문제
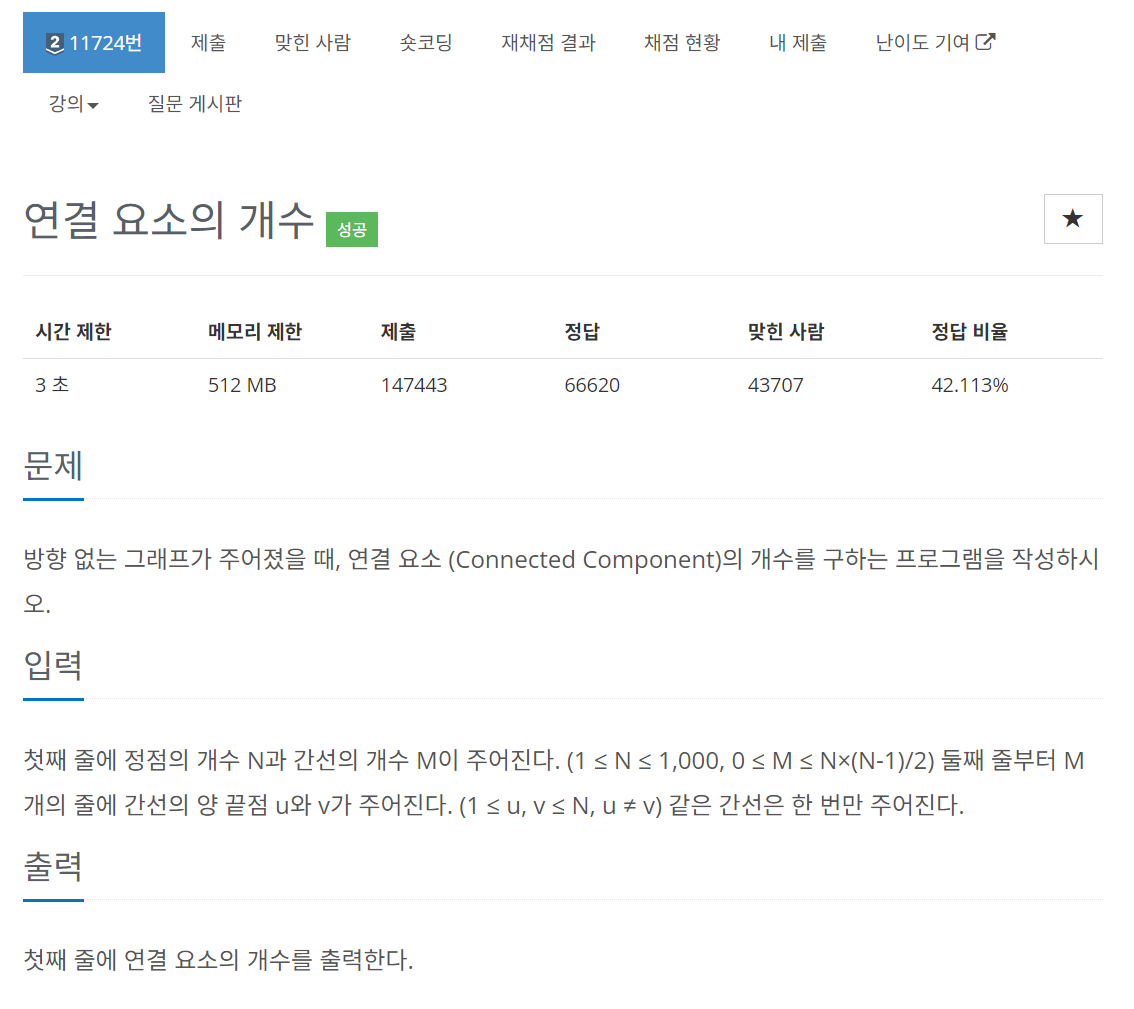
입력 예시 1
6 5
1 2
2 5
5 1
3 4
4 6출력 예시 1
2입력 예시 2
6 8
1 2
2 5
5 1
3 4
4 6
5 4
2 4
2 3출력 예시 2
1문제 이해
프로그래머스의 "네트워크", 백준의 "바이러스", 백준의 "유기농 배추" 와 비슷한 느낌이다. 사실 실버 등급 정도의 DFS면 거의 다 비슷하지 않을까 싶다. 사실 위에서 나열한 문제는 지금까지 푼 DFS 문제이기도 하다.
네트워크 개수를 구하는 것과 같다. 메인에서 호출을 한번하고 끝나면 그 값과 연결된 모든 요소가 방문처리 되기 때문에 메인에서 호출 할때 cnt해주면 된다. 난이도가 실버 2 이긴한데 DFS의 대표적인 문제라고 할 수 있다. 그래서 DFS에 대한 경험과 지식이 있으면 큰 어려움 없이 풀 수 있다. 개인적으로 난이도를 실버 4, 5 정도로 바꾸는 게 맞다고 생각한다.
여담
DFS/BFS가 잘 이해되지 않아서 DFS 강의를 구매했다. 그런데 생각보다 고급 DFS까지는 다루지 않는 것 같다. 그게 좀 아쉽긴 하다. 사실 완강하지 않아서 아직 잘 모르긴 한다. 뭐 그냥 심심풀이 삼아 생각을 적어봤다.
코드
# 백준 11724번 연결 요소의 개수 DFS
import sys
# 재귀 횟수 늘려주기
sys.setrecursionlimit(10**6)
# 입력을 효율적으로 받기 위해 추가
input = sys.stdin.readline
def DFS(node):
global graph, visited
visited[node] = True
for connect in range(1, N+1):
if graph[node][connect] and not visited[connect]:
DFS(connect)
# 0. 입력 및 초기화
N, M = map(int, input().split()) # 정점 N, 간선 M
graph = [[False] * (N + 1) for _ in range(N + 1)]
cnt = 0
visited = [False] * (N + 1)
# 1. 그래프 연결 요소
for _ in range(M):
u, v = map(int, input().split())
graph[u][v] = True
graph[v][u] = True
# 2. DFS호출
for node in range(1, N+1):
# 방문되지 않은 노드라면 DFS
if not visited[node]:
DFS(node) # 한번 호출되면 i번과 연결된 것들은 모두 방문됨.
cnt += 1
# 3. 출력
print(cnt)백준의 바이러스 문제와 다른 것은 메인에서 DFS를 호출할때 반복문을 쓰면서 조건문으로 방문되지않은 노드에 대해서만 DFS를 돌리는 것 뿐이다. 그런데 그거 하나 때문에도 좀 헷갈리긴 했다. 이것도 감을 익힐때까지 완전히 이해할 때까지 풀었던 문제도 또 풀어보고 해봐야겠다.
백준 유기농배추 문제와의 차이
백준 유기농배추 문제에서는 visited 리스트를 이용하려면 2차원 리스트로 만들어야하는데 이 문제에서는 visited를 1차원으로 만들어서 사용한다. 이해도가 높다면 이걸 헷갈리지 않겠지만 난 헷갈렸어서 추가한다.
유기농 배추는 애초에 map이 2차원 리스트이기 때문에 (2,1)과 (1,2)가 다른 값이기 때문에 방문처리도 각각 달라야 하기 때문에 2차원 리스트로 이용한다.
하지만 이번 문제는 노드의 갯수는 예시 1번을 기준으로하면 6개이다. 그런데 DFS를 잘 돌리기 위해서 2차원으로 graph를 만들었을 뿐이다. graph는 이차원으로 사용하더라도 visited는 1차원으로 써야하는 이유이다.
예시 1번을 기준으로 만든 표
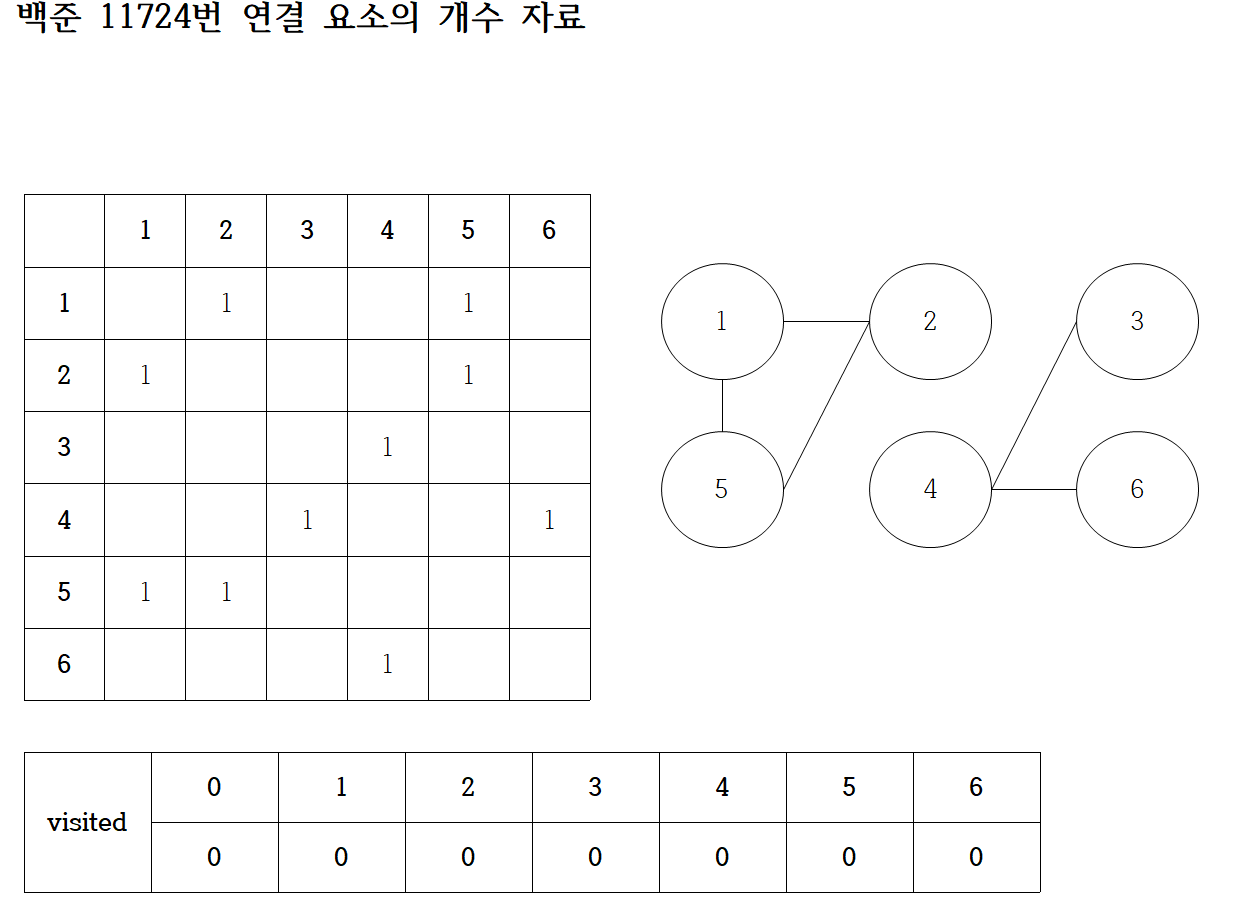
DFS 문제는 정확한 이해가 동반되어야만 로직을 정확하게 짤 수 있다. 그렇기 때문에 일부러 표로 만들어보는 작업도 필요하다.
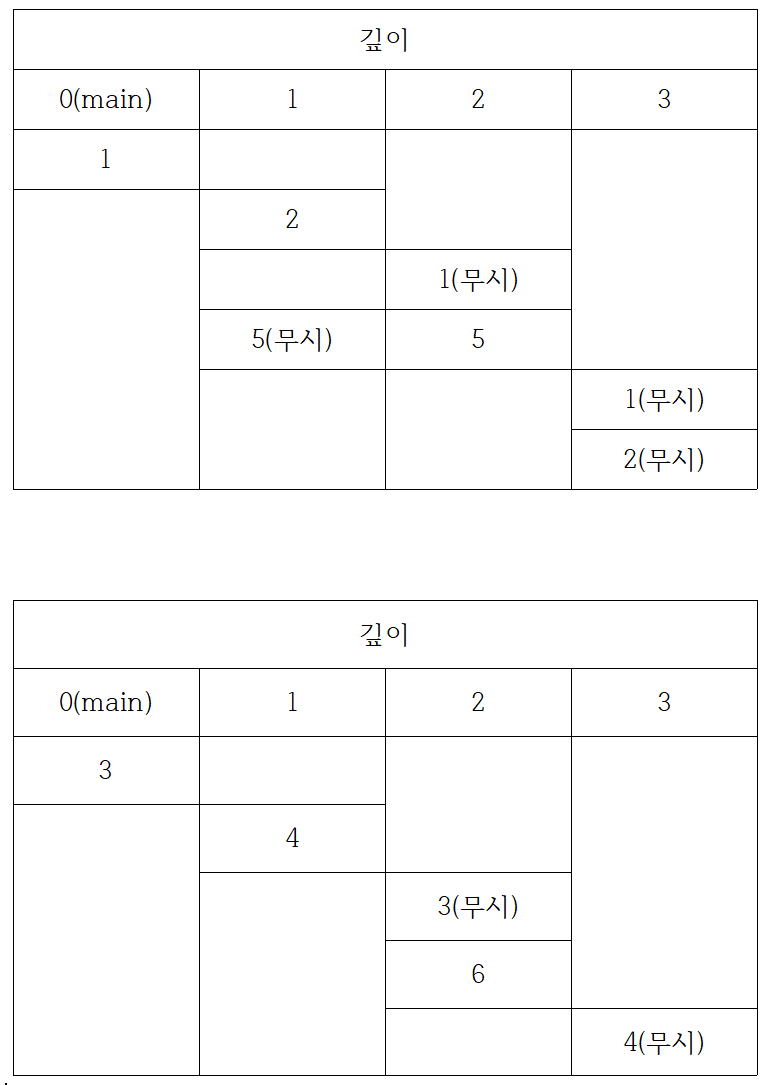
필요 스킬셋 or 지식
백준 사이트 재귀 횟수 제한
정보가 정확하지는 않다. 파이썬 자체인지, 백준 내부적으로 파이썬만 재귀 횟수에 제한을 두는 것인지. 뭐 아무튼 재귀 횟수를 늘려줘야 백준에서 런타임에러(RecursionError)를 피할 수 있다.
import sys
# 재귀 횟수 늘려주기
sys.setrecursionlimit(10**6)sys.stdin.readline
사실 지금까지 sys라는 모듈을 사용한 적이 없었다. 근데 오늘 문제를 제출하니 시간초과가 떴다. 뭐가 문제인지 찾다보니 sys.stdin.readline을 사용하니까 풀이가 통과됐다. 찾아보니 파이썬의 기본 input() 함수는 비교적 느린 입출력 방식이라고 한다. 대개 작은 입력 데이터를 처리할 때는 큰 문제가 없지만, 데이터의 양이 많거나 입력 속도가 중요한 문제에서는 시간 초과가 발생할 수 있다.
당장 이번 문제만 보더라도 이 한줄만 추가했는데 시간초과가 나던 풀이가 통과됐다. 그만큼 시간적으로 큰 효율성을 얻을 수 있는 것 같다.
import sys
# 입력을 효율적으로 받기 위해 추가
input = sys.stdin.readline이렇게 위에서 한번 선언하고 나면, 밑에서는 그냥 input()을 평소에 쓰던대로 사용하면 된다.
추가로 chatGPT의 설명을 추가한다.
질문:
파이썬으로 문제를 푸는데 input = sys.stdin.readline이걸 추가 안하면 시간초과가 나고, 넣으면 통과가 돼. 그 이유가 뭐야?
답변:
input = sys.stdin.readline을 사용해야 하는 이유는 주로 입력 속도와 관련이 있습니다. 파이썬의 기본input()함수는 비교적 느린 입출력 방식입니다. 대개 작은 입력 데이터를 처리할 때는 큰 문제가 없지만, 데이터의 양이 많거나 입력 속도가 중요한 문제에서는 시간 초과가 발생할 수 있습니다.
input()의 문제점:
input()함수는 한 줄씩 입력을 받을 때마다 내부적으로 여러 번 호출되고, 그 과정에서 추가적인 오버헤드가 발생합니다. 특히 많은 데이터를 처리할 때 그 차이가 커지게 됩니다.
sys.stdin.readline의 장점:
sys.stdin.readline은 버퍼링된 입력 방식으로,input()보다 훨씬 빠르게 입력을 받을 수 있습니다.sys.stdin.readline()은 한 줄을 읽는 데 필요한 시간을 줄여줍니다. 이 함수는 줄바꿈 문자\n도 포함하여 데이터를 읽기 때문에, 필요하다면.strip()같은 메서드를 사용해 줄바꿈 문자를 제거할 수 있습니다.예시:
import sys # 일반 input()을 사용하면 시간 초과가 날 수 있음 # n = int(input()) # sys.stdin.readline을 사용하면 더 빠르게 처리 가능 n = int(sys.stdin.readline().strip()) # 줄바꿈 문자 제거왜 시간 초과가 나는가?
- 입력량이 많을 때: 문제에서 입력되는 데이터 양이 많다면,
input()은 상대적으로 시간이 더 오래 걸립니다.sys.stdin.readline은 한 번에 더 많은 데이터를 처리할 수 있기 때문에 시간 초과를 방지할 수 있습니다.- 파이썬의 IO 속도 문제: 파이썬은 다른 언어들에 비해 기본적인 입출력 속도가 상대적으로 느린 편입니다. 이 점을 보완하려면
sys.stdin.readline()과 같이 좀 더 최적화된 방법을 사용하는 것이 중요합니다.결론:
입력 속도가 중요한 문제에서는
sys.stdin.readline을 사용하는 것이 훨씬 효율적이고 빠르기 때문에, 이를 사용하지 않으면 시간 초과가 발생할 수 있습니다.
