재귀 알고리즘
재귀 알고리즘이란?
자기 자신을 호출하는 알고리즘입니다. 문제를 더 작고 동일한 형태의 하위 문제로 나누어 푸는 방식
장점
코드가 간결하고 직관적이다.
반복문으로 표현하기 어려운 문제에 유리 (예: 트리 탐색, 백트래킹, DFS 등)
단점
호출 스택(stack memory)을 많이 사용 → StackOverflow 위험
속도 느림, 비효율적일 수 있음
예시
팩토리얼 예시
1. 재귀함수
def factorial(n):
if n > 0:
return n * factorial(n-1)
else:
return 1
n = 10
print(factorial(5))- 반복문 사용
# 반복문 while로 풀기
import sys
input = sys.stdin.readline
n = int(input())
multi_num = 1 # 초기값을 1로 설정
while n > 0:
multi_num *= n
n = n - 1
print(multi_num)유클리드 호제법
두 정수값의 최대 공약수(GCD)를 구하는 알고리즘
A, B의 최대 공약수 = B , A % B 의 최대공략수와 같다
# 최대공약수 GCD
def gcd(A, B):
if y == 0:
return A
else:
return gcd(B ,A % B)
print(gcd(144, 60)) # 최대공약수 12 출력ex) 144, 60의 최대 공약수
A, B = 144, 60
60, 24
24, 12
12, 0
12가 A,B의 최대 공약수
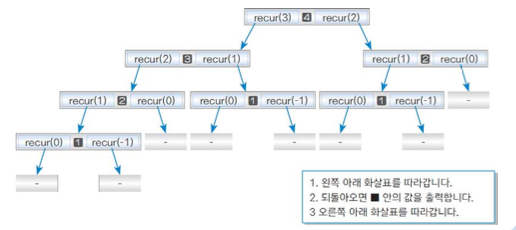
재귀 알고리즘으 2가지 분석
def recur(n):
if n >0:
recur(n-1)
print(n)
recur(n-2)
print(4)
1
2
3
1
4
1
2그냥 보면 이 재귀 함수가 어떻게 동작하지는 알기 쉽지 않다.
재귀 분석 방법은 이제 2개 하양식, 싱향식 분석이 있다.
하양식 분석
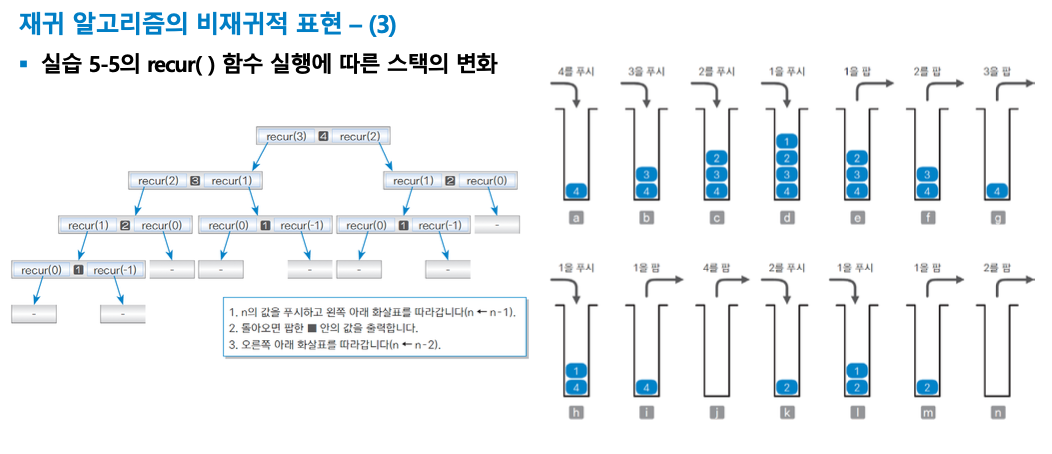
recur(4)의 실행 과정
1. recur(3)을 실행 ...
2. 4출력
3. recur(2)를 실행 ...
- 위 과정에서 4가 출려되려면 revur(3) 실행을 완료해야함
- 마지막으로 전달값이 0이라면 recur()는 아무 일도 하지 않기 떄문에 - 표시
- 이렇게 가장 위쪽 함수 호출부터 시작해 계단식으로 자세히 조사해 나가는 분석 방법을 하양식 분석(top-down analysis)이라함
상향식 분석
recur(1)의 실행 과정
1. recur(0)을 실행 ...
2. 1출력
3. recur(-1)를 실행 ...
아래부터 샇아 올리며 분석하는 방식은 상향식 분석(bottom-up analysis)이라 함
recure()는 양수일 때만 실행하므로 먼저 0, -1은 출력할 내용이 없으므로 2 과정 중 1만 출력
recur(2)의 실행 과정
4. recur(1)을 실행 ...
5. 1출력
6. recur(0)를 실행 ...
recur(1) 출력하지만 recur(0)은 출력하지 않음
recur(1)과 recur(2)의 과정을 거쳐서 1과 2출력 이대로 recur(4)까지 오르면 최종 출력 얻기 가능(1,2,3,1,4,1,2)
재귀 알고리즘의 비재귀적 표현
꼬리 재귀를 제거하기
def recur(n):
while n > 0:
recur(n-1)
print(n)
n = n - 2recur(n-2)의 의미는 인수로 n-2의 값을 전달하고 recur() 함수를 구현 따라서 이 호출은 다음 동작으로 바꿀 수 있음
n의 값을 n - 2로 업데이트하고 함수의 시작지점으로 돌아감
이렇게하면 recur() 함수의 맨 끝에서 실행된 재귀 호출인 꼬리 재귀를 제거 가능
재귀를 제거하기
꼬리와 달리 맨 앞에서 재귀 호출하는 recur(n-1) 함수는 제거하기 쉽지 않음
왜 WHY?
n 값이 호출되기 전에 recur(n-1)을 실행해야하기 때문 예를 들어 n값이 4인 경우 재귀 호출 recur(3)의 처리가 완료될 때까지 4를 어딘가에 저장해야함 -> 스택으로 해결 가능
from stack import Stack
def recur(n):
s = Stack(n)
while True:
if n > 0:
s.push(n) # n 값을 푸쉬
n = n - 1
continue
if not s.is_empty(): # 스택이 비어 있지 않으면
n = s.pop() # 저장한 값을 n에 팝
print(n)
n = n -2
continue
break
recur(4)