실시간 빅데이터 처리를 위한 Spark & Flink Online 1) 데이터 엔지니어링과 Spark
1
실시간 빅데이터 처리를 위한 Spark & Flink Online
목록 보기
1/15
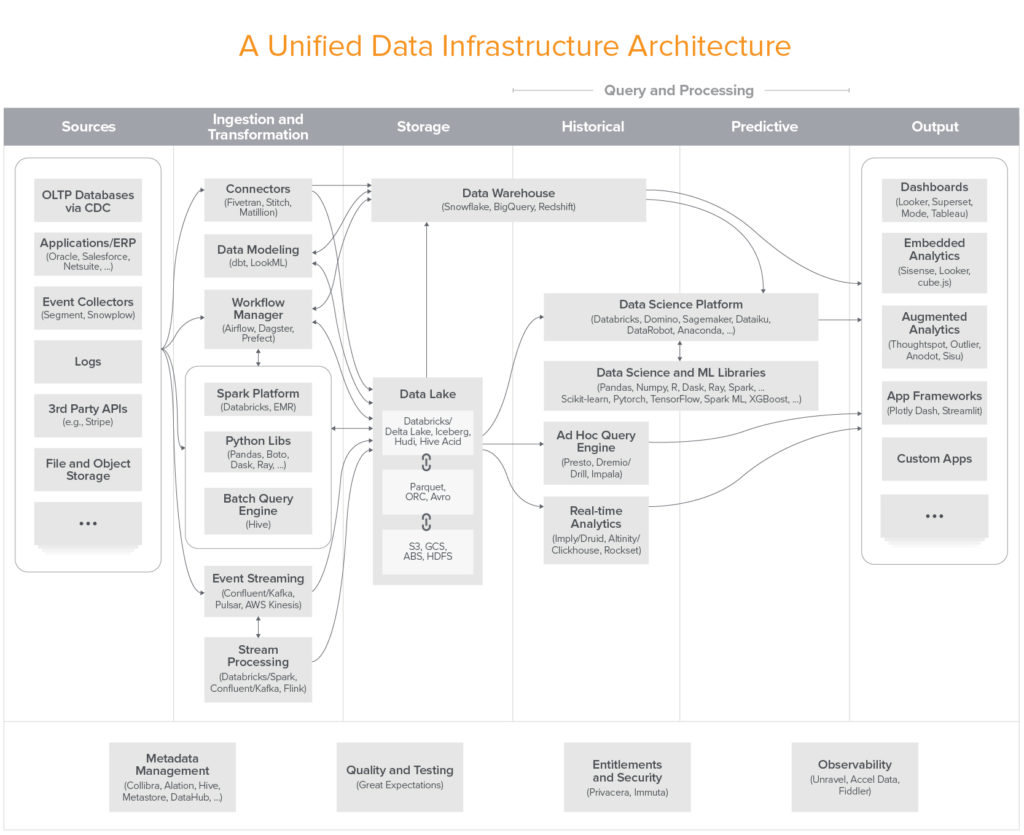
데이터 인프라 트랜드
- 클라우드 웨어하우스
-> 클라우드 환경으로 옮겨가는 중이며, Snowflake, Google Big Query 같은 솔루션을 사용 - Hadoop에서 Databricks, Presto 같은 다음 세대로 이동하는 추세
- 실시간 빅데이터 처리 (Stream Processing) 에 대한 수요도 늘고있음
- ETL -> ELT
- Dataflow 자동화 (Airflow)
-> 데이터파이프라인이 복잡해지고 의존성 관리가 어려워져서 자동화 - 데이터 분석 팀을 두기 보단 누구나 분석할 수 있도록
- 중앙화 되는 데이터 플랫폼 관리 (access control, data book)
데이터 아키텍처 분야
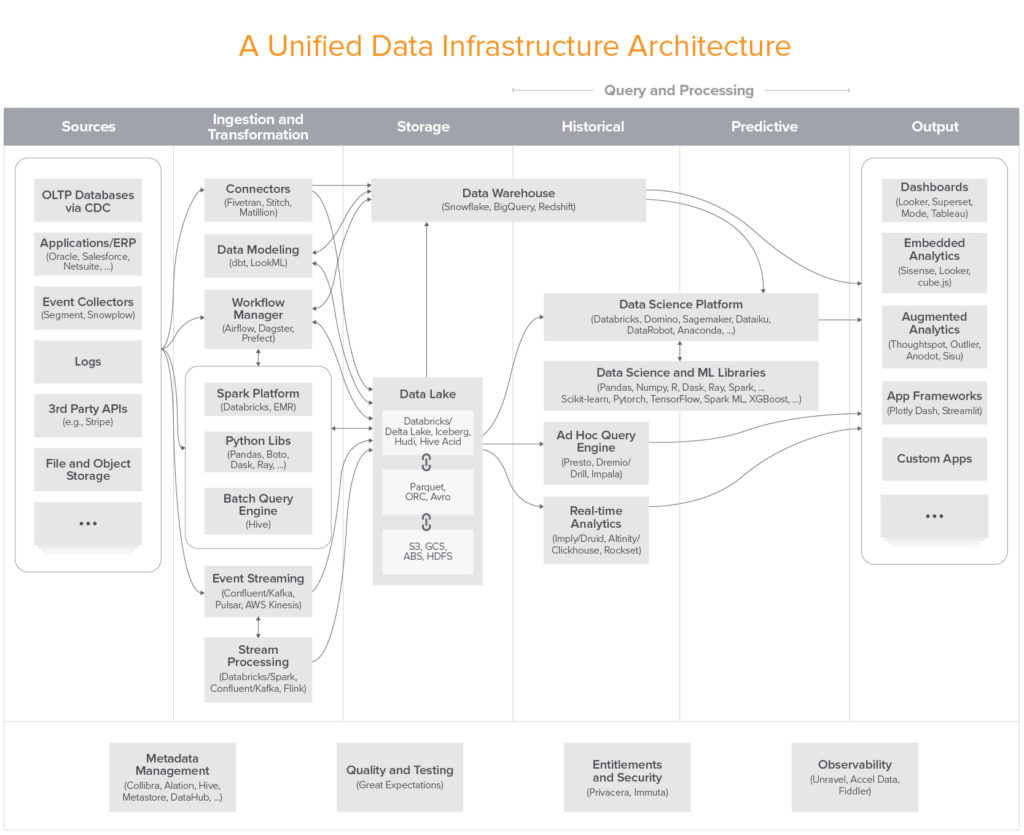
앞으로 배울 내용
- Spark와 데이터 병렬-분산 처리
- Airflow와 데이터 오케스트레이션
- Kafka와 이벤트 스트리밍
- Flink와 분산 스트림 프로세싱
Apache Hadoop
Apache hadoop은
- HDFS
파일시스템 - Map Reduce
연산 엔진 - Yarn
리소스관리
Apche Spark
Apache Spark는 하둡의 Map Reduce(연산 엔진)을 대체하는 프로젝트로 시작
장점: 빠르다 & 고속- In-Memory 연산
컴퓨터가 연산을 시작하면 메모리 계층 구조에 따라 하드디스크에서 CPU까지 데이터가 위로 이동
연산에 자주 쓰이는 데이터는 위로
연산에 자주 쓰이지 않는 데이터는 아래로
데이터를 쪼개서 여러 노드의 메모리를 이용해 동시에 처리하자
Spark Cluster의 구조
- Driver Program
작업 PC: Python, Java, Scala와 같은 Script로 일거리를 생산한다. - Cluster Manager
Hadoop-Yarn, AWS-Elastic MapReduce 일거리를 분배한다. - Worker Node
1CPU 코어 당 1Node 배치 인메모리 연산 담당
Spark 속도
- Hadoop MapReduce보다 빠르다
메모리상에선 100배
디스크상에선 10배 - Lazy Evaluation
태스크를 정의할때는 연산을 하지 않다가 결과가 필요할때 연산한다
기다리면서 연산 과정을 최적화 할 수 있다
RDD
- 여러 분산 노드에 걸쳐서 저장
- 변경이 불가능
- 여러개의 파티션으로 분리
버전별 특징
Spark 1.0
- 2014년 정식발표
- RDD를 이용한 인메모리 처리 방식
- DataFrame(V1.3)
- Project Tungsten - 엔진 업그레이드로 메모리와 CPU 효율 최적화
Spark 2.0
- 2016년 발표
- 단순화 되고 성능이 개선됨
- Structured Streaming
- DataSet이라는 DataFrame의 확장형 자료구조 등장
- Catalyst Optimizer 프로젝트 - 언어에 상관없이 동일한 성능을 보장
- Scala, Java, Python, R
Spark 3.0
- 2020년 발표
- MLlib 기능 추가
- Spark SQL 기능 추가
- Spark 2.4보다 약 2배 빨라짐
- Adaptive execution
- Dynamic partition pruning - PySpark 사용성 개선
- 딥러닝 지원 강화
- GPU 노드 지원
- 머신러닝 프레임워크와 연계가능 - GraphX-분산그래프연산
- Python 2 지원이 끊김
- 쿠버네티스 지원 강화
Spark 구성
- Spark Core
- Spark SQL
- Spark Streaming
- MLlib
- GraphX

2022년부턴 후회없이