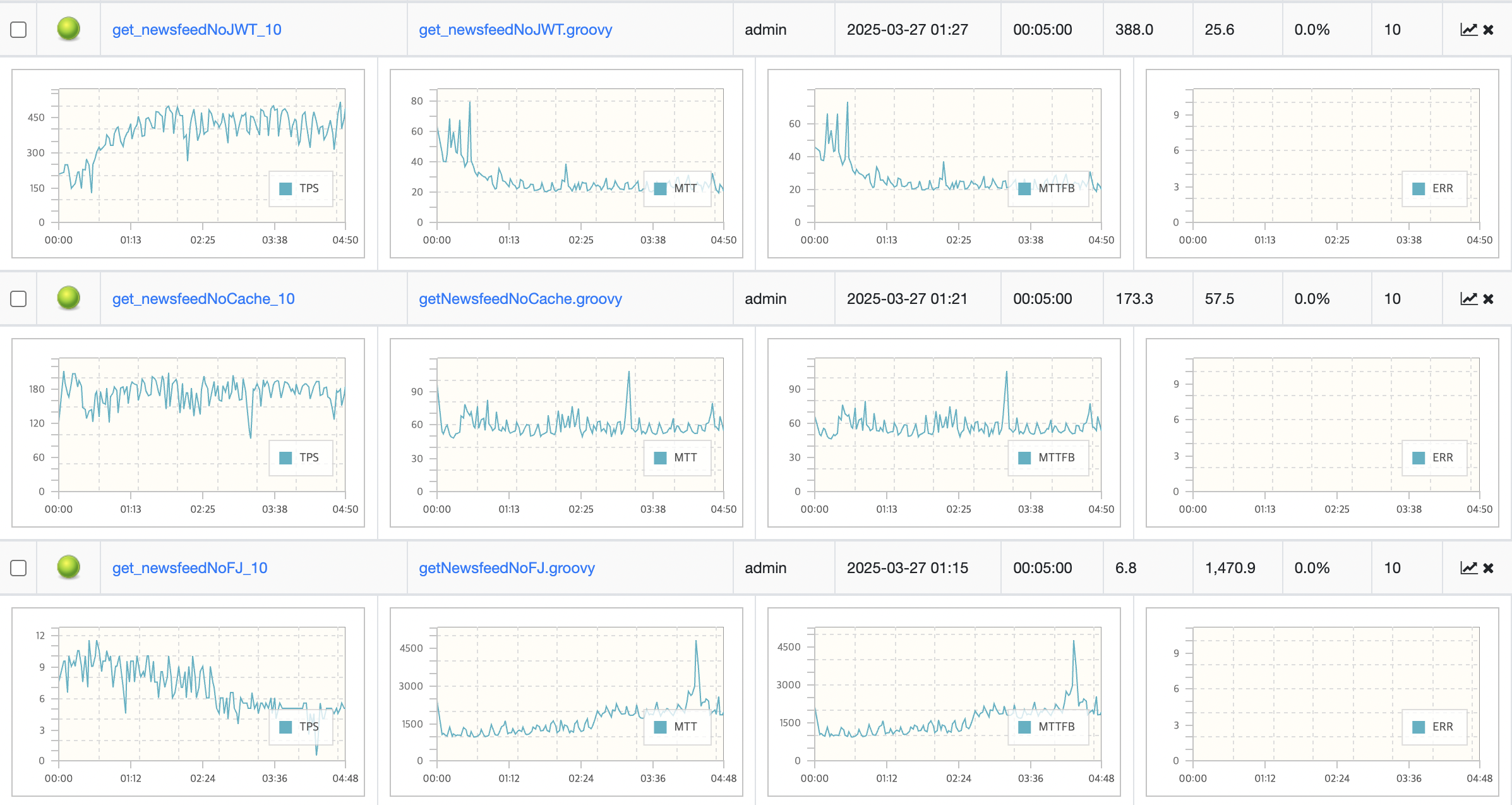
- 캐쉬까지 적용한 메서드는 시간이 지날수록 캐쉬에 값들이 저장되고 Cache hit 비율이 증가하면서 TPS가 점점 증가하여 400까지 올라갔습니다.
🧠 결론
| 전략 | 장점 | 단점 |
|---|---|---|
| Fetch Join | 직관적이고 한 쿼리로 해결 | 데이터가 많으면 row 폭증 |
| IN 절 | 대량 데이터, 정렬/페이징에 유리 | 코드가 조금 복잡, 쿼리 2번 |
✅ 최종 전략
User ↔ Post는 Fetch JoinPost ↔ MediaFile은 IN 절 기반 조회 + 메모리에서 주입
💡 학습 포인트
- 단순히 "페치조인이 좋다"는 틀렸다!
- 데이터 양, 정렬, 페이징 여부에 따라 최적 전략은 달라진다.
- 직접 부하 테스트하고, 실행 계획(Execution Plan)을 분석하며 얻은 실전 지식입니다. 💪

공부한 내용 정리하고 복습하는 블로그