지난번에는 SECS-I 에 관해 알아봤다.


오늘은 SECS-I 나 HSMS 위에서 상위 계층으로써 메시지의 구조를 약속한 규약인 SECS-II에 대해 알아보자...
SEMI E5 : 실제 송수신되는 메시지의 통신 내용(Content), Data 영역에 대한 프로토콜인 SECS-II 에 대한 표준
SECS-II는 SECS-I나 HSMS 통신 위에서 캡슐화되는 메시지의 구조와 표현 방식을 정의하는 포맷 규약이다
처음 메시지 구조를 봤을 때 xml 이나 JSON 과 비슷하다는 생각을 했다.
XML이나 JSON과 유사하지만, 중요한 차이점이 있다면 XML이나 JSON은 단순히 메시지의 구조만 정의하는 반면, SECS-II의 메시지는 사전에 정의된 특정한 의미를 포함한다.
✅ SECS-II와 JSON/XML 비교
| 항목 | SECS-II | JSON / XML |
|---|---|---|
| 역할 | 장비 ↔ 호스트 간 메시지 형식 정의 | 시스템 간 데이터 포맷 정의 |
| 형식 | SxFy 구조 (e.g., S1F1, S2F41 등) | Key-Value 구조, 태그 구조 |
| 전송 방법 | SECS-I 또는 HSMS로 전송 | HTTP, WebSocket, MQTT 등 다양 |
| 표현 방식 | 바이너리 형식 + 데이터 타입 명시 | 문자열 기반 |
| 의미 부여 | 각 SxFy는 특정한 의미를 가짐 (e.g., 상태 요청, 커맨드 전송 등) | 의미는 시스템 정의에 따라 다름 |
| 표준화 여부 | SEMI 표준(SEMI E5) | JSON은 사실상 표준, XML은 W3C 표준 |
그렇다면 왜 JSON/XML 같이 널리 쓰이는 포맷으로 통신하고 특정한 의미. 즉 시스템 정의만 따로 해서 사용하면 되는데 왜 SECS-II 라는 표준 규약을 사용할까?
그거야 secs I 와 secs II가 같은 시기에 개발되어서….라고도 할 수 있지만
적은 오버헤드와 고밀도로 데이터를 전송할 수 있기 때문에.. 가 될것같다.
의미를 포함한 데이터 포맷을 지정해뒀기에 하드웨어 수준에서 이를 해석하는데 오버헤드가 적다.
아래 블로그에 이러한 비교가 잘 되어있음.
애초에 SECS 프로토콜을 설계할때에 밀접하게 설계해뒀기에 SECS-I 위에서 오버헤드가 가장 적다.
보통 osi 7 layer에서 캡슐화를 할때에는
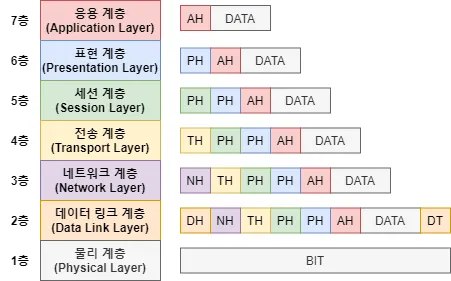
이런식으로 상위 레이어의 헤더 + 데이터 = 하위 레이어의 데이터 가 되는 경우가 많다.
그래서 캡슐화 시에 상위 레이어로부터 받은 헤더, 데이터 정보들은 하위 레이어들의 해석에 아무런 의미가 없다.
하지만HSMS + SECS II나SECS I + SECS II는 다르다.
얘는 HSMS의 헤더와 데이터가 SECS- II 의 포맷에 포함되어있음.
그래서 SECS - II 메시지를 파싱하려면 HSMS의 헤더랑 데이터 둘다 봐야한다.
1. Stream / Function
SECS-II 메시지는 스트림과 펑션에 의해 구분된다.
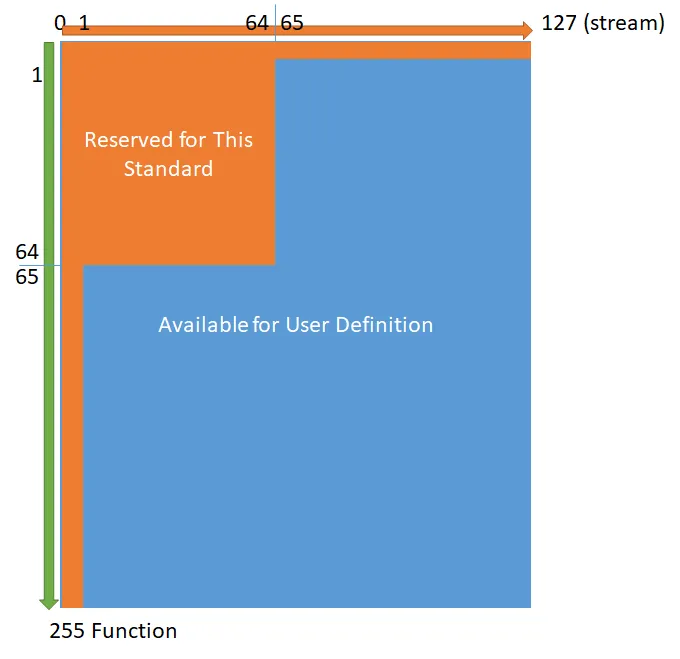
- Stream : 유사한 특성을 갖는 메시지의 그룹, 예약영역 + 사용자 영역 합쳐서 S1 ~ S127 까지 있다.
- Function : 각 스트림 내에서 특정한 기능을 하는 메시지, 예약영역 + 사용자 영역 합쳐서 F1 ~ F255 까지 있다
- Stream 안에서 각 세부 기능에 관련된 개별 Msg
- Primary Msg는 항상 홀수의 Function 번호를 갖는다.
- Reply (Secondary) Msg는 Primary Msg Function 번호에 1을 더한 수로 모두 짝수이다.
- Function 번호는 '0'은 Message Transaction 취소를 위해 예약되어 있다.
SEMI 에서는 특정한 의미를 갖는 SECS-II 메시지들을 이미 많이 만들어 두고 사용하고 있고 사용자 정의도 가능
💡예약 영역
- 스트림은 S1 ~ S64 까지, 펑션은 F1 ~ F64 까지
SYF0: (All Stream, Function 0) ; Message Transaction 취소S0FY: (Stream 0, All Function)
사용자 정의 영역
- S64 ~ S127 (예약되지 않은 Stream)의 경우 사용자 정의 가능한 펑션은 F1 ~ F255 까지
- S1 ~ S63 스트림(이미 예약된 Stream)의 경우 사용자 정의 가능한 펑션은 F65 ~ F255 까지
이전에 공부한 SECS-I 10 Byte 헤더의 3번, 4번 Byte가 Stream과 Function을 가리킵니다.
Stream이 예약영역과 사용자 영역을 합쳐 S1~S127까지 2^7개 사용 가능하고, Function이 F1~F256까지 사용 가능한 이유는 SECS-I 헤더의 3번 Byte에 W-bit(전송되는 메시지에 대한 송신측의 응답 여부를 표시하는 비트)가 할당되었기 때문으로 보입니다.
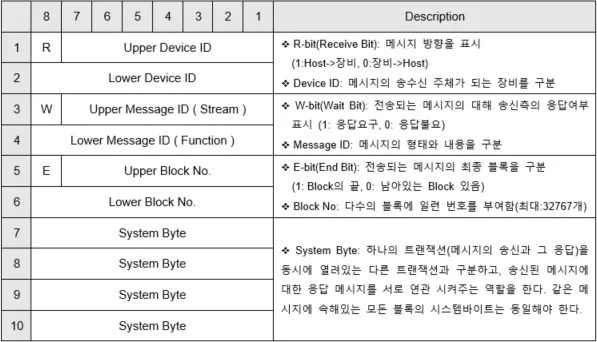
이후 배울 HSMS에서는 Stream 과 Function 을 HSMS 헤더의 B 영역인 ‘메시지헤더’ 라는 곳에서 볼 수 있다. 해당 B 영역이 SECS-I 의 헤더 구조와 아주 유사하다.
다만 Ptype과 Stype 이라고 하는 부분이 다른데 그건 **해당 블로그 참조**
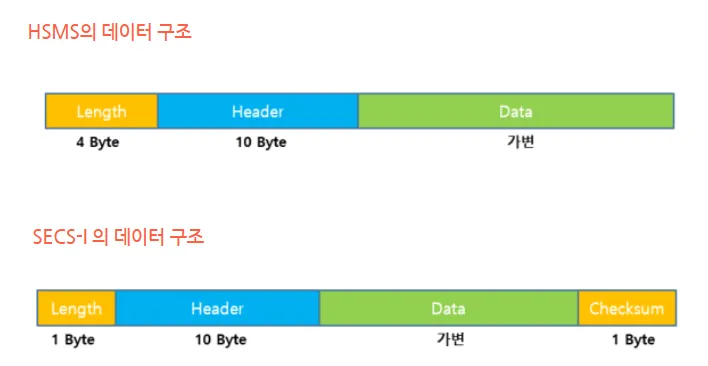
HSMS 헤더의 B 영역 데이터 구조

2. SECS 프로토콜의 Data 형식과 구조
SECS 프로토콜에서 통신되는 데이터들은 일반적으로 다음과 같은 구조를 가진다.
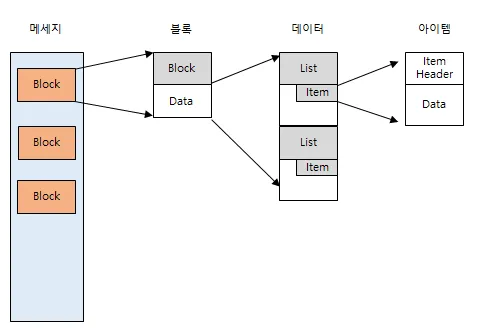
1. Block 의 구조
-
SECS -I 의 경우 Block 구조
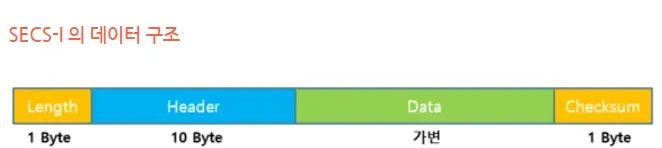

checksum : RS-232 시리얼 통신 위에서 돌아가기 때문에 Checksum 으로 Header와 Data 영역의 바이트 값을 이진 덧셈처리하여 CheckSum을 통해 오류 검출한다.
- HSMS의 경우 Block 의 구조는 아래와 같다.
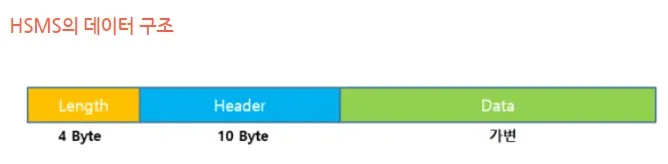 HSMS 의 경우 TCP/IP 위에서 돌아가기 때문에 (TCP가 체크섬을 통해 무결성을 체크해주잖슴~ 참고: 6~9 ) CheckSum 을 가지지 않는다.
HSMS 의 경우 TCP/IP 위에서 돌아가기 때문에 (TCP가 체크섬을 통해 무결성을 체크해주잖슴~ 참고: 6~9 ) CheckSum 을 가지지 않는다.
2. Data의 구조
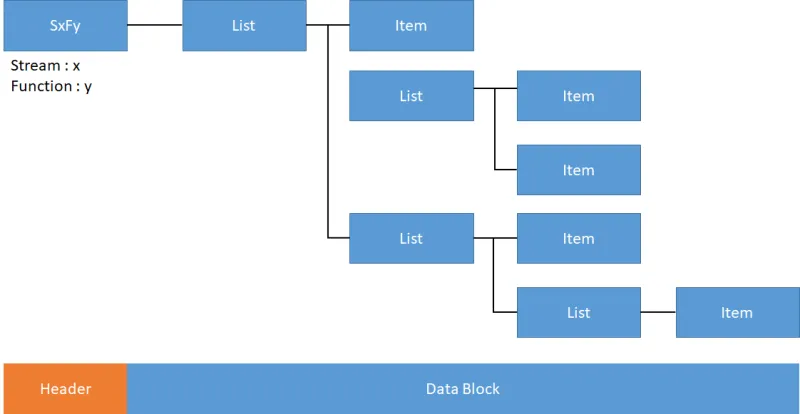
- Data는 Header에 정의된 Stream과 Function 정보에 의해 정의되며 여러개의 List와 Item이 트리구조로 구성되어있다.
- 다만 SECS-II Msg는 항상 Data 영역을 포함하고 있진 않다. Header 의 스트림과 펑션으로만 정의되는 예약된 메시지들이 존재하기 때문이다.
정리하자면
SECS-II는 Length + Header + Data (SECS-I를 이용할경우 + Checksum 추가)로 구성되어있으며
Length (HSMS - 4byte, SECS-I - 1byte)와 Header (10 byte)는 고정이고
Data영역은 가변적으로 구성되어있다.
3. List와 Item 의 구조
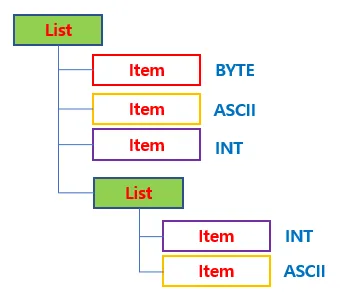
-
LIST
-
다른 ITEM을 포함하는 컨테이너 역할
-
어떤 값을 가지는게 아니라 다른 ITEM들을 담는 그릇이라고 생각하면 됨
-
LIST 안에는 또 다른 LIST를 넣을 수 있다. (재귀적으로 트리 구조 형성 가능)
-
예시
// list 안에 두개의 아이템이 들어있음. <L [2] <U1 1> // = 부호 없는 1바이트 정수 1 <A "OK"> // = ASCII 문자열 OK >
-
-
ITEM
-
실제 데이터를 가지는 최소단위
-
항상 "형식(Type)" + "길이(Length)" + "값(Value)" 구조로 구성되어 있음
-
데이터 구조
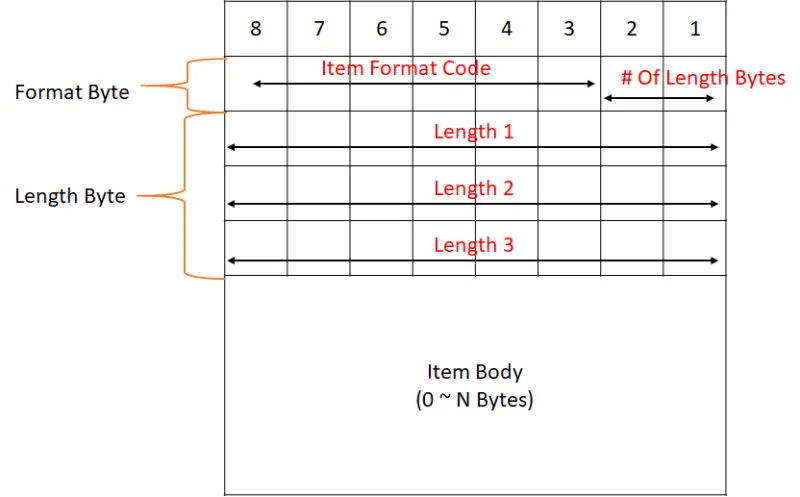
- #of Length Bytes : Length Bytes의 개수 (1 - 3)
- Item Format Code : Item의 종류
- Length Bytes :
- List : Sub Item의 개수
- Item : Item Body의 바이트 수
- 1 Byte = ~ 255 Bytes
- 2 Byte = ~ 65,536 Bytes
- 3 Byte = ~ 16,777,215 Bytes
-
3. Data Item Dictionary
SECS-II에서 사용되는 데이터 구조(Item)의 이름, 형식, 의미 등을 정의한 공식 문서 또는 표준 사전
SECS-II 메시지(SxFy)는 <L[2] <U1 3> <A "READY">>와 같은 데이터 구조만으로는 그 의미를 파악하기 어려움.
따라서 "S6F11의 첫 번째 필드는 CEID이고, 두 번째는 Report List이다"와 같이 각 필드의 의미를 표준화하여 문서화한 것이 Data Item Dictionary이다...
💡해당 부분은 실제 문서를 봐야지 도움이 될듯..
아래와 같이 정의되어있다고 한다.
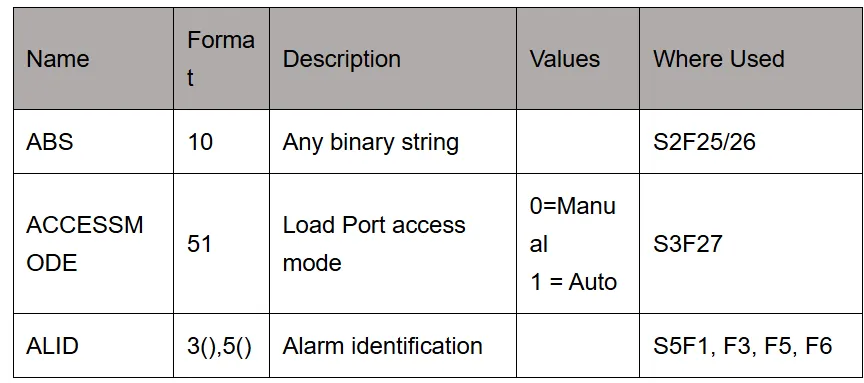
- 필드명 설명
Name: CEID, RPTID, VID 등 데이터 item의 이름Format: SECS-II 포맷 A, U1, I2, F4, L 등 데이터 형식Description: 항목의 의미 (예: Collection Event ID)Optional/Required: 해당 필드가 필수인지 여부Where Used: 이 항목이 포함되는 메시지(SxFy) 목록Constraints: 길이, 값의 범위 등 제약 조건
느낀점.
SECS - I 과 SECS - II 가 진짜 밀접하게 설계되어있다고 느꼈다.. HSMS 개발할때 호환성 맞추기 위해 고생 꽤나 했을듯
- 더 공부할점
-
SECS-II의 스트림(S)과 펑션(F) 조합에 대한 상세 학습
- 각 SxFy 메시지의 구체적인 용도와 의미
- 일반적으로 많이 사용되는 메시지 패턴
-
Data Item Dictionary 심화 학습
- CEID, RPTID, VID 등 주요 데이터 아이템의 상세 의미와 용례GEM공부를 하면 아마 1번은 실제적인 용례들과 함께 공부하게 될듯 싶다.
-
참고.
https://www.cimetrix.com/blog/secs-gem-series-protocol-layer
