CSAPP Chapter 9.9: 동적 메모리 할당 (Dynamic Memory Allocation)
9.9 개요
C 프로그래머들은 런타임에 추가 가상 메모리가 필요할 때, 저수준의 mmap과 munmap 함수를 사용하는 것보다 동적 메모리 할당자(dynamic memory allocator)를 사용하는 것이 더 편리하고 이식성이 좋습니다.
힙(Heap)의 개념
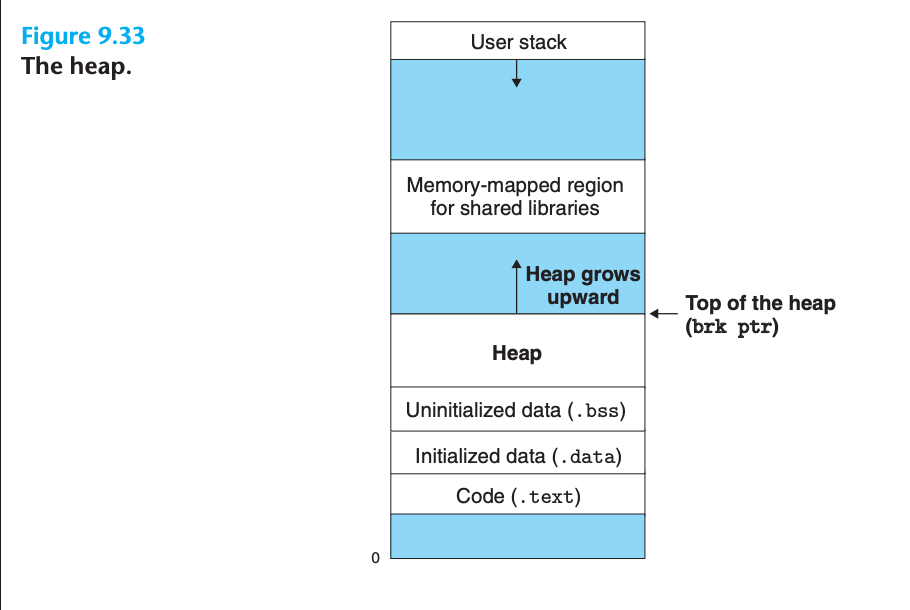
- 동적 메모리 할당자는 프로세스의 가상 메모리 영역 중 힙을 관리
- 힙은 초기화되지 않은 데이터 영역 바로 다음에 시작하여 위쪽(높은 주소)으로 성장하는 demand-zero 메모리 영역
- 커널은 각 프로세스에 대해 brk 변수를 유지하며, 이는 힙의 최상단을 가리킴
블록의 개념
- 할당자는 힙을 다양한 크기의 블록들의 집합으로 관리
- 각 블록은 연속된 가상 메모리 청크로, 할당된(allocated) 또는 가용(free) 상태
- 할당된 블록: 애플리케이션에 의해 명시적으로 예약된 블록
- 가용 블록: 할당 가능한 블록
할당자의 두 가지 스타일
1. 명시적 할당자 (Explicit Allocators)
- 애플리케이션이 명시적으로 할당된 블록을 해제해야 함
- 예: C 표준 라이브러리의
malloc패키지 malloc()으로 블록 할당,free()로 블록 해제- C++의
new와delete도 유사
2. 암시적 할당자 (Implicit Allocators)
- 할당자가 프로그램에서 더 이상 사용되지 않는 할당된 블록을 자동으로 감지하고 해제
- 가비지 컬렉터(garbage collector)라고도 함
- 자동으로 사용되지 않는 할당된 블록을 해제하는 과정을 가비지 컬렉션이라고 함
- 예: Lisp, ML, Java 등의 고수준 언어
9.9.1 malloc과 free 함수
malloc 함수
#include <stdlib.h>
void *malloc(size_t size);
// 성공 시: 할당된 블록에 대한 포인터 반환
// 실패 시: NULL 반환특징:
- 최소
size바이트의 메모리 블록에 대한 포인터 반환 - 블록 내에 포함될 수 있는 모든 종류의 데이터 객체에 적합하게 정렬됨
- 32비트 모드: 주소가 항상 8의 배수
- 64비트 모드: 주소가 항상 16의 배수
- 반환된 메모리는 초기화되지 않음
sbrk 함수
#include <unistd.h>
void *sbrk(intptr_t incr);
// 성공 시: 이전 brk 포인터 반환
// 실패 시: -1 반환- 커널의 brk 포인터에
incr를 추가하여 힙을 확장하거나 축소 incr가 0이면 현재 brk 값 반환- 음수
incr는 합법적이지만 까다로움
free 함수
#include <stdlib.h>
void free(void *ptr);
// 반환값: 없음주의사항:
ptr인자는malloc,calloc,realloc에서 얻은 할당된 블록의 시작을 가리켜야 함- 그렇지 않으면
free의 동작이 정의되지 않음 - 아무것도 반환하지 않으므로 애플리케이션에게 문제가 있다는 표시를 주지 않음
malloc과 free 사용 예제
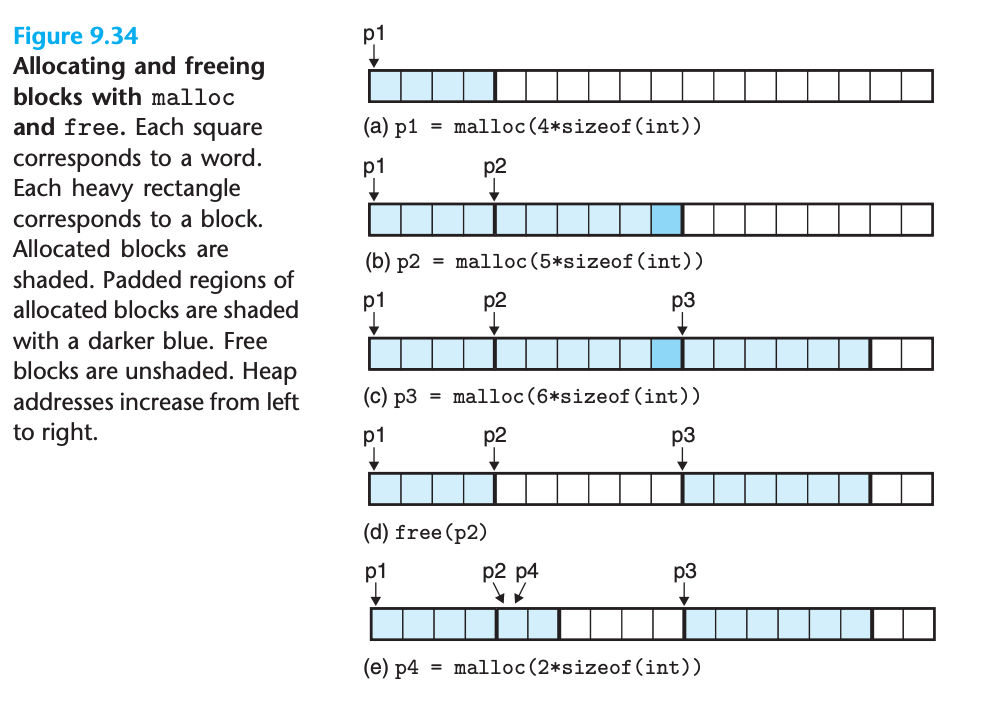
(a) p1 = malloc(4*sizeof(int)) → 4워드 블록 할당
(b) p2 = malloc(5*sizeof(int)) → 6워드 블록 할당 (정렬을 위해 패딩)
(c) p3 = malloc(6*sizeof(int)) → 6워드 블록 할당
(d) free(p2) → p2 블록 해제
(e) p4 = malloc(2*sizeof(int)) → 해제된 블록의 일부 재사용9.9.2 동적 메모리 할당이 필요한 이유
문제점: 하드코딩된 크기
#define MAXN 15213
int array[MAXN];
int main() {
int i, n;
scanf("%d", &n);
if (n > MAXN)
app_error("Input file too big");
for (i = 0; i < n; i++)
scanf("%d", &array[i]);
exit(0);
}문제점:
MAXN값이 임의적이고 실제 가상 메모리 양과 무관MAXN보다 큰 파일을 읽으려면 프로그램을 다시 컴파일해야 함- 대규모 소프트웨어에서 유지보수 악몽이 될 수 있음
해결책: 동적 할당
int main() {
int *array, i, n;
scanf("%d", &n);
array = (int *)Malloc(n * sizeof(int));
for (i = 0; i < n; i++)
scanf("%d", &array[i]);
free(array);
exit(0);
}장점:
- 배열의 최대 크기가 사용 가능한 가상 메모리 양에 의해서만 제한됨
- 런타임에 크기가 결정됨
9.9.3 할당자 요구사항과 목표
제약 조건
- 임의의 요청 시퀀스 처리: 할당과 해제 요청의 임의적 순서 처리
- 즉시 응답: 할당 요청에 즉시 응답해야 함
- 힙만 사용: 확장성을 위해 할당자가 사용하는 비스칼라 데이터 구조는 힙 자체에 저장
- 블록 정렬: 모든 종류의 데이터 객체를 보유할 수 있도록 블록 정렬
- 할당된 블록 수정 금지: 할당된 블록을 수정하거나 이동할 수 없음
성능 목표
목표 1: 처리량 최대화
- 처리량: 단위 시간당 완료하는 요청 수
- 할당과 해제 요청을 만족시키는 평균 시간을 최소화하여 처리량 최대화
- 할당 요청의 최악의 경우 실행 시간: 가용 블록 수에 선형
- 해제 요청의 실행 시간: 상수
목표 2: 메모리 활용도 최대화
- 가상 메모리는 제한된 자원이므로 효율적으로 사용해야 함
- 피크 활용도(peak utilization)가 가장 유용한 지표
- 피크 활용도 공식:
Uk = max(i≤k) Pi / HkPi: 현재 할당된 블록들의 페이로드 합계Hk: 현재 힙 크기
9.9.4 단편화(Fragmentation)
내부 단편화 (Internal Fragmentation)
- 할당된 블록이 페이로드보다 클 때 발생
- 원인:
- 할당자가 할당된 블록에 최소 크기를 부과
- 정렬 제약을 만족하기 위해 블록 크기 증가
- 정량화: 할당된 블록 크기와 페이로드의 차이 합계
외부 단편화 (External Fragmentation)
- 전체 가용 메모리는 충분하지만, 단일 가용 블록이 요청을 처리할 만큼 크지 않을 때 발생
- 예: 8워드 요청이 있지만 8워드가 두 개의 가용 블록에 분산되어 있는 경우
- 정량화가 어려움: 미래 요청 패턴에 의존
- 해결책: 작은 수의 큰 가용 블록을 유지하는 휴리스틱 사용
9.9.5 구현 이슈
구현 시 고려사항
- 가용 블록 조직: 가용 블록을 어떻게 추적할 것인가?
- 배치(Placement): 새로 할당된 블록을 어느 가용 블록에 배치할 것인가?
- 분할(Splitting): 가용 블록에 새 블록을 배치한 후, 나머지 부분을 어떻게 처리할 것인가?
- 병합(Coalescing): 방금 해제된 블록을 어떻게 처리할 것인가?
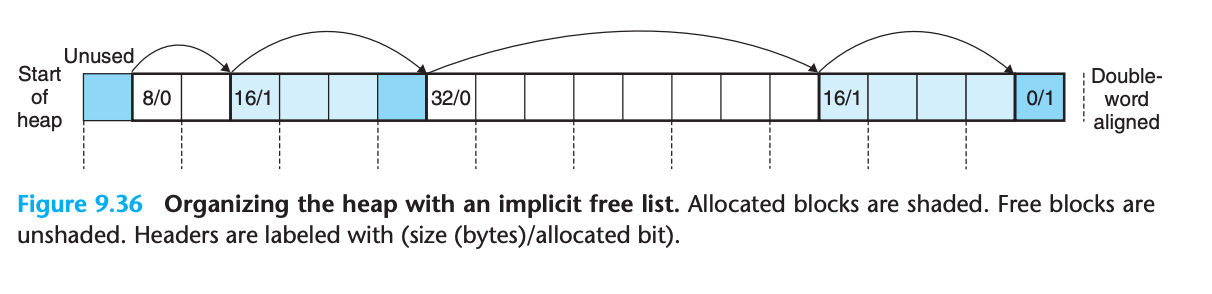
9.9.6 묵시적 가용 리스트 (Implicit Free Lists)
블록 형식
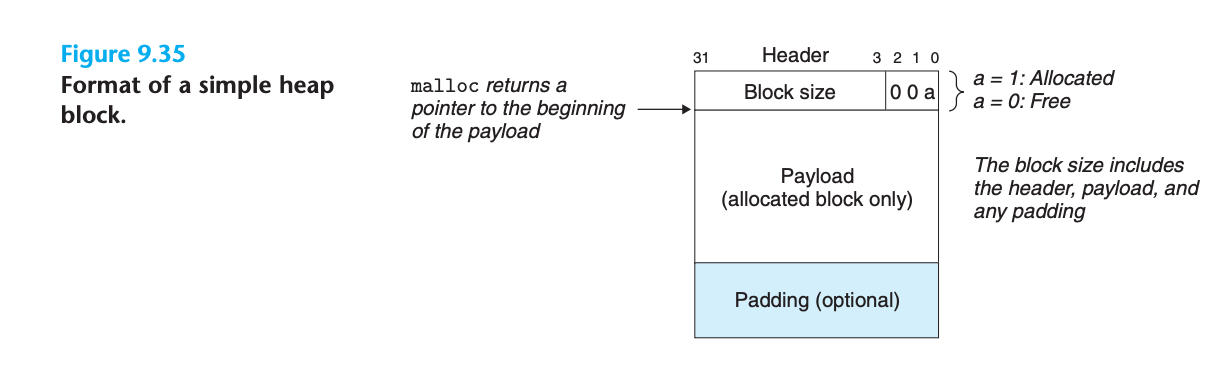
헤더 인코딩 예제
- 할당된 블록 (24바이트):
0x00000018 | 0x1 = 0x00000019 - 가용 블록 (40바이트):
0x00000028 | 0x0 = 0x00000028
묵시적 가용 리스트의 특징
- 가용 블록들이 헤더의 크기 필드에 의해 암시적으로 연결됨
- 장점: 단순함
- 단점: 가용 리스트 검색이 힙의 총 블록 수에 선형 시간 소요
최소 블록 크기
- 더블워드 정렬 요구사항: 각 블록은 2워드(8바이트)의 배수여야 함
- 최소 블록 크기: 2워드 (헤더 1워드 + 정렬 요구사항 1워드)
9.9.7 할당된 블록 배치
배치 정책 (Placement Policy)
1. 최초 적합 (First Fit)
- 가용 리스트의 처음부터 검색하여 적합한 첫 번째 가용 블록 선택
- 장점: 리스트 끝에 큰 가용 블록 유지 경향
- 단점: 리스트 앞쪽에 작은 가용 블록 조각들이 남음
2. 다음 적합 (Next Fit)
- 이전 검색이 끝난 곳부터 검색 시작
- 장점: 최초 적합보다 빠를 수 있음
- 단점: 최초 적합보다 메모리 활용도가 나쁠 수 있음
3. 최적 적합 (Best Fit)
- 모든 가용 블록을 검사하여 가장 작은 적합한 가용 블록 선택
- 장점: 일반적으로 최초 적합이나 다음 적합보다 메모리 활용도가 좋음
- 단점: 힙 전체를 철저히 검색해야 함
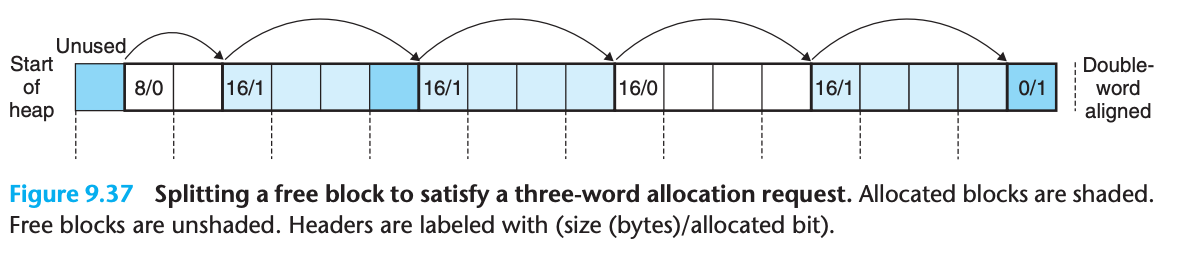
9.9.8 가용 블록 분할
분할 정책
- 전체 사용: 전체 가용 블록 사용 (간단하고 빠름, 내부 단편화 발생)
- 분할: 가용 블록을 두 부분으로 분할
- 첫 번째 부분: 할당된 블록
- 나머지 부분: 새로운 가용 블록
분할 예제
- 8워드 가용 블록에서 3워드 요청 시
- 3워드 할당 + 5워드 가용 블록으로 분할
9.9.9 추가 힙 메모리 획득
확장 과정
- 적합한 블록을 찾을 수 없으면 인접한 가용 블록들을 병합 시도
- 충분히 큰 블록이 생성되지 않으면
sbrk함수로 커널에 추가 힙 메모리 요청 - 추가 메모리를 하나의 큰 가용 블록으로 변환
- 가용 리스트에 블록 삽입
- 요청된 블록을 새 가용 블록에 배치
9.9.10 가용 블록 병합
거짓 단편화 (False Fragmentation)
- 인접한 가용 블록들이 작고 사용할 수 없는 가용 블록들로 잘려있는 현상
- 예: 3워드씩 두 개의 인접한 가용 블록이 있을 때, 4워드 요청은 실패
병합 정책
- 즉시 병합: 블록이 해제될 때마다 인접한 블록들을 병합
- 지연 병합: 나중에 병합 (예: 할당 요청이 실패할 때까지 대기)
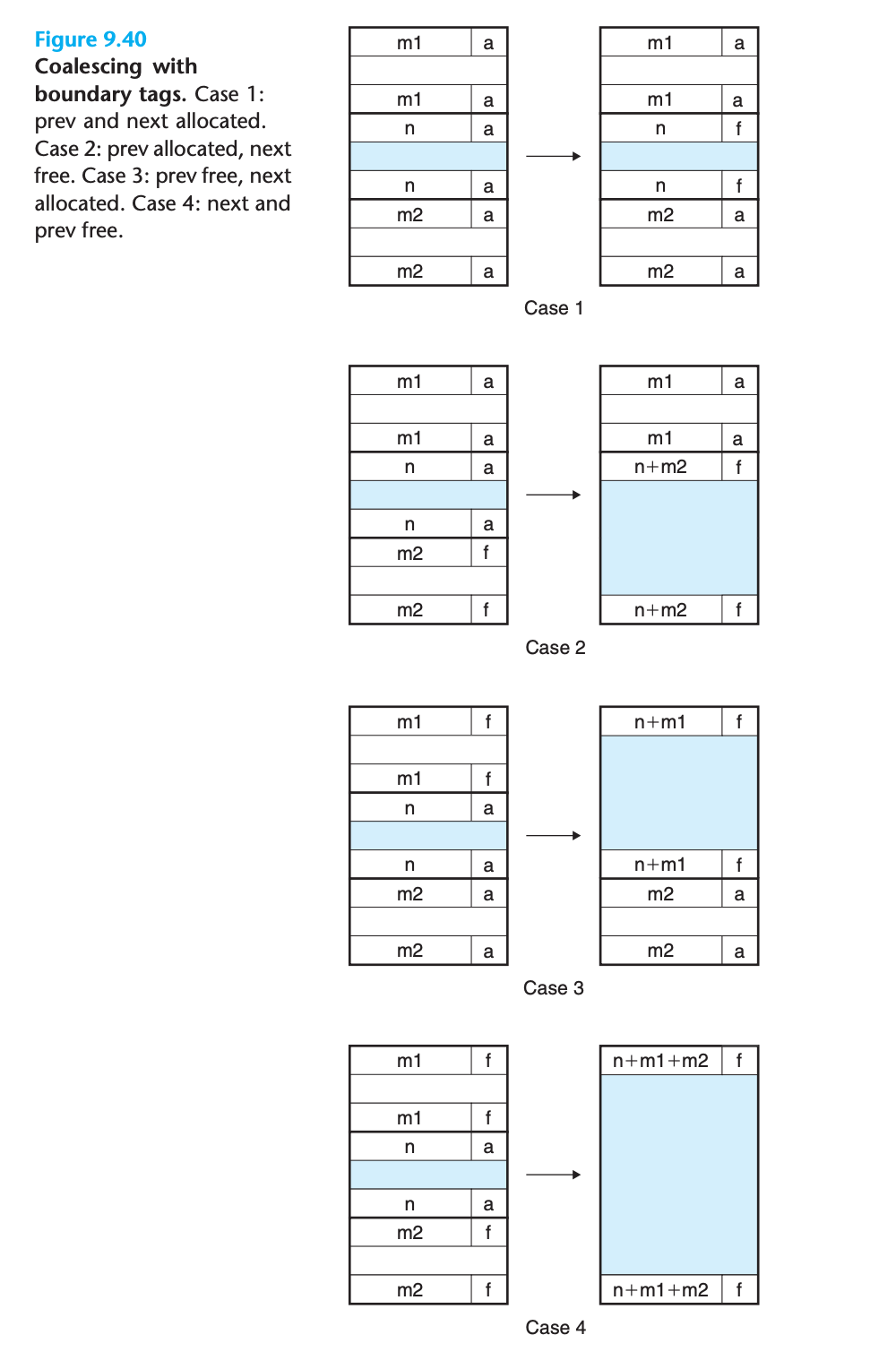
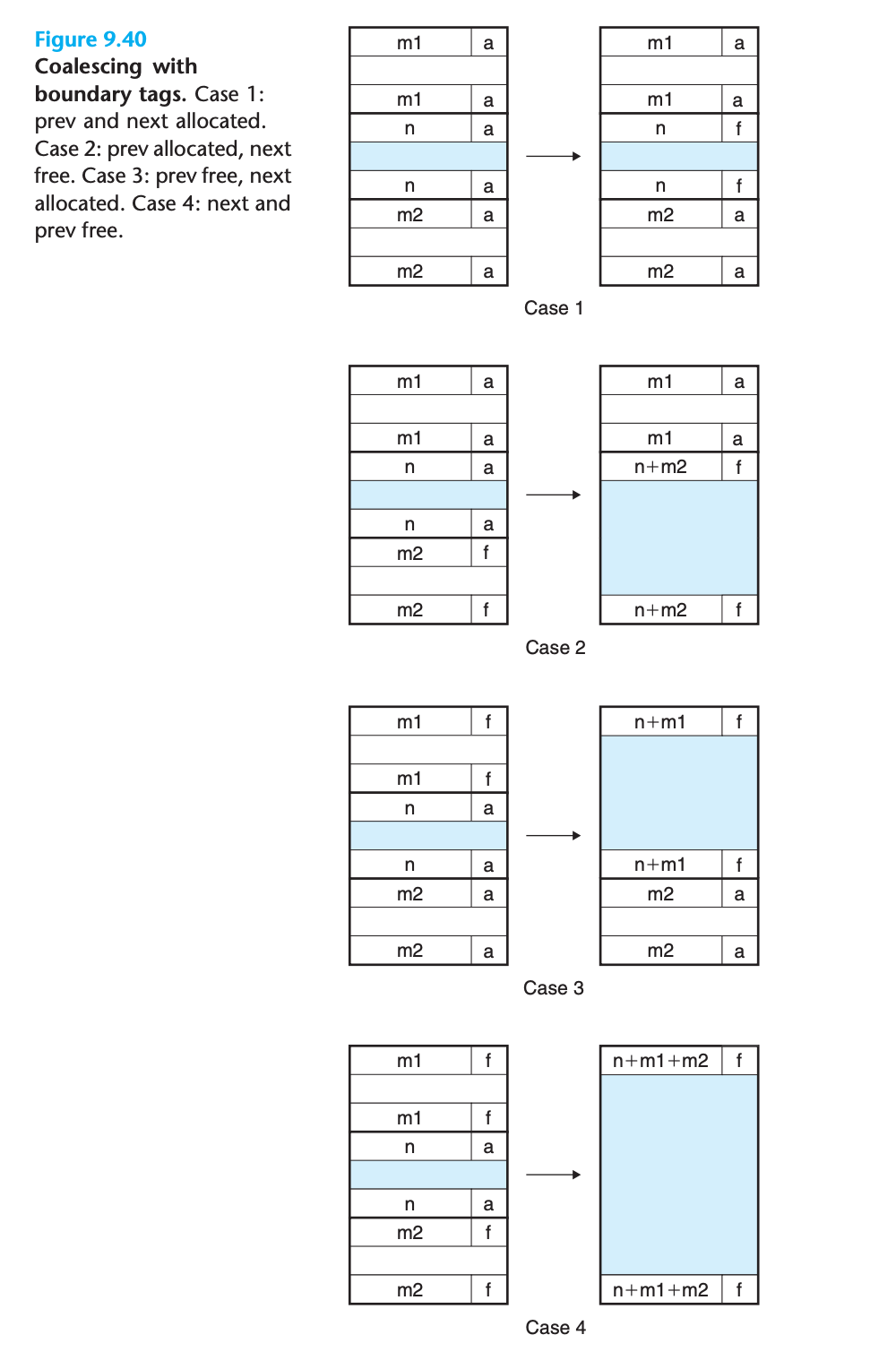
경계 태그 (Boundary Tags)
- Knuth가 개발한 기법
- 각 블록 끝에 푸터(헤더의 복사본) 추가
- 이전 블록의 시작 위치와 상태를 상수 시간에 결정 가능
병합의 네 가지 경우
- 이전과 다음 블록 모두 할당됨: 병합 불가
- 이전 블록 할당, 다음 블록 가용: 현재 블록과 다음 블록 병합
- 이전 블록 가용, 다음 블록 할당: 이전 블록과 현재 블록 병합
- 이전과 다음 블록 모두 가용: 세 블록 모두 병합
경계 태그 최적화
- 할당된 블록에는 푸터가 필요 없음
- 가용 블록만 푸터 필요
- 할당된 블록의 추가 공간을 페이로드에 사용 가능
9.9.11 경계 태그를 이용한 병합 (Coalescing with Boundary Tags)
병합 구현의 문제점
-
다음 블록과의 병합: 간단하고 효율적
- 현재 블록의 헤더가 다음 블록의 헤더를 가리킴
- 다음 블록이 가용 블럭인지 확인 가능
- 가용 가능하다면 크기를 더하고 상수 시간에 병합
-
이전 블록과의 병합: 문제 발생
- 헤더만 있는 암시적 가용 리스트에서는 현재 블록에 도달할 때까지 전체 리스트 검색 필요
- 각
free호출이 힙의 크기에 선형 시간 요구 - 더 정교한 자유 리스트 조직을 사용해도 검색 시간이 상수가 아님
경계 태그 (Boundary Tags) 기법
- 개발자: Knuth
- 목적: 이전 블록의 상수 시간 병합 가능
- 방식: 각 블록의 끝에 푸터(footer) 추가
- 푸터: 헤더의 복사본
- 동작: 현재 블록의 시작에서 한 워드 떨어진 곳에 있는 이전 블록의 푸터를 검사하여 이전 블록의 시작 위치와 상태 결정
병합의 네 가지 경우
할당자가 현재 블록을 해제할 때 존재할 수 있는 모든 경우:
- 이전과 다음 블록 모두 할당됨
- 이전 블록은 할당되고 다음 블록은 자유
- 이전 블록은 자유하고 다음 블록은 할당됨
- 이전과 다음 블록 모두 자유
각 경우별 병합 과정
경우 1: 이전과 다음 블록 모두 할당됨
- 인접한 블록들이 모두 할당되어 있으므로 병합이 불가능
- 현재 블록의 상태만 할당됨에서 자유로 변경
경우 2: 이전 블록 할당, 다음 블록 자유
- 현재 블록과 다음 블록을 병합
- 현재 블록의 헤더와 다음 블록의 푸터를 현재 블록과 다음 블록의 결합된 크기로 업데이트
경우 3: 이전 블록 자유, 다음 블록 할당
- 이전 블록과 현재 블록을 병합
- 이전 블록의 헤더와 현재 블록의 푸터를 두 블록의 결합된 크기로 업데이트
경우 4: 이전과 다음 블록 모두 자유
-
세 블록 모두를 병합하여 하나의 자유 블록 형성
-
이전 블록의 헤더와 다음 블록의 푸터를 세 블록의 결합된 크기로 업데이트
-
성능: 각 경우에서 병합은 상수 시간에 수행
경계 태그의 장단점
장점
- 단순하고 우아한 아이디어: 다양한 유형의 할당자와 자유 리스트 조직에 일반화 가능
- 상수 시간 병합: 이전 블록과의 병합을 효율적으로 수행
단점
- 메모리 오버헤드: 각 블록이 헤더와 푸터를 모두 포함해야 하므로 상당한 메모리 오버헤드 발생
- 작은 블록에서의 비효율성: 그래프 애플리케이션이
malloc과free를 반복적으로 호출하여 그래프 노드를 동적으로 생성하고 파괴하고, 각 그래프 노드가 몇 워드의 메모리만 필요하다면, 헤더와 푸터가 각 할당된 블록의 절반을 소비하게 됩니다.
경계 태그 최적화
- 목적: 할당된 블록에서 푸터의 필요성 제거
- 방식: 이전 블록의 할당/자유 비트를 현재 블록의 여분의 하위 비트 중 하나에 저장
- 결과: 할당된 블록은 푸터가 필요하지 않게 되고, 그 추가 공간을 페이로드에 사용 가능
- 제한: 자유 블록은 여전히 푸터가 필요
블록 형식 (경계 태그 사용)
병합 알고리즘 예시
static void *coalesce(void *bp) {
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
size_t size = GET_SIZE(HDRP(bp));
if (prev_alloc && next_alloc) { /* 경우 1 */
return bp;
}
else if (prev_alloc && !next_alloc) { /* 경우 2 */
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}
else if (!prev_alloc && next_alloc) { /* 경우 3 */
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
else { /* 경우 4 */
size += GET_SIZE(HDRP(PREV_BLKP(bp))) +
GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
return bp;
}요약
- 중요성: 메모리 할당자에서 매우 중요한 최적화 기법
- 효과: 효율적인 블록 병합을 가능하게 하여 외부 단편화를 줄이고 메모리 활용도를 향상
9.9.12 간단한 할당자 구현
메모리 시스템 모델 (memlib.c)
1 /* Private global variables */
2 static char *mem_heap; /* Points to first byte of heap */
3 static char *mem_brk; /* Points to last byte of heap plus 1 */
4 static char *mem_max_addr; /* Max legal heap addr plus 1*/
5
6 /*
7 * mem_init - Initialize the memory system model
8 */
9 void mem_init(void)
10 {
11 mem_heap = (char *)Malloc(MAX_HEAP);
12 mem_brk = (char *)mem_heap;
13 mem_max_addr = (char *)(mem_heap + MAX_HEAP);
14 }
15
16 /*
17 * mem_sbrk - Simple model of the sbrk function. Extends the heap
18 * by incr bytes and returns the start address of the new area. In
19 * this model, the heap cannot be shrunk.
20 */
21 void *mem_sbrk(int incr)
22 {
23 char *old_brk = mem_brk;
24
25 if ( (incr < 0) || ((mem_brk + incr) > mem_max_addr)) {
26 errno = ENOMEM;
27 fprintf(stderr, "ERROR: mem_sbrk failed. Ran out of memory...\n");
28 return (void *)-1;
29 }
30 mem_brk += incr;
31 return (void *)old_brk;
32 }전역 변수
static char *mem_heap; /* 힙의 첫 번째 바이트를 가리킴 */
static char *mem_brk; /* 힙의 마지막 바이트 + 1을 가리킴 */
static char *mem_max_addr; /* 최대 합법적 힙 주소 + 1 */mem_init 함수
- 목적: 메모리 시스템 모델 초기화
- 동작:
mem_heap = (char *)Malloc(MAX_HEAP): 힙의 시작 주소 설정mem_brk = (char *)mem_heap: 초기 brk 포인터 설정mem_max_addr = (char *)(mem_heap + MAX_HEAP): 최대 주소 설정
mem_sbrk 함수
- 목적: sbrk 함수의 간단한 모델
- 기능: 힙을 incr 바이트만큼 확장하고 새 영역의 시작 주소 반환
- 제한: 이 모델에서는 힙을 축소할 수 없음
- 동작:
old_brk = mem_brk: 현재 brk 값 저장- 오류 검사:
incr < 0또는(mem_brk + incr) > mem_max_addr mem_brk += incr: brk 포인터 업데이트return (void *)old_brk: 이전 brk 값 반환
할당자 설계
내보내는 함수
mm_init(): 할당자 초기화mm_malloc(): 블록 할당mm_free(): 블록 해제
블록 형식
- 최소 블록 크기: 16바이트
- 자유 리스트: 암시적 자유 리스트 사용
- 블록 형식: 그림 9.39에 나타난 형식 사용
힙 구조 (불변 형태)
전체 구조
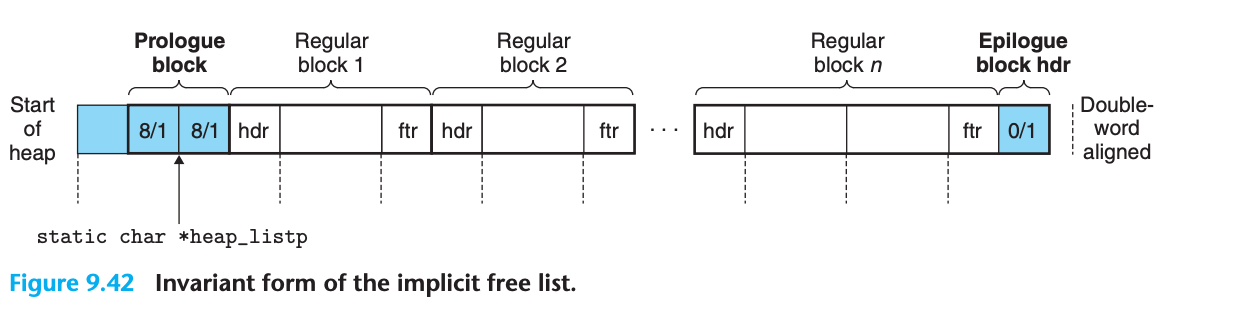
[패딩] → [프롤로그 블록] → [정규 블록들] → [에필로그 블록]각 구성 요소
패딩 (Padding)
- 크기: 1워드
- 목적: 더블워드 경계에 정렬
- 특징: 사용되지 않음
프롤로그 블록 (Prologue Block)
- 크기: 8바이트 할당된 블록
- 구성: 헤더와 푸터만 포함
- 생성: 초기화 중에 생성
- 특징: 절대 해제되지 않음
정규 블록들 (Regular Blocks)
- 개수: 0개 이상
- 생성: malloc 또는 free 호출로 생성
- 특징: 실제 사용자 데이터를 포함
에필로그 블록 (Epilogue Block)
- 크기: 0바이트 할당된 블록
- 구성: 헤더만 포함
- 위치: 힙의 끝에 항상 존재
프롤로그와 에필로그 블록의 역할
- 목적: 병합 과정에서의 엣지 조건 제거
- 효과: 특별한 경우 처리를 단순화
전역 변수
- heap_listp: 프롤로그 블록을 항상 가리키는 단일 private(static) 전역 변수
- 최적화 가능성: 프롤로그 블록 대신 다음 블록을 가리키도록 할 수 있음
기본 상수와 매크로
#define WSIZE 4 /* 워드 및 헤더/푸터 크기 */
#define DSIZE 8 /* 더블 워드 크기 */
#define CHUNKSIZE (1<<12) /* 힙 확장 크기 */
#define PACK(size, alloc) ((size) | (alloc))
#define GET(p) (*(unsigned int *)(p))
#define PUT(p, val) (*(unsigned int *)(p) = (val))
#define GET_SIZE(p) (GET(p) & ~0x7)
#define GET_ALLOC(p) (GET(p) & 0x1)
#define HDRP(bp) ((char *)(bp) - WSIZE)
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp) - WSIZE)))
#define PREV_BLKP(bp) ((char *)(bp) - GET_SIZE(((char *)(bp) - DSIZE)))초기 가용 리스트 생성
int mm_init(void) {
if ((heap_listp = mem_sbrk(4*WSIZE)) == (void *)-1)
return -1;
PUT(heap_listp, 0); /* 정렬 패딩 */
PUT(heap_listp + (1*WSIZE), PACK(DSIZE, 1)); /* 프롤로그 헤더 */
PUT(heap_listp + (2*WSIZE), PACK(DSIZE, 1)); /* 프롤로그 푸터 */
PUT(heap_listp + (3*WSIZE), PACK(0, 1)); /* 에필로그 헤더 */
heap_listp += (2*WSIZE);
if (extend_heap(CHUNKSIZE/WSIZE) == NULL)
return -1;
return 0;
}힙 확장
static void *extend_heap(size_t words) {
char *bp;
size_t size;
size = (words % 2) ? (words+1) * WSIZE : words * WSIZE;
if ((long)(bp = mem_sbrk(size)) == -1)
return NULL;
PUT(HDRP(bp), PACK(size, 0)); /* 가용 블록 헤더 */
PUT(FTRP(bp), PACK(size, 0)); /* 가용 블록 푸터 */
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); /* 새 에필로그 헤더 */
return coalesce(bp);
}블록 해제 및 병합
void mm_free(void *bp) {
size_t size = GET_SIZE(HDRP(bp));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
coalesce(bp);
}
static void *coalesce(void *bp) {
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
size_t size = GET_SIZE(HDRP(bp));
if (prev_alloc && next_alloc) { /* 경우 1 */
return bp;
}
else if (prev_alloc && !next_alloc) { /* 경우 2 */
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}
else if (!prev_alloc && next_alloc) { /* 경우 3 */
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
else { /* 경우 4 */
size += GET_SIZE(HDRP(PREV_BLKP(bp))) +
GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
return bp;
}블록 할당
void *mm_malloc(size_t size) {
size_t asize; /* 조정된 블록 크기 */
size_t extendsize; /* 적합한 블록이 없을 때 확장할 크기 */
char *bp;
if (size == 0)
return NULL;
/* 블록 크기를 오버헤드와 정렬 요구사항을 포함하도록 조정 */
if (size <= DSIZE)
asize = 2*DSIZE;
else
asize = DSIZE * ((size + (DSIZE) + (DSIZE-1)) / DSIZE);
/* 가용 리스트에서 적합한 블록 검색 */
if ((bp = find_fit(asize)) != NULL) {
place(bp, asize);
return bp;
}
/* 적합한 블록을 찾지 못함. 더 많은 메모리를 얻고 블록 배치 */
extendsize = MAX(asize, CHUNKSIZE);
if ((bp = extend_heap(extendsize/WSIZE)) == NULL)
return NULL;
place(bp, asize);
return bp;
}9.9.13 명시적 가용 리스트
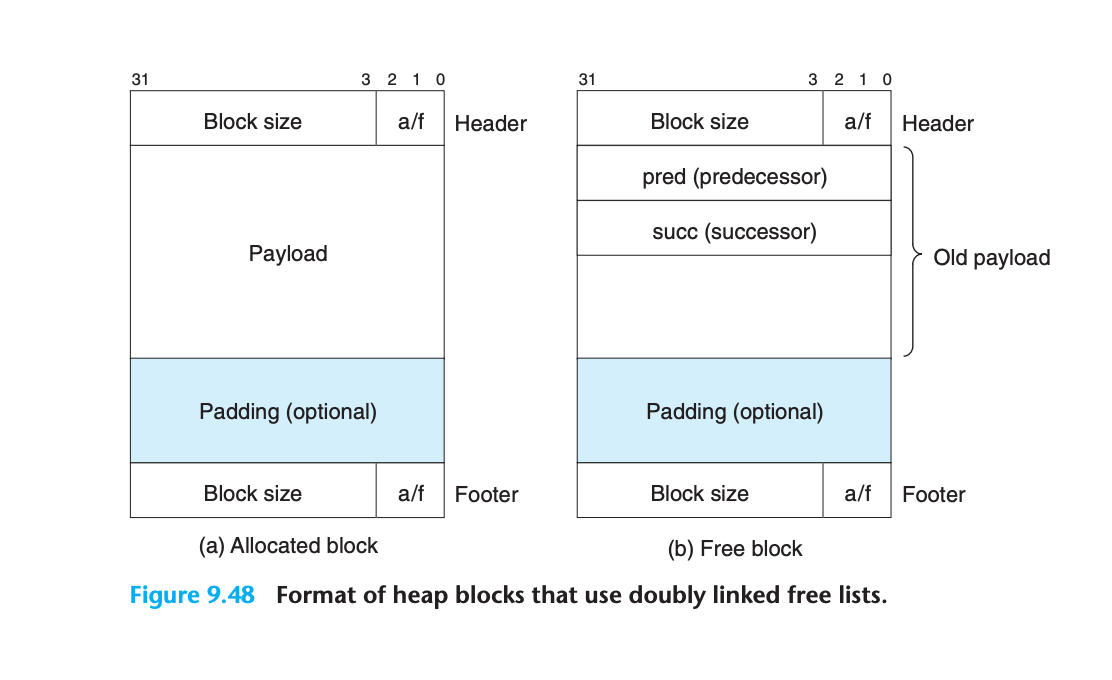
명시적 가용 리스트의 개념
- 가용 블록들을 명시적 데이터 구조로 조직
- 가용 블록의 본체는 프로그램에서 필요하지 않으므로, 데이터 구조를 구현하는 포인터들을 가용 블록 본체에 저장
- 예: 이중 연결 가용 리스트 (pred, succ 포인터 포함)
명시적 가용 리스트의 장점
- 최초 적합 할당 시간: 총 블록 수에서 가용 블록 수로 감소
- 검색 시간 단축
정렬 정책
- LIFO 순서: 새로 해제된 블록을 리스트 시작에 삽입
- 상수 시간에 해제 가능
- 경계 태그 사용 시 상수 시간에 병합 가능
- 주소 순서: 각 블록의 주소가 후속자의 주소보다 작음
- 선형 시간 검색 필요
- LIFO 순서보다 메모리 활용도가 좋음
단점
- 가용 블록이 필요한 모든 포인터, 헤더, 푸터를 포함할 만큼 커야 함
- 최소 블록 크기 증가
- 내부 단편화 가능성 증가
9.9.14 분리 가용 리스트 (Segregated Free Lists)
분리 저장소 (Segregated Storage)
- 여러 가용 리스트를 유지하여 각 리스트가 대략 같은 크기의 블록들을 보유
- 모든 가능한 블록 크기를 크기 클래스(size classes)로 분할
크기 클래스 정의 예제
-
2의 거듭제곱으로 분할:
{1}, {2}, {3, 4}, {5–8}, ..., {1,025–2,048}, {2,049–4,096}, {4,097–∞} -
작은 블록을 개별 크기 클래스로 할당:
{1}, {2}, {3}, ..., {1,023}, {1,024}, {1,025–2,048}, {2,049–4,096}, {4,097–∞}
작동 방식
- 크기 클래스당 하나의 가용 리스트를 배열로 유지
- 크기 n의 블록이 필요하면 적절한 가용 리스트 검색
- 적합한 블록을 찾지 못하면 다음 리스트 검색
단순 분리 저장소 (Simple Segregated Storage)
- 각 크기 클래스의 가용 리스트는 같은 크기의 블록들로 구성
- 예: {17–32} 크기 클래스는 모두 크기 32의 블록들로 구성
장점:
- 할당과 해제가 모두 상수 시간
- 같은 크기 블록, 분할 없음, 병합 없음으로 인한 메모리 오버헤드 최소
- 할당된 블록의 크기를 주소에서 추론 가능
- 할당된 블록에 헤더나 푸터 불필요
- 단일 연결 리스트만 필요
단점:
- 내부 및 외부 단편화에 취약
- 가용 블록이 분할되지 않아 내부 단편화 가능
- 특정 참조 패턴이 극단적인 외부 단편화 유발 가능
분리 적합 (Segregated Fits)
- 각 가용 리스트는 크기 클래스와 연관되며 명시적 또는 암시적 리스트로 조직
- 각 리스트는 크기 클래스의 구성원인 잠재적으로 다른 크기의 블록들을 포함
작동 방식:
1. 요청의 크기 클래스 결정
2. 적절한 가용 리스트에서 최초 적합 검색
3. 적합한 블록을 찾으면 (선택적으로) 분할하고 조각을 적절한 가용 리스트에 삽입
4. 적합한 블록을 찾지 못하면 다음 큰 크기 클래스의 가용 리스트 검색
5. 블록 해제 시 병합하고 적절한 가용 리스트에 배치
장점:
- 검색이 힙의 특정 부분으로 제한되어 검색 시간 단축
- 분리 가용 리스트의 단순한 최초 적합 검색이 전체 힙의 최적 적합 검색을 근사
버디 시스템 (Buddy Systems)
- 분리 적합의 특별한 경우로, 각 크기 클래스가 2의 거듭제곱
- 기본 아이디어: 2^m 워드 힙이 주어지면, 각 블록 크기 2^k (0 ≤ k ≤ m)에 대해 별도의 가용 리스트 유지
작동 방식:
1. 요청된 블록 크기를 가장 가까운 2의 거듭제곱으로 반올림
2. 크기 2^k의 블록 할당을 위해 k ≤ j ≤ m인 첫 번째 사용 가능한 크기 2^j 블록 찾기
3. j = k이면 완료, 그렇지 않으면 j = k가 될 때까지 블록을 반으로 분할
4. 분할 과정에서 남은 절반(버디)을 적절한 가용 리스트에 배치
5. 크기 2^k의 블록 해제 시 가용 버디와 계속 병합
버디 주소 계산:
- 크기 32바이트 블록의 주소:
xxx...x00000 - 버디 주소:
xxx...x10000 - 블록과 버디의 주소는 정확히 한 비트 위치에서 다름
장점:
- 빠른 검색과 병합
단점: - 블록 크기의 2의 거듭제곱 요구사항이 상당한 내부 단편화 유발
- 일반적인 워크로드에는 부적절하지만, 블록 크기가 미리 2의 거듭제곱으로 알려진 특정 애플리케이션에는 매력적
가비지 컬렉션의 개념
- 가비지 컬렉터: 더 이상 프로그램에서 필요하지 않은 할당된 블록을 자동으로 해제하는 동적 저장소 할당자
- 가비지: 더 이상 필요하지 않은 할당된 블록들
- 가비지 컬렉션: 힙 저장소를 자동으로 회수하는 과정
가비지 컬렉션의 역사
- 1960년대 초 MIT의 John McCarthy가 개발한 Lisp 시스템에서 시작
- Java, ML, Perl, Mathematica 등 현대 언어 시스템의 중요한 부분
- 활발하고 중요한 연구 영역
가비지 컬렉터 기본 개념
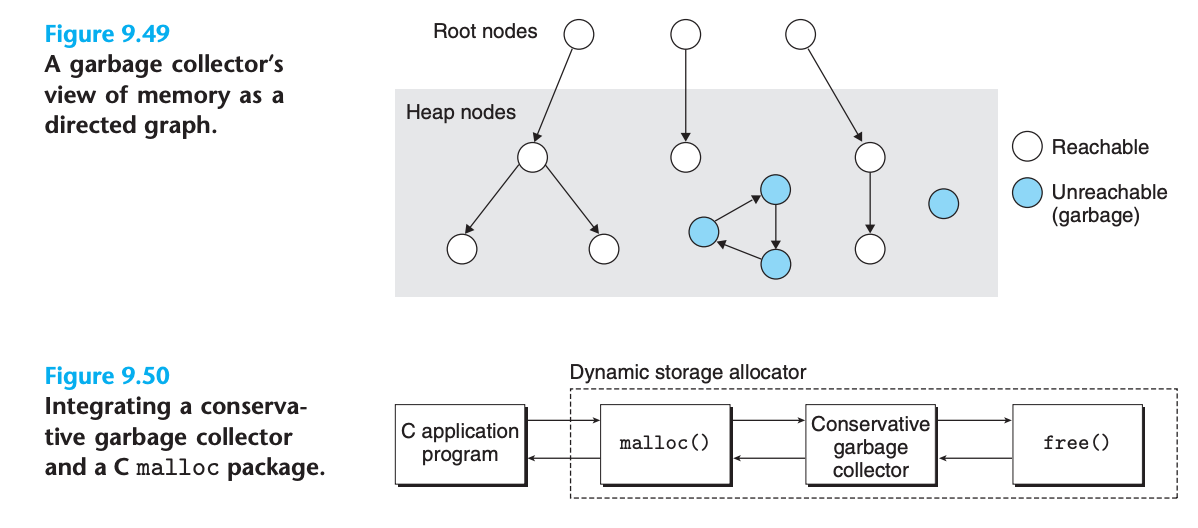
메모리 뷰
- 가비지 컬렉터는 메모리를 방향성 도달 가능성 그래프로 봄
- 그래프의 노드들은 루트 노드 집합과 힙 노드 집합으로 분할
- 각 힙 노드는 힙의 할당된 블록에 대응
- 방향성 엣지 p → q: 블록 p의 어떤 위치가 블록 q의 어떤 위치를 가리킴
도달 가능성
- 도달 가능한 노드: 어떤 루트 노드에서 p로의 방향성 경로가 존재하는 노드
- 도달 불가능한 노드: 애플리케이션이 다시 사용할 수 없는 가비지
- 가비지 컬렉터의 역할: 도달 가능성 그래프의 표현을 유지하고 주기적으로 도달 불가능한 노드들을 회수
보수적 가비지 컬렉터
- ML, Java와 같은 언어: 포인터 생성 및 사용 방식에 대한 엄격한 제어로 정확한 도달 가능성 그래프 표현 유지 가능
- C, C++와 같은 언어: 일반적으로 정확한 도달 가능성 그래프 표현 유지 불가능 → 보수적 가비지 컬렉터
- 보수적: 각 도달 가능한 블록은 올바르게 도달 가능으로 식별되지만, 일부 도달 불가능한 노드들이 잘못 도달 가능으로 식별될 수 있음
Mark&Sweep 가비지 컬렉터
기본 구성
- 마크 단계 (Mark Phase): 루트 노드의 모든 도달 가능하고 할당된 후손들을 마크
- 스윕 단계 (Sweep Phase): 마크되지 않은 각 할당된 블록을 해제
- 마크 비트: 블록 헤더의 여분 하위 비트 중 하나를 사용하여 블록이 마크되었는지 표시
필요한 함수들
typedef void *ptr;
ptr isPtr(ptr p); // p가 할당된 블록의 어떤 워드를 가리키면 해당 블록의 시작 포인터 반환, 아니면 NULL
int blockMarked(ptr b); // 블록 b가 이미 마크되었으면 true 반환
int blockAllocated(ptr b); // 블록 b가 할당되었으면 true 반환
void markBlock(ptr b); // 블록 b를 마크
int length(ptr b); // 블록 b의 길이를 워드 단위로 반환 (헤더 제외)
void unmarkBlock(ptr b); // 블록 b의 상태를 마크됨에서 마크되지 않음으로 변경
ptr nextBlock(ptr b); // 힙에서 블록 b의 후속자 반환마크 함수 (Mark Function)
void mark(ptr p) {
if ((b = isPtr(p)) == NULL)
return;
if (blockMarked(b))
return;
markBlock(b);
len = length(b);
for (i=0; i < len; i++)
mark(b[i]);
return;
}마크 함수 동작 과정
- 포인터 검증: p가 할당된 블록을 가리키는지 확인
- 이미 마크된 블록: 이미 마크된 블록이면 즉시 반환
- 블록 마크: 블록을 마크 상태로 설정
- 재귀적 마크: 블록 내의 각 워드에 대해 재귀적으로 mark 함수 호출
스윕 함수 (Sweep Function)
void sweep(ptr b, ptr end) {
while (b < end) {
if (blockMarked(b))
unmarkBlock(b);
else if (blockAllocated(b))
free(b);
b = nextBlock(b);
}
return;
}스윕 함수 동작 과정
- 힙 순회: 힙의 모든 블록을 순회
- 마크된 블록: 마크된 블록의 마크를 해제 (다음 가비지 컬렉션을 위해)
- 마크되지 않은 할당된 블록: 가비지로 간주하여 해제
- 다음 블록: 다음 블록으로 이동
Mark&Sweep 과정
마크 단계
- 루트 노드 처리: 각 루트 노드에 대해 mark 함수 한 번씩 호출
- 도달 가능성 확인: p가 할당되고 마크되지 않은 힙 블록을 가리키는지 확인
- 재귀적 마크: 블록을 마크하고 블록 내의 각 워드에 대해 재귀적으로 마크
- 결과: 마크 단계 끝에 마크되지 않은 할당된 블록은 도달 불가능한 가비지
스윕 단계
- 단일 호출: sweep 함수를 한 번 호출
- 가비지 회수: 마크되지 않은 할당된 블록들(가비지)을 해제
- 마크 해제: 마크된 블록들의 마크를 해제하여 다음 가비지 컬렉션 준비
Mark&Sweep 예제 (그림 9.52)
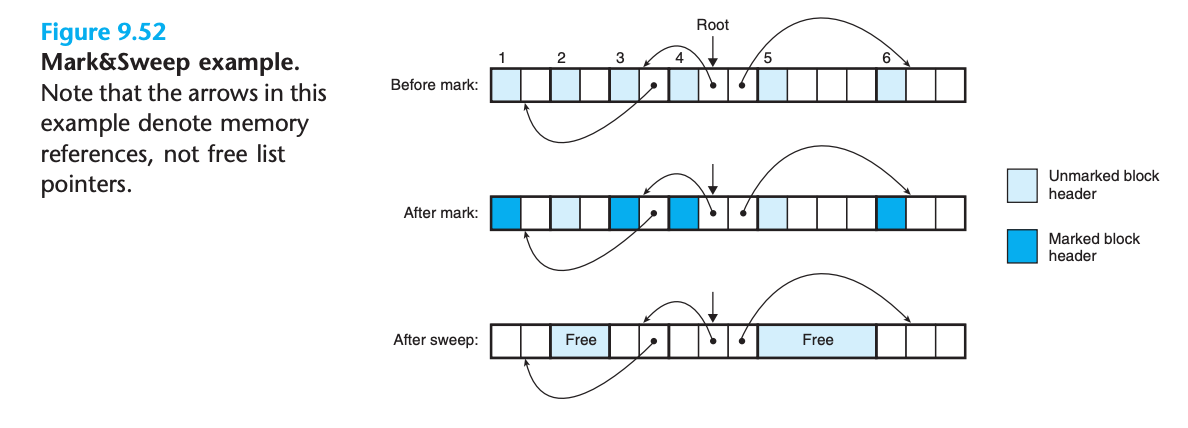
초기 상태
- 힙 구성: 6개의 할당된 블록 (모두 마크되지 않음)
- 포인터 관계:
- 블록 3: 블록 1을 가리킴
- 블록 4: 블록 3과 6을 가리킴
- 루트: 블록 4를 가리킴
마크 단계 후
- 마크된 블록: 1, 3, 4, 6 (루트에서 도달 가능)
- 마크되지 않은 블록: 2, 5 (루트에서 도달 불가능)
스윕 단계 후
- 해제된 블록: 블록 2와 5가 자유 리스트로 회수됨
- 결과: 도달 불가능한 블록들이 가비지로 정리됨
균형 이진 트리 구조 (그림 9.53)

할당된 블록의 균형 이진 트리
- 목적: 할당된 블록들의 집합을 효율적으로 관리
- 구조:
- 왼쪽 서브트리: 더 작은 주소의 블록들
- 오른쪽 서브트리: 더 큰 주소의 블록들
- 추가 필드: 각 할당된 블록의 헤더에 left와 right 포인터 추가
isPtr 함수에서의 활용
- 이진 검색: 할당된 블록들을 이진 검색으로 효율적으로 검색
- 주소 기반: 각 단계에서 블록의 크기 필드를 사용하여 p가 블록 범위 내에 있는지 확인
- 성능: O(log n) 시간 복잡도로 할당된 블록 검색
Mark&Sweep의 특징
장점
- 정확성: 루트에서 도달 가능한 모든 노드가 마크됨을 보장
- 안전성: 도달 가능한 블록이 잘못 해제되는 것을 방지
- 단순성: 구현이 비교적 간단하고 이해하기 쉬움
단점
- 보수적: 실제로는 도달 불가능한 블록들을 잘못 마크할 수 있음
- 성능: 전체 힙을 순회해야 하므로 시간이 오래 걸림
- 메모리 오버헤드: 균형 이진 트리 구조를 위한 추가 포인터 필요
C 프로그램에서의 보수적 특성
근본적 이유
- 타입 정보 부재: C 언어가 메모리 위치에 타입 정보를 태그하지 않음
- 포인터 식별 어려움: 스칼라 값(int, float)이 우연히 유효한 주소 값을 가질 수 있음
예시 상황
- int 값과 포인터 혼동: 할당된 블록에 int 값이 저장되어 있는데, 그 값이 우연히 다른 할당된 블록의 주소와 일치
- 보수적 처리: 컬렉터는 이를 포인터로 잘못 해석하여 해당 블록을 도달 가능으로 마크
- 결과: 실제로는 도달 불가능한 블록이 가비지로 회수되지 않음
영향
- 정확성: 애플리케이션 프로그램의 정확성에는 영향 없음
- 메모리 효율성: 불필요한 외부 단편화 발생 가능
- 성능: 가비지 컬렉션 효율성 감소
9.11 C 프로그램의 일반적인 메모리 관련 버그
9.11.1 잘못된 포인터 역참조
- 가상 주소 공간의 큰 구멍들을 역참조하려고 할 때 세그멘테이션 예외 발생
- 읽기 전용 영역에 쓰기 시도 시 보호 예외 발생
전형적인 scanf 버그:
// 올바른 방법
scanf("%d", &val)
// 잘못된 방법
scanf("%d", val) // val의 내용을 주소로 해석하여 해당 위치에 쓰기 시도9.11.2 초기화되지 않은 메모리 읽기
- bss 메모리 위치는 로더에 의해 항상 0으로 초기화되지만, 힙 메모리는 그렇지 않음
잘못된 가정:
int *y = (int *)Malloc(n * sizeof(int));
// y가 0으로 초기화되었다고 잘못 가정
for (i = 0; i < n; i++)
for (j = 0; j < n; j++)
y[i] += A[i][j] * x[j]; // 초기화되지 않은 값에 더하기해결책:
// 명시적으로 0으로 초기화
for (i = 0; i < n; i++)
y[i] = 0;
// 또는 calloc 사용
int *y = (int *)calloc(n, sizeof(int));9.11.3 스택 버퍼 오버플로우 허용
void bufoverflow() {
char buf[64];
gets(buf); // 스택 버퍼 오버플로우 버그
return;
}해결책:
void bufoverflow() {
char buf[64];
fgets(buf, sizeof(buf), stdin); // 입력 문자열 크기 제한
return;
}9.11.4 포인터와 포인터가 가리키는 객체의 크기가 같다고 가정
/* Create an nxm array */
int **makeArray2(int n, int m)
{
int i;
int **A = (int **)Malloc(n * sizeof(int *)); // 잘못됨: sizeof(int *)여야 함
for (i = 0; i <= n; i++)
A[i] = (int *)Malloc(m * sizeof(int));
return A;
}문제점:
- 포인터와 int의 크기가 다른 기계에서 배열 끝을 넘어서 쓰기
- 나중에 블록 해제 시 병합 코드가 실패할 수 있음
9.11.5 Off-by-One 에러 만들기
for (i = 0; i <= n; i++) // 잘못됨: i < n이어야 함
A[i] = (int *)Malloc(m * sizeof(int));9.11.6 포인터가 가리키는 객체 대신 포인터 자체를 참조
*size--;
1 int *binheapDelete(int **binheap, int *size)
2 {
3 int *packet = binheap[0];
4
5 binheap[0] = binheap[*size - 1];
6 *size--; // 잘못됨: 포인터 자체를 감소시킴
7 heapify(binheap, *size, 0);
8 return(packet);
9 }올바른 방법:
(*size)--; // 포인터가 가리키는 정수 값을 감소시킴9.11.7 포인터 산술 연산 오해
p += sizeof(int); // 잘못됨: 4바이트씩 증가올바른 방법:
p++; // 포인터가 가리키는 객체 크기만큼 증가9.11.8 존재하지 않는 변수 참조
int *stackref() {
int val;
return &val; // 스택 프레임이 팝된 후 유효하지 않은 변수 참조
}9.11.9 해제된 힙 블록의 데이터 참조
free(x);
y = (int *)Malloc(m * sizeof(int));
for (i = 0; i < m; i++)
y[i] = x[i]++; // 해제된 블록의 데이터 참조9.11.10 메모리 누수 도입
void leak(int n) {
int *x = (int *)Malloc(n * sizeof(int));
return; // x는 이 시점에서 가비지
}문제점:
leak이 자주 호출되면 힙이 가비지로 점진적으로 채워짐- 데몬이나 서버와 같은 프로그램에서 특히 심각
9.12 요약
가상 메모리의 중요성
- 가상 메모리는 메인 메모리의 추상화
- 가상 주소 지정을 통한 간접 참조
- 하드웨어와 소프트웨어의 긴밀한 협력으로 주소 변환
가상 메모리의 세 가지 중요한 기능
- 자동 캐싱: 디스크에 저장된 가상 주소 공간의 최근 사용 내용을 메인 메모리에 자동 캐싱
- 메모리 관리 단순화: 링킹, 프로세스 간 데이터 공유, 프로세스 메모리 할당, 프로그램 로딩 단순화
- 메모리 보호 단순화: 모든 페이지 테이블 엔트리에 보호 비트 통합
동적 메모리 할당
- 명시적 할당자: 애플리케이션이 명시적으로 메모리 블록 해제 필요
- 암시적 할당자: 가비지 컬렉터가 자동으로 사용되지 않는 블록 해제
- malloc 패키지: C 표준 라이브러리의 명시적 할당자
메모리 관리의 어려움
- C 프로그래머에게 메모리 관리와 사용은 어렵고 오류가 발생하기 쉬운 작업
- 메모리 관련 버그는 시간과 공간에서 멀리 떨어진 곳에서 나타나는 경향
- 일반적인 오류: 잘못된 포인터 역참조, 초기화되지 않은 메모리 읽기, 스택 버퍼 오버플로우, 포인터 산술 연산 오해, 메모리 누수 등
가비지 컬렉션
- Mark&Sweep 알고리즘: McCarthy의 원래 알고리즘
- 기존 malloc 패키지 위에 구축하여 C/C++ 프로그램에 가비지 컬렉션 제공 가능
- 보수적 가비지 컬렉터: C 언어의 타입 정보 부재로 인해 정확한 도달 가능성 그래프 유지 불가능
- 도달 가능성 그래프: 메모리를 방향성 그래프로 봄
- 마크 단계: 루트 노드의 모든 도달 가능한 후손들을 마크
- 스윕 단계: 마크되지 않은 할당된 블록들을 해제
할당자 설계 전략
- 암시적 가용 리스트: 단순하지만 검색 시간이 선형
- 명시적 가용 리스트: 검색 시간 단축, 정렬 정책에 따른 성능 차이
- 분리 가용 리스트: 여러 크기 클래스로 분할하여 검색 시간 단축
- 버디 시스템: 2의 거듭제곱 크기 클래스, 빠른 검색과 병합
성능 목표
- 처리량 최대화: 단위 시간당 완료하는 요청 수 최대화
- 메모리 활용도 최대화: 피크 활용도 최대화
- 단편화 최소화: 내부 단편화와 외부 단편화 관리
키워드 공부
demand-zero memory
- 프로세스가 처음 어떤 메모리 페이지를 접근할 때, 그 페이지를 자동으로 0으로 초기화해서 제공하는 기법
프로세스는 malloc()이나 변수 선언 등을 통해 메모리를 요청하지만,
OS는 바로 물리 메모리를 할당하지 않음 (→ 가상 주소만 할당) - 실제 메모리 할당은?
- 프로세스가 그 페이지에 처음으로 접근할 때 (예: 읽기/쓰기)
→ 페이지 폴트(Page Fault) 발생
→ OS가 실제 물리 메모리를 할당하고, 그 메모리를 모두 0으로 초기화
DMA
DMA의 동작 방식
- CPU가 DMA 컨트롤러에게 다음을 알려줌:
- 어떤 장치가 데이터를 읽거나 쓸 건지
- 어느 메모리 주소에 데이터를 쓸 건지
- 전송할 데이터 크기
- CPU는 이제 다른 작업을 수행
- DMA 컨트롤러가 장치 ↔ 메모리 간 직접 데이터 전송
- 전송 완료 시 DMA가 인터럽트를 통해 CPU에게 알림
이더넷
- 이더넷(Ethernet)은 컴퓨터 간 데이터를 유선으로 주고받기 위한 표준 통신 기술
- 주로 LAN(Local Area Network, 근거리 통신망)에서 사용
- 각 장비(노드)는 고유한 MAC 주소를 갖고 있음
- 데이터를 보낼 때:
- 송신자가 수신자의 MAC 주소를 포함해서 프레임을 전송
- 네트워크 스위치가 MAC 주소 기반으로 전송 경로 결정