참고 - https://aws.amazon.com/ko/premiumsupport/knowledge-center/athena-analyze-access-logs/
Apache Log 분석 - https://docs.aws.amazon.com/ko_kr/athena/latest/ug/querying-apache-logs.html
S3 Bucket Log 분석 - https://aws.amazon.com/ko/premiumsupport/knowledge-center/analyze-logs-athena/
참고2 - https://inpa.tistory.com/entry/AWS-%F0%9F%93%9A-Athena%EB%A1%9C-ELBALB-%EB%A1%9C%EA%B7%B8-%EA%B0%84%ED%8E%B8%ED%95%98%EA%B2%8C-%EB%B6%84%EC%84%9D%ED%95%98%EA%B8%B0
regax Test - https://rubular.com/r/tjUt3Awgg4/
IAM 생성
- console.aws.amazon/iam 접속 후 User 창으로 이동

- “사용자 추가” 클릭
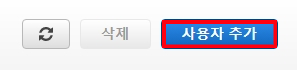
- "사용자 이름”과 암호 방식 엑세스 체크
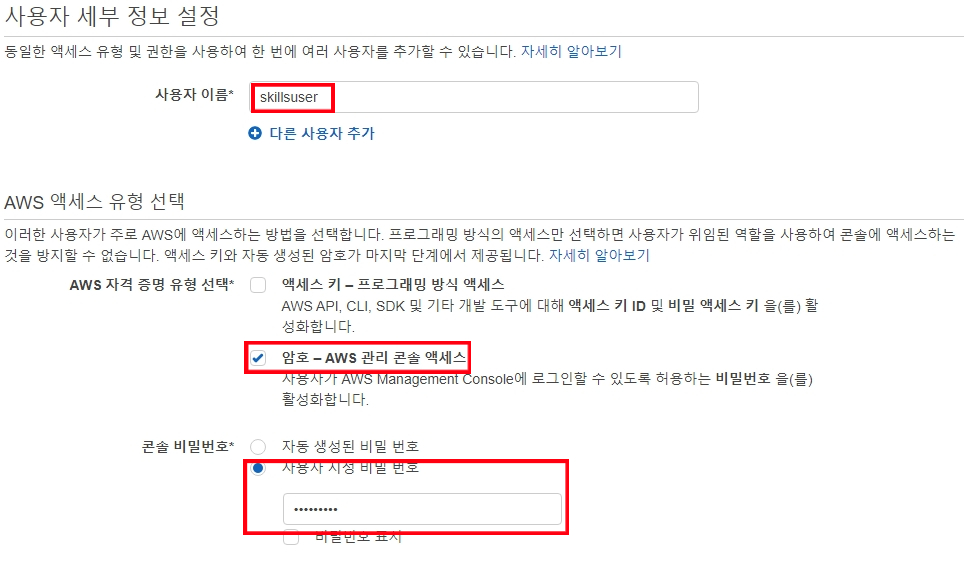
- 다음: 권한
- 기존 정책 연결 → AdministratorAccess 연결
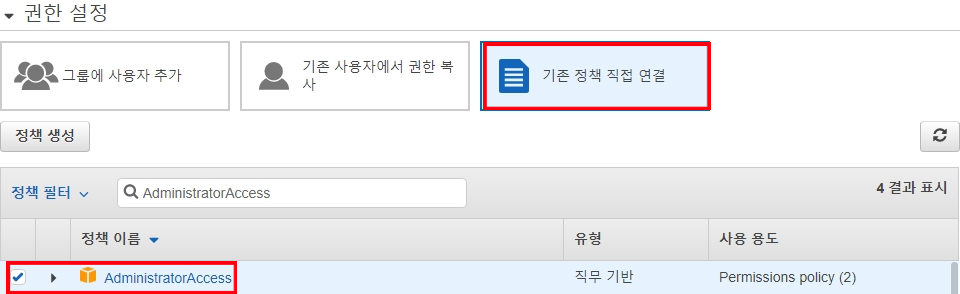
- 다음: 태그
- 다음: 검토
- 사용자 만들기
- 접속하기

S3 Bucket Create(ALB Log Data Bucket)
- Bucket을 하나 생성해주겠습니다. (console.aws.amazon.com/s3)
- 버킷 만들기 클릭

- Name 입력
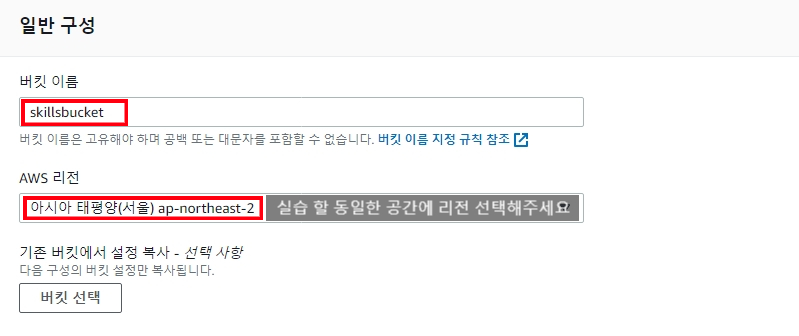
- 버킷 만들기
- Log File Upload (저는 “ALB”에 대한 Log file을 업로드해주겠습니다)

압축을 풀어서 업로드 해줍니다.
Athena
- Athena에 접속하겠습니다. (console.aws.amazon.com/athena)
- 쿼리 편집기 부분으로 이동하겠습니다
Console 화면
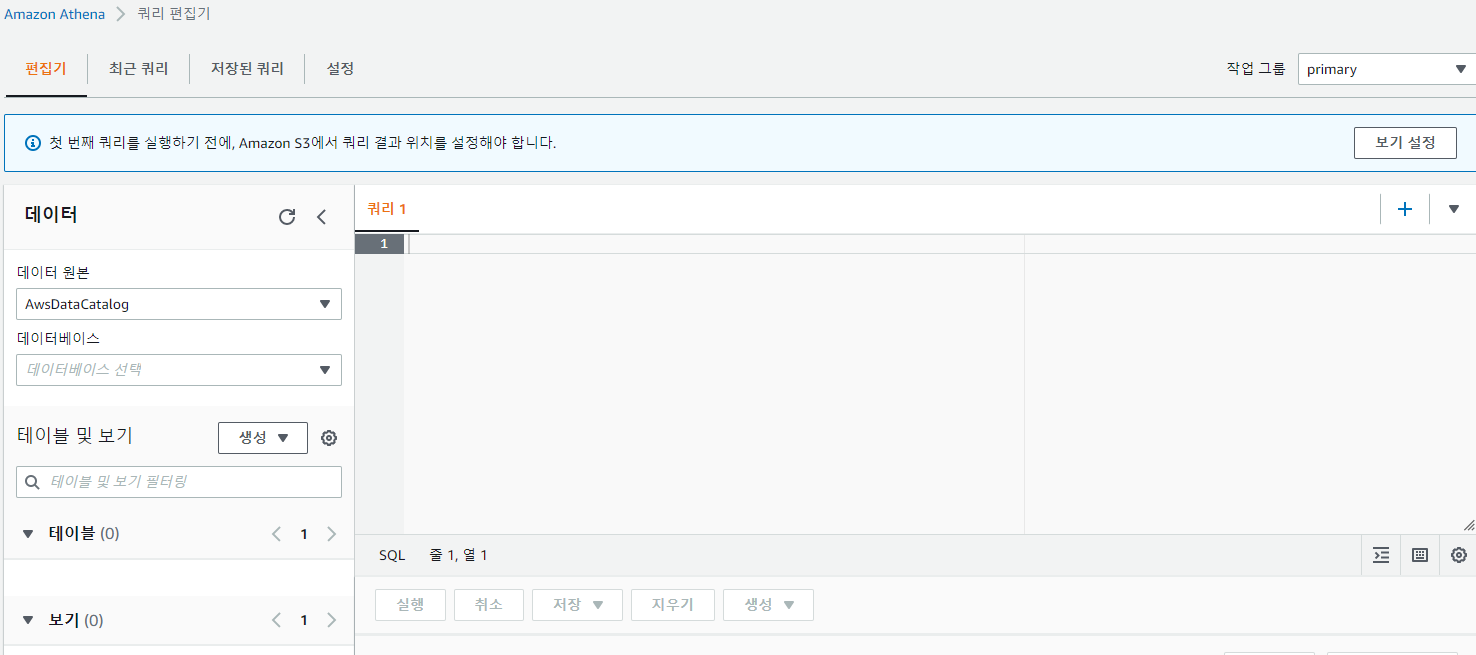
비어있는 것을 확인할 수 있습니다. 그야 당연히 아무것도 안해줬기 때문이죠. 이제 SQL 용어를 이용하면서 시작하겠습니다.
- S3에서 쿼리 결과 위치를 설정해주겠습니다. 이 과정은 쿼리 결과를 위해 해주는 과정입니다.
3.1 보기 설정 클릭

3.2 관리 클릭
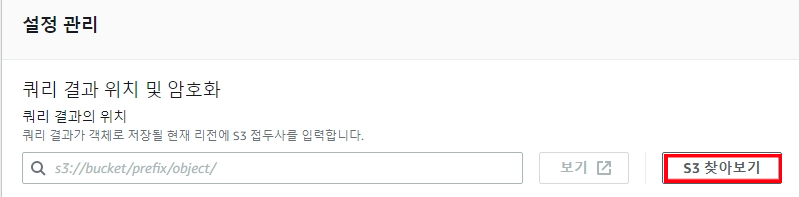
3.3 S3 찾아보기 클릭
3.4 생성한 버킷 선택한 후 선택 클릭해줍니다.
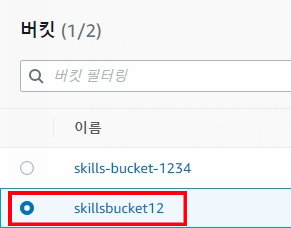
3.5 저장
3.6 편집기로 다시 이동하겠습니다. 이 부분에서 SQL 언어를 실행할 수 있습니다.
- Database 생성해주겠습니다.
CREATE DATABASE skillsdatabase;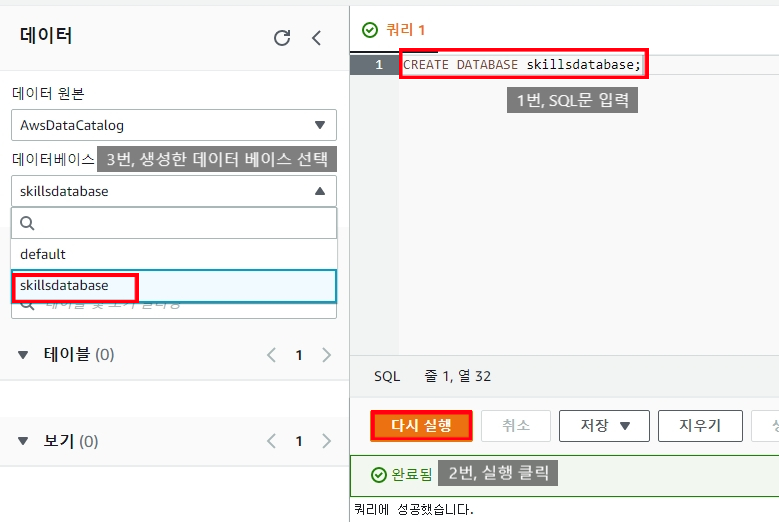
5. Table 생성해주겠습니다. 아래 SQL 문을 쿼리 창에 넣은 다음 실행해주겠습니다.
CREATE EXTERNAL TABLE IF NOT EXISTS alb_logs (
type string,
time string,
elb string,
client_ip string,
client_port int,
target_ip string,
target_port int,
request_processing_time double,
target_processing_time double,
response_processing_time double,
elb_status_code int,
target_status_code string,
received_bytes bigint,
sent_bytes bigint,
request_verb string,
request_url string,
request_proto string,
user_agent string,
ssl_cipher string,
ssl_protocol string,
target_group_arn string,
trace_id string,
domain_name string,
chosen_cert_arn string,
matched_rule_priority string,
request_creation_time string,
actions_executed string,
redirect_url string,
lambda_error_reason string,
target_port_list string,
target_status_code_list string,
classification string,
classification_reason string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'input.regex' =
'([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) (.*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-_]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^ ]*)\" \"([^\s]+?)\" \"([^\s]+)\" \"([^ ]*)\" \"([^ ]*)\"')
LOCATION 's3://your-alb-logs-directory/' #이 부분이 매우 중요하다. Log 파일에 경로(위치)를 말한다.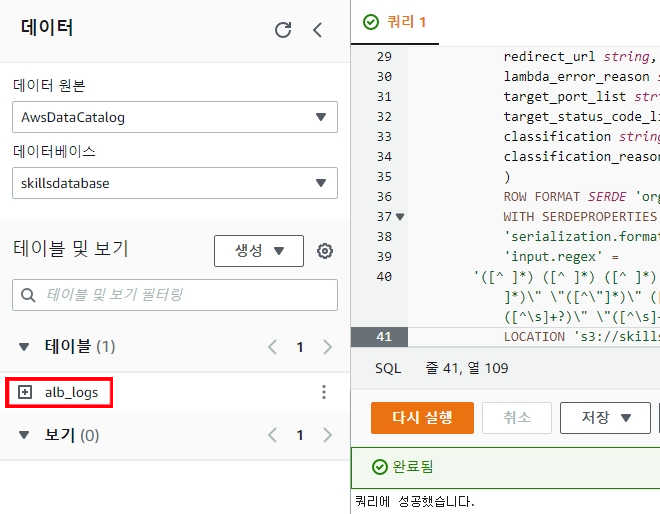
6. 데이터 쿼리 + 버튼을 눌러 쿼리 창을 하나 생성 후 그 공간에서 데이터를 쿼리하겠습니다.
7. Data Query 하기
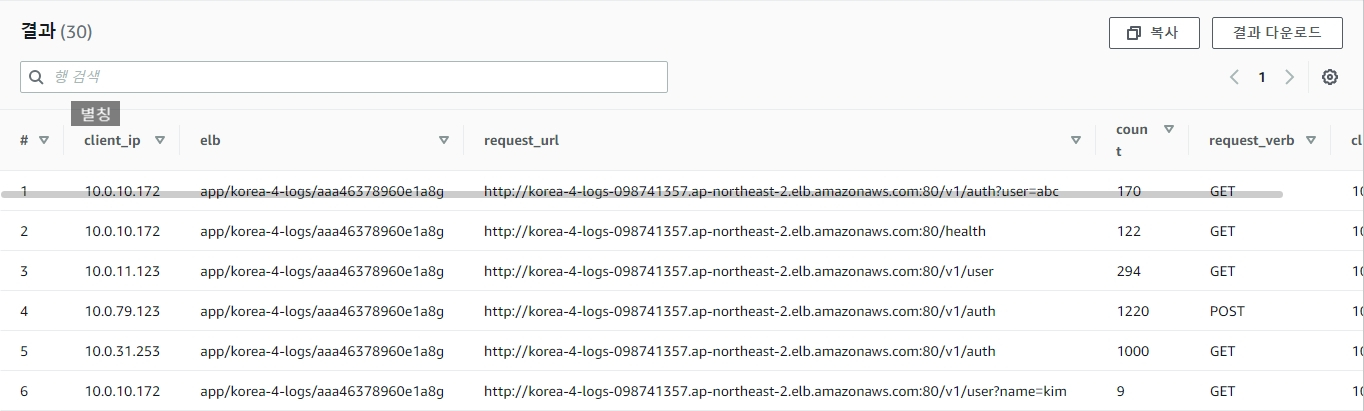
#별칭을 사용해서 출력을 해주고, GROUP BY를 사용해 동일한 데이터를 그룹으로 정렬했습니다.
SELECT client_ip, elb, request_url, COUNT(request_verb) AS
count,
request_verb,
client_ip
FROM alb_logs
GROUP BY request_verb, client_ip, elb, request_url결과
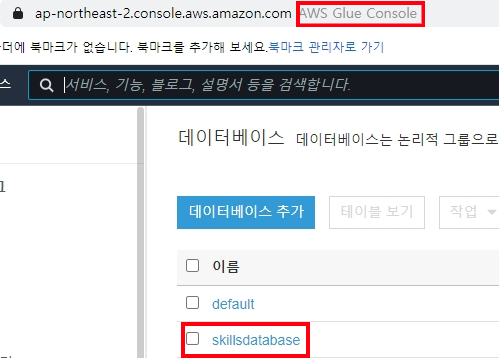
Glue에도 데이터베이스가 생성되어있다.
또 다른 쿼리
LB에 대한 302 Count 총 수
SELECT COUNT(elb_status_code) FROM alb_logs
WHERE elb_status_code = 302GET /v1/user 호출한 총 카운트 횟수 -> regexp_like를 사용하면 됩니다!!
참고 사이트 - https://www.stratusgrid.com/open-space/troubleshooting-access-logs-with-amazon-athena
select count('request_url') from alb_logs where request_verb = 'GET'AND regexp_like(request_url, 'http://korea-4-logs-098741357.ap-northeast-2.elb.amazonaws.com:80/v1/user')쿼리를 한 후 밑에 검색에서 GET, /v1/user를 입력해서 더해줘야 된다
POST /v1/user로 제일 많이 호출한 IP, 횟수
select client_ip, count('request_verb') as Data from alb_logs where request_verb = 'POST' AND regexp_like(request_url, 'http://korea-4-logs-098741357.ap-northeast-2.elb.amazonaws.com:80/v1/user') group by client_ip order by 'client_ip' desc limit 1쿼리를 한 후 밑에 검색에서 POST, /v1/user를 입력해서 해당하는 Ip와 Count가 답이다
LB에서 반환 하는 302 응답코드를 가장 많이 받은 순서로 IP 3개와 해당 IP 별로 302 응답코드
SELECT COUNT(elb_status_code) AS
count,
client_ip
FROM alb_logs WHERE elb_status_code = 302
GROUP BY client_ip
order by count DESC