
코딩 테스트에 자주 나오는 hash table에 대해서 알아보자!
코딩테스트 준비를 하면서 문제를 풀어보면서 나의 수준에 대해 다시한번 깨닫게 되었다...! 예전에는 나름 `알고리즘좀 짜죠~` 라고 했었는데 요즘 다시한번 문제들을 풀어보면서 큰 벽을 느꼈다 ... 가장 쉬운 문제유형중 하나로 뽑히는 hash에 대해 알아보자
Hash Table
hash table은 이라는 엄청난 시간 복잡도를 제공해줄 수 있는 자료구조중 하나이다.
list에 접근할때 index의 값으로 접근한다. 해당 방법으로 in, at 등등을 사용하면 이라는 시간 복잡도를 요구한다. list의 index는 int로 접근하는데, Hash table에서는 해당 index의 값을 어떠한 데이터 타입으로든 접근할 수 있다는게 포인트다.
기초 개념
hash table은 int가 아닌 다른 방법으로 index를 지정해 주기 위해서 특별한 열쇠를 만든다. 그 값을 key 값이라고 불러주자. 그리고 해당 key값에 딱 맞는 위치에 알맞은 value를 저장하여 해당 value를 얻을 수 있다.
위와 같은 key를 생성하여 우리는 for문을 통해서 모든 index를 지나야지 찾고싶은 value를 찾을 수 있던 것과 달리 그냥 한번에 key값으로 값을 얻을 수 있다.
밑 예제를 확인하면 조금 더 직관적인 코드로 이해할 수 있다.
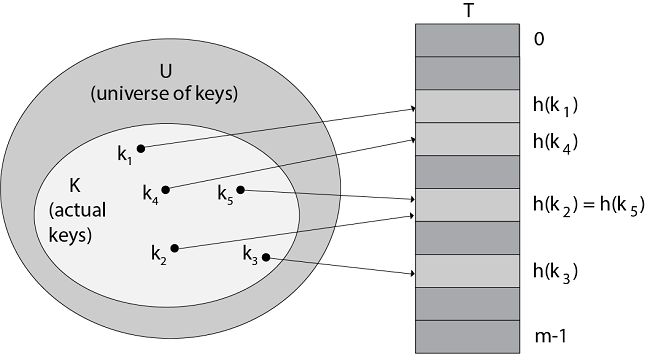
위의 그림은 hash table에 대해 보기 쉽게 나타낸 그림이다.
라는 actual keys집합 안에 여러가지 key들이 있고 해당 key 값에 해당하는 주소에 value가 저장되어 있다.
hash는 어떠한 값을 암호화하여 보안을 높이는 방법중 하나라고 볼 수도 있다. 어떤 입력이 주어지면 hash function이라는 암호화 함수를 이용하여 hash값을 형성하고, 해당 입력에 맞는 값을 가르키는 pointer처럼 사용하는 방법으로 이용하곤 한다.
이 부분은 학부에서 자료구조 시간에 배웠는데, 정확하게 기억나지는 않는듯 하다...
만약 위 그림에서 list의 경우에는 for문을 통하여 에 존재하는 모든 값들을 확인하여 한 value를 찾는다면 hash table에서는 hash함수에 k 라는 입력을 넣어줘 나온 값 (ex .. ) 을 이용하여 value를 바로 찾을 수 있다.
크기가 n 인 list의 경우에는 (모든 list를 다 찾아봄) 인데 반해, 와 같이 한번에 찾을 수 있어 의 탐색속도를 갖는다.
위와 같은 방식으로 get,update,set,delete,search모두 의 복잡도를 가진다.
c++의경우 Hashmap, Python의 경우 dictionary를 이용하여 구현할 수 있다.
예제
문제: 수많은 마라톤 선수들이 마라톤에 참여하였습니다. 단 한 명의 선수를 제외하고는 모든 선수가 마라톤을 완주하였습니다.
마라톤에 참여한 선수들의 이름이 담긴 배열 participant와 완주한 선수들의 이름이 담긴 배열 completion이 주어질 때, 완주하지 못한 선수의 이름을 return 하도록 solution 함수를 작성해주세요.
제한사항
- 마라톤 경기에 참여한 선수의 수는 1명 이상 100,000명 이하입니다.
- completion의 길이는 participant의 길이보다 1 작습니다.
- 참가자의 이름은 1개 이상 20개 이하의 알파벳 소문자로 이루어져 있습니다.
- 참가자 중에는 동명이인이 있을 수 있습니다.
import copy
def solution(participant, completion):
cp = copy.deepcopy(participant)
cc = copy.deepcopy(completion)
for part in participant:
if part in cc:
cp.pop(cp.index(part))
cc.pop(cc.index(part))
return cp[0]이 코드는 hash를 사용하지 않은 경우의 풀이이다. for문에서 pop의 영향을 받지 않기 위해 깊은 복사를 하여 같은 배열 생성 후 for문 내부의 in과 pop부분에 의해 의 시간 복잡도를 갖는 매우 비효율적인 코드라고 볼 수 있다. in과 pop에 해당하는 부분에서 모든 값들을 찾아야 하기에 리스트의 길이와 같은 크기만큼 찾아보는 상태이다.
def solution(participant, completion):
part_dict = {}
for part in participant:
part_dict[part] = part_dict.get(part, 0) + 1
for comp in completion:
part_dict[comp] -= 1
for name, count in part_dict.items():
if count == 1:
return name사실 이 코드 또한 와 잘짰네요 하는 느낌이 들지는 않지만.. hash를 연습하면서 작성한 코드이다. completion의 값들은 무조건 participant의 원소중 하나일 것이므로, 여러명이 있을 경우를 대비하여 key와 value를 {지원자 이름(string):완주자 수(int)} 로 구성하였다. 그 뒤로는 코드를 읽어보면 이해가 어렵지 않을것이다.
꿀팁?
String을 index처럼 사용해야 하는 문제들의 경우 대부분 hash로 접근한다.
하지만 hash는 sort가 불가능 하다는 것을 기억하자...!
주요 메서드들
dict.get(<key>,<default_value>) : 해당 key에 해당하는 value를 반환하고 key가 존재하지 않을 경우에는 default value를 반환한다.
dict.items(): for문을 활용할 때 key값과 value값을 모두 사용할 수 있다.
dict.pop(<key>,<default_value>): 해당 key에 해당하는 값을 삭제하고 해당 key가 없을 경우에는 default value를 반환한다.
알고계셨나요?
- python의 itertools 의 메서드인 combinations와 permutations를 이용하여 순열 조합의 문제를 쉽게 풀 수 있습니다.
from itertools import combinations, permutations