강의 스터디
수강할 강의
스터디를 진행할 강의를 링크해주세요.
- 데이터 리터러시
- 문제 정의
- 데이터 유형
- 지표 설정
- 결론 도출
강의에서 필수 사용되는 문법 요약
강의에서 필수로 사용되는 문법에 대한 개념을 요약해주세요.
-
데이터 리터러시
-
데이터 리터러시란?
- 데이터를 읽고, 이해하고 비판적으로 분석하여 의사소통에 활용
- 데이터 수집과 원천, 활용법, 핵심 지표를 이해
- 올바른 질문을 던질 수 있도록 도와줌.
-
데이터 분석 착각
- 데이터 분석 스킬이 부족한 것 같아..
- SQL, Python, Tableau 배운다고 잘 되겠냐???
- 데이터 분석 스킬이 부족한 것 같아..
-
데이터 해석 오류
- 심슨의 역설
- 부분에서 성립한 대소 관계가 전체에는 성립하지 않음.
- 백신 접종 여부에 따른 델타 변이 확진자 수, 4주 내 사망자 수 비교
- 치명률 : 백신 미접종자 < 백신 접종완료 환자 (3배)
- Why?
- 50세 이상으로 쪼개 보면 백신 미접종자 > 백신 접종 완료 (5배)
- 50세 미만으로 쪼개 보면 둘 다 치명률 매우 낮음. ⇒ 50세 이상에서 효과가 있음.
- 심슨의 역설
-
시각화를 활용한 왜곡
- 자료 표현 방법에 따라 해석 오류 여지 존재
- 매해 노동자와 자본가 버는 시간당 액수의 증가율
- 원본, 로그, 증가율에 따라 전혀 다른 해석이 가능
-
샘플링 편향
- 전체 대표 못하는 편향된 샘플 선정으로 인해 오류 발생
- 루즈벨트 vs 랜던 여론 조사
- 여론조사 : 랜던 승 / 실제 : 루즈벨트 승
- Why?
- 여론조사용 인적 사항 수집 시 공화당 투표할 부유층에게 주로 수집됨.
-
상관관계와 인과관계
- 상관관계
- 두 변수가 얼마나 상호 의존적인가?
- 원인과 결과는 아님. 같이 움직이거나 반대로 움직이거나
- 인과관계
- 하나의 요인으로 다른 요인의 수치가 변함.
- 원인과 결과 명확
- 예시
- 소아마비를 줄이려면 아이스크림 줄여야 된다?
- X ⇒ 둘 다 여름에 많이 일어남. 그저 날씨에 두 가지 결과가 영향 받는다는 것.
- 상관관계
-
데이터 활용 예제
- 이 회사가 운영되기 위해 가장 중요한 파트 순서
- 개발 → 마케팅 → 인사, 영업 → 재무 → 고객 지원
- 회사 설립 초기로 보임.
- 고객 지원이 현재는 가장 비중이 적지만 후에 더 성장하게 되면 더 많은 인원 뽑아야 할 수도
- 마케팅 인원이 너무 많으니 감축 필요해보임.
- 이 회사가 운영되기 위해 가장 중요한 파트 순서
-
데이터 리터러시가 필요한 이유
- 문제 및 가설 정의 (생각)
- 데이터 분석 (분석)
- 결과 해석 및 액션 도출 (생각)
⇒ 생각 부분에서 문제가 많이 됨.
⇒ 데이터 분석이 목적이 되면 안되므로 왜? 를 항상 생각 필요
-
-
문제 정의
- 문제 정의란?
- 데이터 분석 프로젝트 성공을 위한 초석
- 특정 상황 현상에 대한 명확하고 구체적 진술
- 프로젝트 목표 설정, 분석 방향 결정
- 문제 정의 사례
- 상황 : 패션 플랫폼 A, 매출 증가 목표
- 문제 : 어떻게 늘릴까??
-
모호하고 구체적 X
-
어떤 고객층, 제품 초점을 맞출지 명확한 지침 X
⇒ 지난 6개월 동안 25 - 35세 여성 고객층 구매 전환율 급격히 감소,
이 고객층의 전환율을 3% 올리려면 어떤 전략 적용할까?
-
- 문제 정의 예제
- 3개월 전부터 사용자 감소
- 포인트 이벤트 중 → 효과 없음
- 서비스 A보다 B 더 안좋은 상황
- 사용자 감소 → 수입 감소
- 문제 정의 방법론
- MECE 방법론 : 상호 배타적 + 전체적으로 포괄적인 구성요소로 나눔.
- 기준을 잡는다.
- 그 기준을 겹치지 않게 쪼갤 수 있는 대로 쪼갠다.
- 쪼갠 것들을 합치면 전체가 되어야 한다.
- Logic Tree
- 매출 하락 원인
- 고객 수 감소
- 신규
- 기존
- 평균 구매액 감소
- 가격 인하
- 구매 빈도 감소
- 고객 수 감소
- 예) 수입 감소 원인 무엇인가?
- 사용자 수 감소
- A 서비스
- B 서비스
- 신규
- 기존
- 평균 구매액 감소
- 사용자 수 감소
- 매출 하락 원인
- MECE 방법론 : 상호 배타적 + 전체적으로 포괄적인 구성요소로 나눔.
- 수익성 개선 방법
- 매출 증가
- 고객 증가
- 신규
- 신규 고객 증가
- 기존
- 이탈 고객 감소
- 신규
- 구매액 증가
- 고객 증가
- 비용 감소
- 고정비
- 변동비
- 매출 증가
- 로직트리 Cheat Sheet
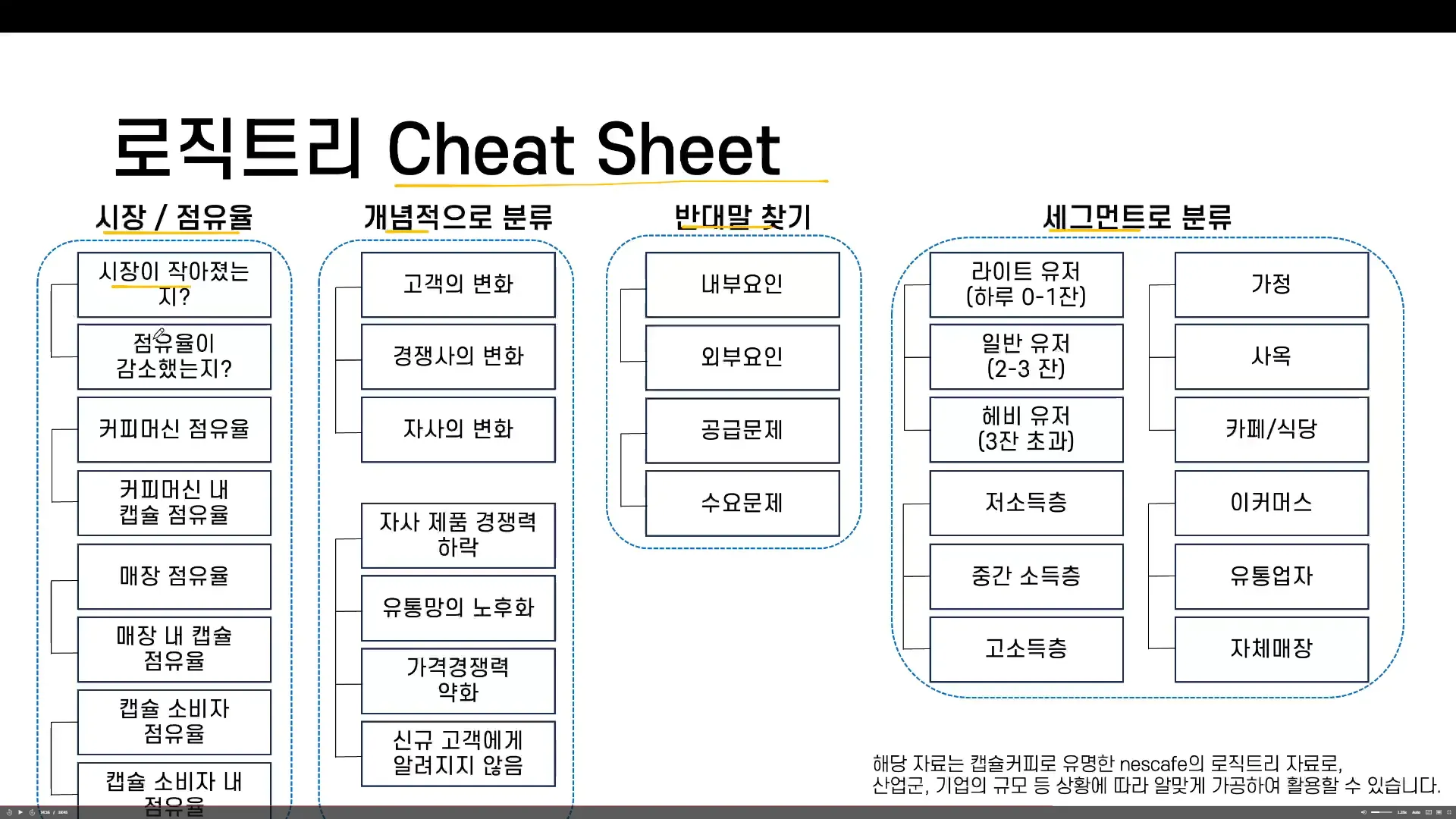
- 문제정의 왜 하냐?
-
풀고자 하는 걸 명확하게 정의
→ 분석 방향성 잡음.
→ 결과 정리 및 해석
→ 더 나아지기 위한 새로운 액션 플랜 수립
-
So What? Why So?
- So What?
- 결국 어떻다는 거야?
- 과제 답변에 맞는 중요한 핵심 추출
- Why So?
- 왜 그렇게 말할 수 있는지?
- 무슨 뜻인지 검증/확인
- So What?
-
- 팁
- 누구에게 공유하는가?
- 어떤 변화를 원하는가?
- 경영자 입장에서 보려고 노력
- 많은 사람들과 의견 나눠보자
- 혼자 오래 고민해보는 시간 갖자
- 문제 정의란?
-
데이터 유형
- 정성적 Vs. 정량적
- 정성적
- 비수치적 정보. 경험/관점/태도
- 구조화 어려움.
- 새로운 현상 개념 이해
- 정량적
- 수치적 표현됨.
- 숫자 형태로 존재
- 개인 해석 또는 주관 적게 작용
- 정성적
- 정량적 제이터 사례
- 인구 통계 데이터
- 수치형 설문조사 데이터
- 비즈니스 데이터 (매출 등)
- 행동 로그 데이터 (유저 행동 트래킹)
- 마케팅 데이터
- 정량적 데이터 활용
- 객관적, 측정 가능 지표로 활용
- 수치형 설문 조사 데이터 (추천지수, NPS)
- 통계적 분석 적용
- 데이터 경향성/패턴 파악 (분포, 평균, 중앙값 등 계산 통해)
- 중요한 의사결정 가능
- 예측 모델링, 추세 분석, 비즈니스 분석 등
- 정성적 Vs. 정량적
과제
-
3회차
-
로그정의서
구분 상세 schema logid 로그id int ip_addr ip주소 string first_login_date 첫 접속일자, yyyy-mm-dd string game_account_id 게임계정id string game_actor_id 게임캐릭터id int level 캐릭터 레벨 int exp 현재경험치 int serverno 서버넘버 int zone_id 지역넘버 int etc_num1 파티id int etc_num2 파티원수 int etc_str1 아이템 획득경로 string etc_num3 아이템 획득량 int etc_str2 아이템 이름 string -
💪 지난번 DBeaver에 업로드 한 users.csv 파일을 기준으로, 아래 쿼리문을 작성해 주세요.
-
문제1 - 집계함수의 활용
- 조건1) 서버별, 월별 게임계정id 수를 중복값 없이 추출해주세요.
- 월은 첫 접속일자를 기준으로 계산해주세요. 월은 yyyy-mm의 형태로 추출해주세요.select serverno, substring(first_login_date, 1, 7), count(distinct game_account_id) from users u group by 1, 2;- 힌트: 월을 추출하는 방법→날짜는 string(문자열) 형식으로 저장되어 있으므로, 문자열을 자르는 함수를 사용해주시면 좋겠죠?
-
문제2 - 집계함수와 조건절의 활용
-
조건1) group by 를 활용하여 첫 접속일자별 게임캐릭터수를 중복값 없이 구하고,
-
조건2) having 절을 사용하여 그 값이 10개를 초과하는 경우의 첫 접속일자 및 게임캐릭터id 개수를 추출해주세요.
select first_login_date, count(distinct game_actor_id) from users u group by 1 having count(distinct game_actor_id) > 10;
-
-
문제3 - 집계함수와 조건절의 활용
-
조건1) group by 절을 사용하여 서버별, 유저구분(기존/신규) 게임캐릭터id수를 구해주세요. 중복값을 허용하지 않는 고유한 갯수로 추출해주세요.
-
조건2) 기존/신규 기준→ 첫 접속일자가 2024-01-01 보다 작으면(미만) 기존유저, 그렇지 않은 경우 신규유저
-
조건3) 또한, 서버별 평균레벨을 함께 추출해주세요.
select serverno, count(case when first_login_date < '2024-01-01' then 1 end) as '기존', count(case when first_login_date >= '2024-01-01' then 1 end) as '신규', avg(`level`) from users u group by 1 order by 1;
-
-
문제4 - SubQuery의 활용
-
위와 같은 문제를 having 이 아닌 인라인 뷰 subquery를 사용하여, 추출해주세요.
-
조건1) 문제 2번을 having 이 아닌 인라인 뷰 서브쿼리를 사용하여 추출해주세요.
-
힌트: 인라인 뷰 서브쿼리는 from 절 뒤에 위치하여, 마치 하나의 테이블 같은 역할을 했었습니다!
select * from ( select first_login_date, count(distinct game_actor_id) as cnt_actor_id from users u group by 1 ) a where cnt_actor_id > 10;
-
-
문제5 - SubQuery의 응용
-
조건1) 레벨이 30 이상인 캐릭터를 기준으로, 게임계정 별 캐릭터 수를 중복값 없이 추출해주세요.
-
조건2) having 구문을 사용하여 캐릭터 수가 2 이상인 게임계정만 추출해주세요.
-
조건3) 인라인 뷰 서브쿼리를 활용하여 캐릭터 수 별 게임계정 개수를 중복값 없이 추출해주세요.
select cnt_actor_id, count(distinct game_account_id) from ( select game_account_id, count(distinct game_actor_id) as cnt_actor_id from users u where level >= 30 group by 1 having count(distinct game_actor_id) >= 2 ) a group by 1;
-
-
-
-
5회차
- 로그정의서 - users
구분 상세 schema logid 로그id int ip_addr ip주소 string first_login_date 첫 접속일자, yyyy-mm-dd string game_account_id 게임계정id string game_actor_id 게임캐릭터id int level 캐릭터 레벨 int exp 현재경험치 int serverno 서버넘버 int zone_id 지역넘버 int etc_num1 파티id int etc_num2 파티원수 int etc_str1 아이템 획득경로 string etc_num3 아이템 획득량 int etc_str2 아이템 이름 string - 로그정의서 - payment
구분 상세 schema game_account_id 게임계정id string pay_amount 결제금액 bigint pay_type 결제수단 string approved_at 결제승인일시 string
- 로그정의서 - users
-
문제1 - JOIN 활용
1. 조건1) 알맞은 join 방식을 사용하여 users 테이블을 기준으로, payment 테이블을 조인해주세요.
2. 조건2) case when 구문을 사용하여 결제를 한 유저와 결제를 하지 않은 게임계정을 구분해주시고, 컬럼이름을 gb로 지정해주세요.
3. 조건3) gb를 기준으로 게임계정수를 추출해주세요. 컬럼 이름은 usercnt로 지정해주시고, 결과값은 아래와 같아야 합니다.
select gb, count(distinct game_account_id)
from
(
select u.game_account_id,
case when p.game_account_id is null then '결제안함'
else '결제함' end as gb
from users u
left join payment p on u.game_account_id = p.game_account_id
) a
group by 1;문제2 - JOIN 응용1
1. 조건1) users 테이블에서 서버번호가 2 이상인 데이터와 payment 테이블에서 결제방식이 CARD 모두를 만족하는 경우를 알맞은 방식으로 join 해 주세요. payment 테이블의 매출 금액이 중복되는 것을 방지하기 위해 모든 값을 고유하게 추출해야 합니다.
2. 조건2) 조인한 결과를 바탕으로 users 테이블의 game_account_id 를 기준으로 game_actor_id수를 중복값없이 세고 컬럼 이름을 actor_cnt로 지정해주세요. 또한 pay_amount 값을 더해주시고, 컬럼 이름을 sumamount로 지정해주세요.
3. 조건3) having 을 사용하지 않고, 인라인 뷰 subquery 사용으로 actor_cnt수가 2 이상인 경우만 추출해주세요. 그리고 sumamount를 기준으로 내림차순 정렬해주세요.
결과값은 아래와 같아야 합니다. 전체결과 중 일부입니다.select * from ( select a.game_account_id, count(distinct b.game_actor_id) actor_cnt, sum(a.pay_amount) sumamount from ( select * from payment p where pay_type = 'card' ) a inner join ( select * from users u where serverno >= 2 ) b on a.game_account_id = b.game_account_id group by 1 ) c where actor_cnt >= 2문제2 - JOIN 응용2
1. 조건1) user 테이블에서 game_account_id, first_login_date, serverno 를 추출한 결과와
2. 조건2) payment 테이블에서 game_account_id 별 가장 마지막 결제일자를 찾고 그 컬럼이름을 date2로 지정해주세요. 그 다음 inner join 을 진행해주세요. 다만, 첫 접속일자보다 마지막 결제일자가 큰 경우만 추출해주세요.
3. 조건3) 조인 결과를 바탕으로 마지막 결제일자-첫 접속일자 를 구해주세요. 그리고 컬럼이름을 diffdate로 설정해주세요. 두 날짜의 형식은 같아야 합니다.
4. 조건4) 인라인 뷰 subquery 를 이용하여 서버별 평균 diffdate를 구해주시고, 컬럼이름을avgdiffdate로 설정해주세요. 해당컬럼은 정수 형태로 출력되어야 합니다.
5. 조건5) 조건절에 avgdiffdate 값이 10일 이상인 경우를 필터링해주세요. 그리고 서버번호를 기준으로 내림차순 정렬해주세요. 결과값은 아래와 같아야 합니다. 전체결과 중 일부입니다.
힌트) 소수점을 반올림해주는 round 함수를 활용해주세요!select serverno, round(avg(diffdate),0) as avgdiffdate from ( select a.game_account_id, a.first_login_date, b.date2, datediff(b.date2, a.first_login_date) diffdate , a.serverno from ( select game_account_id , first_login_date , serverno from users u ) a inner join ( select game_account_id , max(approved_at) as date2 from payment p group by 1 ) b on a.game_account_id = b.game_account_id where b.date2 > a.first_login_date ) c where diffdate >= 10 group by 1 order by 1 desc;
오답노트
- count에 조건 넣기
select serverno, count(case when first_login_date < '2024-01-01' then 1 end) as '기존', count(case when first_login_date >= '2024-01-01' then 1 end) as '신규', avg(`level`) from users u group by 1 order by 1;- Count(Case When ~~~ then 1 end) as
- 이건 왜 안돼요??
select * from ( select a.game_account_id, actor_cnt, sum(pay_amount) sumamount from ( select * from payment p where pay_type = 'card' ) a inner join ( select game_account_id, count(distinct game_actor_id) actor_cnt from users u where serverno >= 2 group by 1 ) b on a.game_account_id = b.game_account_id group by 1 ) c where actor_cnt >= 2 order by sumamount desc; - Distinct 활용
select * from ( select a.game_account_id, count(distinct b.game_actor_id) actor_cnt, sum(a.pay_amount) sumamount from ( select distinct game_account_id, pay_amount, approved_at from payment p where pay_type = 'card' ) a inner join ( select * from users u where serverno >= 2 ) b on a.game_account_id = b.game_account_id group by 1 ) c where actor_cnt >= 2- Distinct game_account_id, pay_amount, approved_at
- account_id, pay_amount, approved_at 세 컬럼을 하나의 덩어리로 Distinct 적용됨.
- 세 컬럼에 똑같은 데이터가 2개 이상 쌓이면 Distinct를 통해 중복 제거 가능
- Ex.
- Distinct 전
game_account_id pay_amount approved_at a 100 2024-10-14 a 100 2024-10-14 a 200 2024-10-17 - Distinct 후
game_account_id pay_amount approved_at a 100 2024-10-14 a 200 2024-10-17
- Distinct 전
- Distinct game_account_id, pay_amount, approved_at
