9.9.6 Implicit Free Lists
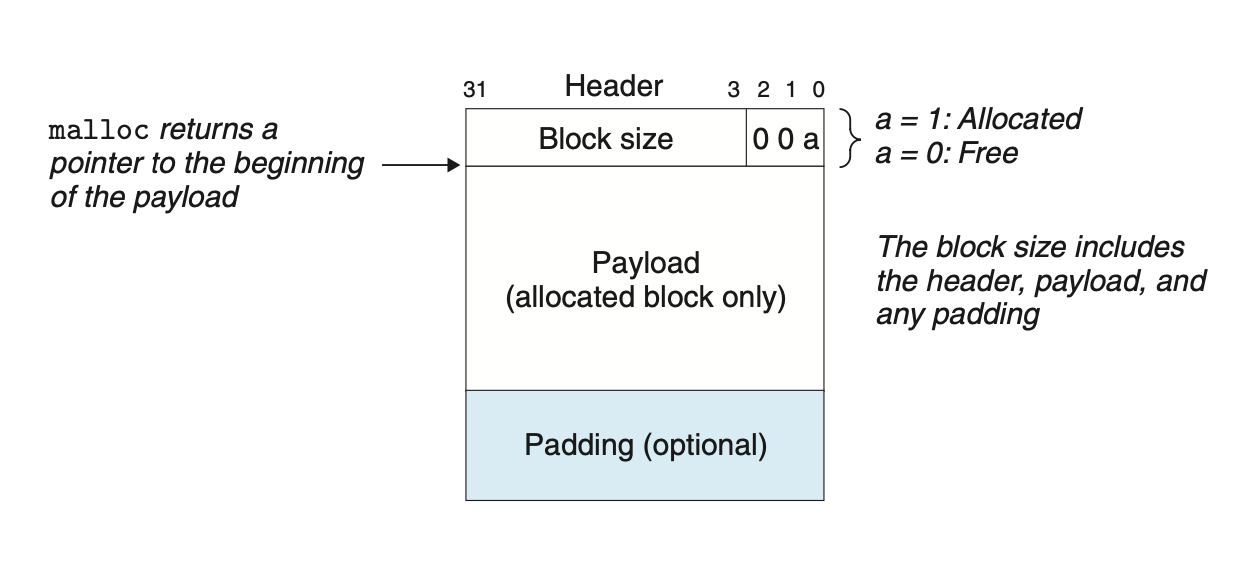
Any practical allocator needs some data structure that allows it to distinguish block boundaries and to distinguish between allocated and free blocks. Most allocators embed this information in the blocks themselves. One simple approach is shown in Figure 9.35.
실용적인 할당기는
1) 블록 경계를 구분하고
2) 할당된 영역과 Free 영역을 구분할 수 있어야 한다.
대부분의 할당기는 이러한 정보들을 블록안에 내장한다.
In this case, a block consists of a one-word header, the payload, and possibly some additional padding.
이 경우에 블록은 아래와 같이 구성된다.
1) 1 워드의 헤드
2) 데이터
3) 추가적인 패딩
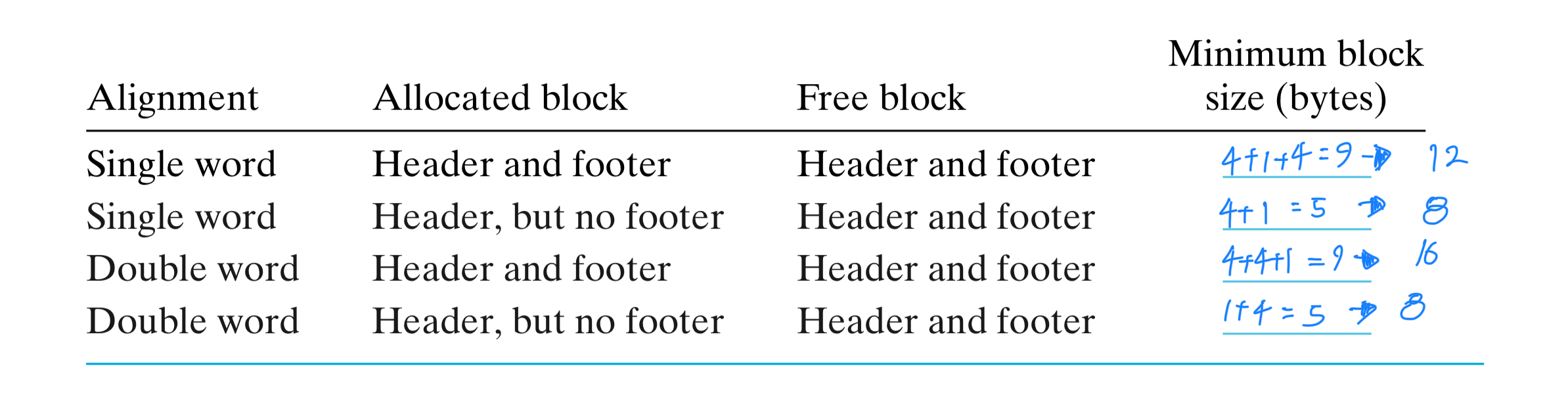
If we impose a double-word alignment constraint, then the block size is always a multiple of 8 and the 3 low-order bits of the block size are always zero. Thus, we need to store only the 29 high-order bits of the block size, freeing the remaining 3 bits to encode other information.
16바이트 크기의 메모리 블록은 이진수로 나타내면 10000인데,
이때 가장 낮은 3비트는 항상 000이 됩니다.
24바이트의 경우는 11000으로 나타나며, 가장 낮은 3비트는 역시 000입니다.
For example, suppose we have an allocated block with a block size of 24 (0x18) bytes. Then its header would be
0x00000018 | 0x1 = 0x00000019Similarly, a free block with a block size of 40 (0x28) bytes would have a header of
0x00000028 | 0x0 = 0x00000028
The header is followed by the payload that the application requested when it called malloc. The payload is followed by a chunk of unused padding that can be any size. There are a number of reasons for the padding. For example, the padding might be part of an allocator’s strategy for combating external fragmentation. Or it might be needed to satisfy the alignment requirement.
헤더 뒤로는 요구한 데이터들이 따라온다.
데이터 이후로는 패딩이 올 수도, 오지 않을 수도 있다. 패딩은 외부 단편화를 극복하거나 정렬 요구사항을 만족하기 위해 필요할 수 있다.
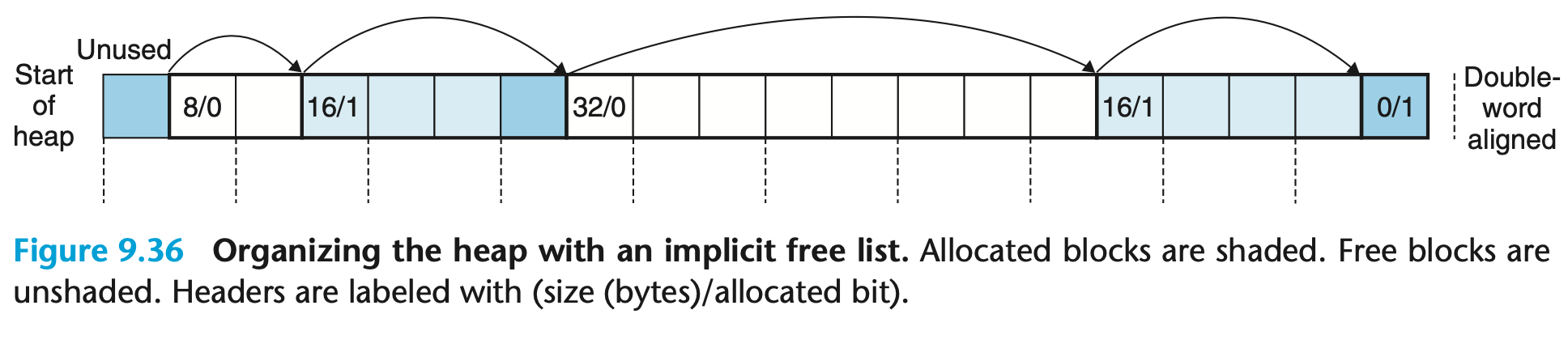
We call this organization an implicit free list because the free blocks are linked implicitly by the size fields in the headers. The allocator can indirectly traverse the entire set of free blocks by traversing all of the blocks in the heap. Notice that we need some kind of specially marked end block—in this example, a terminating header with the allocated bit set and a size of zero.
이러한 구조를 '묵시적 리스트' 라고 부르는데, 그것은 가용 블록이 헤더 내 필드에 의해서 묵시적으로 연결되기 때문이다.
"implicit free list"에서의 "묵시적(implicit)"이라는 용어는 할당된 블록 앞 뒤로 명시적인 자료구조를 사용하지 않고도 해당 블록의 상태(할당된 상태 또는 해제된 상태)를 판별할 수 있기 때문에 사용됩니다.

9.9.7 Placing Allocated Blocks
When an application requests a block of k bytes, the allocator searches the free list for a free block that is large enough to hold the requested block. The manner in which the allocator performs this search is determined by the placement policy. Some common policies are first fit, next fit, and best fit.
프로그램이 K bytes의 블록을 요청하면, 할당기는 할당하기 충분한 free block을 찾습니다. 이 때 할당기가 빈 공간을 찾는 방법은
1. first fit
2. next fit
3. best fit
세 가지가 있습니다.
First fit searches the free list from the beginning and chooses the first free block that fits. Next fit is similar to first fit, but instead of starting each search at the beginning of the list, it starts each search where the previous search left off. Best fit examines every free block and chooses the free block with the smallest size that fits.
First Fit은 첫 번째로 딱 맞는 공간을 찾습니다.
Next Fit 은 First Fit과 유사하나, 처음부터 시작하는 것이 아닌, 이전에 서치가 끝난 위치에서부터 시작합니다.
Best Fit은 모든 가용 블록을 검사하고 크기가 가장 작은 맞는 블록을 선택합니다.
9.9.8 Splitting Free Blocks
Once the allocator has located a free block that fits, it must make another policy decision about how much of the free block to allocate. One option is to use the entire free block. Although simple and fast, the main disadvantage is that it introduces internal fragmentation. If the placement policy tends to produce good fits, then some additional internal fragmentation might be acceptable.
할당기가 적절한 free 블록을 찾으면, 가용 블록의 어느 정도를 할당해야 할 지에 대해서 결정을 내려야 한다. 한 가지 옵션은 가용 블록 전체를 사용하는 것이다. 하지만 이는 내부 단편화를 초래한다. 만약 배치 정책이 잘 맞아 떨어진다면 (즉, 빈 공간을 찾을 때 부터 적절하게 거의 딱 맞아 떨어지게 찾았다면) 이정도의 단편화는 받아들일 만 하다.
However, if the fit is not good, then the allocator will usually opt to split the free block into two parts. The first part becomes the allocated block, and the remainder becomes a new free block. Figure 9.37 shows how the allocator might split the eight-word free block in Figure 9.36 to satisfy an application’s request for three words of heap memory.
그러나, 잘 맞아 떨어지지 않는다면 할당기는 대게 블록은 분할한다. 첫 번째 분할지에는 할당이 될 것이고, 다른 분할지는 새로운 free block이 될 것이다.
9.9.9 Getting Additional Heap Memory
What happens if the allocator is unable to find a fit for the requested block? One option is to try to create some larger free blocks by merging (coalescing) free blocks that are physically adjacent in memory (next section). However, if this does not yield a sufficiently large block, or if the free blocks are already maximally coalesced, then the allocator asks the kernel for additional heap memory by calling the sbrk function. The allocator transforms the additional memory into one large free block, inserts the block into the free list, and then places the requested block in this new free block.
만약 할당기가 요청한 블록을 찾을 수 없다면 어떻게 해야할까? 한 가지 옵션은 메모리에서 물리적으로 인접한 가용 블록들을 합쳐서 더 큰 가용 블록을 만들어 보는 것이다. 하지만, 이렇게 해도 충분히 큰 블록이 만들어지지 않거나 가용 블록이 이미 최대로 연결됐다면, 이 할당기는 커널에게 sork 함수를 호출해서 추가적인 힙 메모리를 요청한다. 할당기는 추가 메로리를 한 개의 더 큰 가용 블록으로 변환하고, 이 블록을 가용 리스트에 삽입한 후에 요청한 블록을 이 새로운 가용 블록에 배치한다.
9.9.10 Coalescing Free Blocks
When the allocator frees an allocated block, there might be other free blocks that are adjacent to the newly freed block. Such adjacent free blocks can cause a phenomenon known as false fragmentation, where there is a lot of available free memory chopped up into small, unusable free blocks.
할당기가 할당된 블록들을 해제 할 때, 반환하는 블록에 인접한 다른 가용 블록들이 있을 수 있겠죠?
이렇게 인접한 가용 블록들은 오류 단편화(False Fragmentation) 이라는 현상을 유발할 수 있으며, 이 때는 작고 사용할 수 없는 가용 블록으로 쪼개진 많은 가용 메모리들이 존재한다.

The result is two adjacent free blocks with payloads of three words each. As a result, a subsequent request for a payload of four words would fail, even though the aggregate size of the two free blocks is large enough to satisfy the request.
3워드를 갖는 인접한 두 블록들이 있다. 총 6개의 블록이 있지만 연속적으로 4워드를 채울 수 없기 때문에 단편화가 발생한다!
To combat false fragmentation, any practical allocator must merge adjacent free blocks in a process known as coalescing. This raises an important policy decision about when to perform coalescing. The allocator can opt for immediate coalescing by merging any adjacent blocks each time a block is freed. Or it can opt for deferred coalescing by waiting to coalesce free blocks at some later time.
오류 단편화를 극복하기 위해서, 실용적인 할당기는 연결(coalescing)이라는 과정으로 인접 가용 블록들을 통합해야한다.
할당기는 블록이 반환 될 때마다 인접 블록을 통합해서 즉시 연결을 할 수 있고, 또는 일정 시간 후에 가용 블록들을 연결하기 위해 기다리는 지연 연결을 할 수도 있다.
Immediate coalescing is straightforward and can be performed in constant time, but with some request patterns it can introduce a form of thrashing where a block is repeatedly coalesced and then split soon thereafter.
즉시 연결은 간단하며 상수 시간 내에 수행할 수 있지만, 일부 요청 패턴에 따라 블록이 연속적으로 연결되고 잠시 후에 분할되는 쓰래싱 형태를 유발할 수 있다.
9.9.11 Coalescing with Boundary Tags
How does an allocator implement coalescing? Let us refer to the block we want to free as the current block. Then coalescing the next free block (in memory) is straightforward and efficient. The header of the current block points to the header of the next block, which can be checked to determine if the next block is free. If so, its size is simply added to the size of the current header and the blocks are coalesced in constant time.
할당기는 어떻게 연결을 수행할까? 반환하려고 하는 블록을 Current Block 이라 하자. 다음 가용 블록을 메모리에 연결하는 것은 쉽다. Current Block의 헤더를 다음 블록의 헤더를 가리키고 있으며, 이것은 다음 블록이 가용한지 결정하기 위해 사용될 수 있다. 그렇다면 그 크기는 단순히 Current Header의 크기에 더해지고, 블록은 상수 시간 내에 연결할 수 있다.
But how would we coalesce the previous block? Given an implicit free list of blocks with headers, the only option would be to search the entire list, remember- ing the location of the previous block, until we reached the current block. With an implicit free list, this means that each call to free would require time linear in the size of the heap. Even with more sophisticated free list organizations, the search time would not be constant.
그런데 이전 블록들 (앞 방향이 아닌 뒷 방향에 있는 블록)은 어떻게 연결할 수 있을까? 유일한 옵션은 현재 블록에 도달할 때 까지 전체 리스트를 검색해서 이전 블록의 위치를 기억하는 것이다. 보다 복잡한 가용 리스트 구조를 사용하더라도 이 검색 시간은 상수가 될 수 없다.
Knuth developed a clever and general technique, known as boundary tags, that allows for constant-time coalescing of the previous block. The idea, which is shown in Figure 9.39, is to add a footer (the boundary tag) at the end of each block, where the footer is a replica of the header. If each block includes such a footer, then the allocator can determine the starting location and status of the previous block by inspecting its footer, which is always one word away from the start of the current block.
Knuth는 boundary tags (경계 태그) 라는 똑똑한 방법을 고안해냈다. 이 기법은 상수 시간에 이전 블록을 연결하게 해준다.
각 블록의 끝 부분에 footer를 추가하는 것으로, 이 footer는 헤더를 복사한 것이다. 만일 각 블록이 이와 같이 footer를 포함하게 되면, 할당기는 시작 위치와 이전 블록의 상태를 자신의 풋터를 조사해서 결정할 수 있게 되며, 이것은 항상 현재 블록의 시작 부분에서 한 워드 떨어진 곳에 위치한다.