강화학습 (1) - Markov Decision Process
Reinforcement Learning 개요
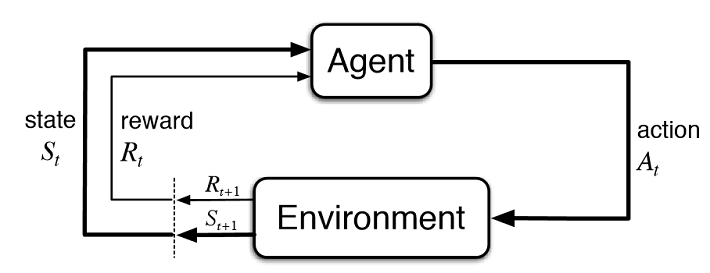
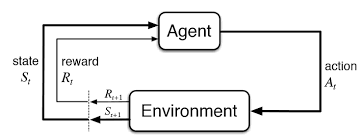
강화학습이란 크게 Agent, Environment로 나뉘어진다. 기존 머신러닝과 딥러닝에 비해 Agent의 행동에 따라 환경의 state, reward가 주어지게 된다. 이 때 Agent가 취할 행동이 reward의 누적값의 최대화가 되는 방향으로 학습을 하는 것이 강화학습이다. 강화학습은 불확실성 내에서 일련의 Action들을 통한 현재의 Reward와 미래의 Reward를 최대화 시키게 된다. 이를 통해 변화하는 수요와 비용을 갖는 Value Chain을 최적화시키는 방법에 대해 공부해보려고 한다.
Markov Decision Process
Markov Process (Markov Chain)
Reward, Action이 없는 상태에서 state 끼리의 확률정 상호관계를 정의
S : Set of states
P : Dynamics / transition model that specifies probability of states
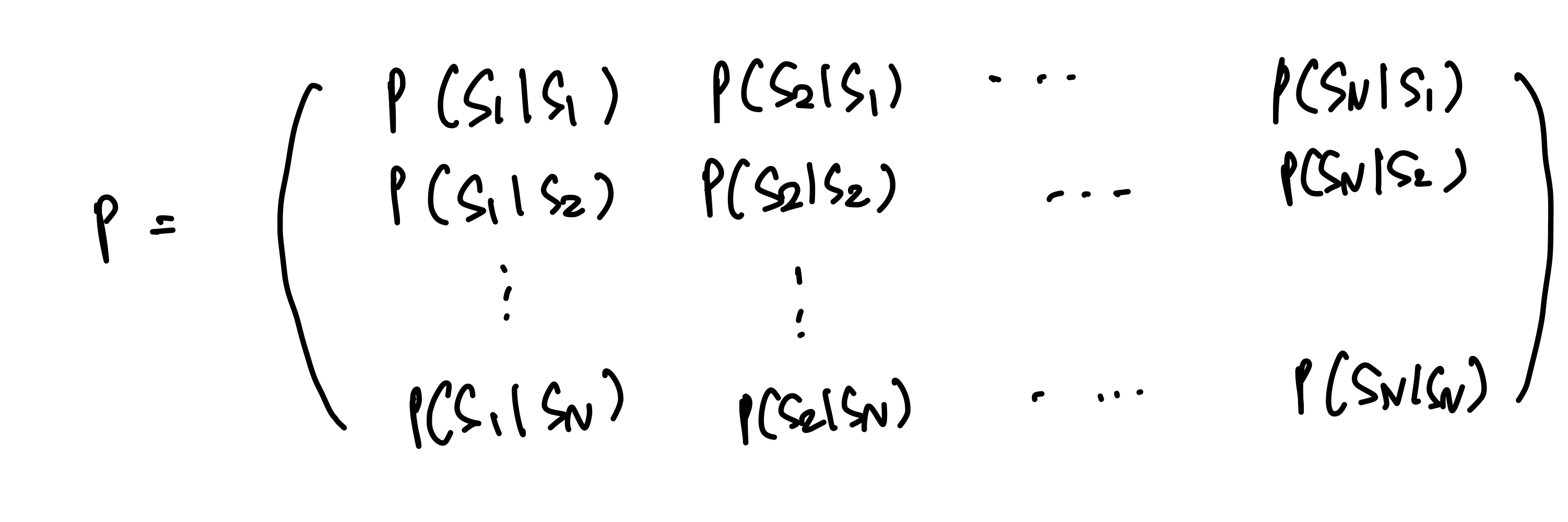
Markov Reward Process
Markov Chain + Reward (action은 고려하지 않는다)
S : Set of states
P : Dynamics/transition model that specifies probaiblity of states
R : Reward function
Discount factor
- Return (G_t)
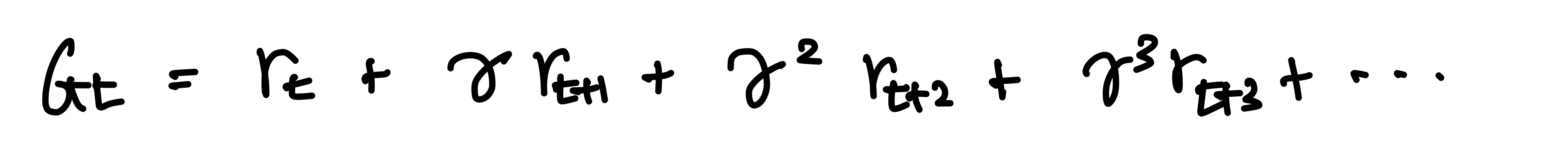
- Expected Value Function (Expected return from state S)
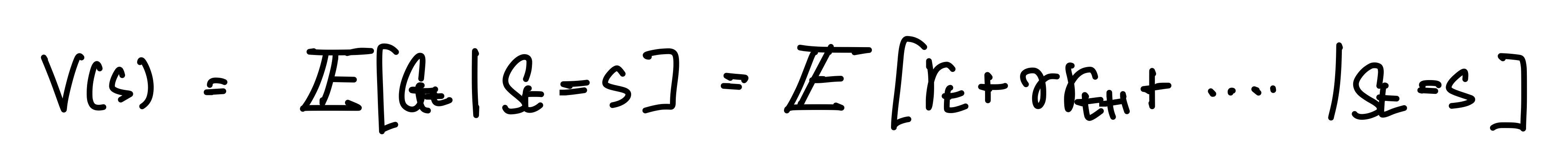
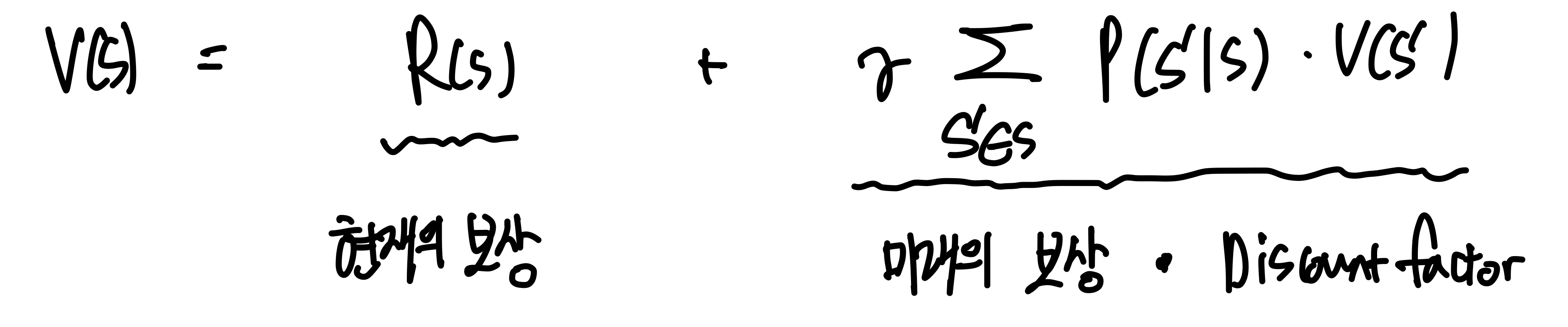
위와 같은 값으로 정의될 수 있다. 즉, 학습의 목표는 위 Value Function의 값을 최대화하는 것이다. 이를 위해서 Dynamic Programming이 사용된다.
Markov Decision Process
MRP + actions
이러한 Markov Reward Process에서 action이 추가되면서 state에 대한 action의 policy를 최적화하는 방향을 찾아야한다.
- State Value Function

위 State function을 최대화하는 방향으로 Optimal Policy, 즉 action을 선택하게 된다. - Action Value Function
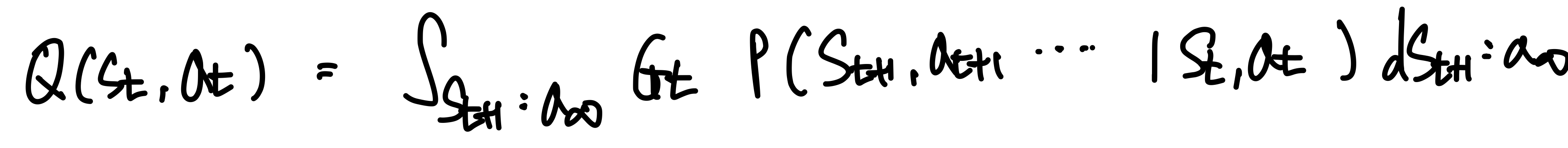
주어진 Action을 취했을 때 Expected Value 값이다.

안녕하세요:)