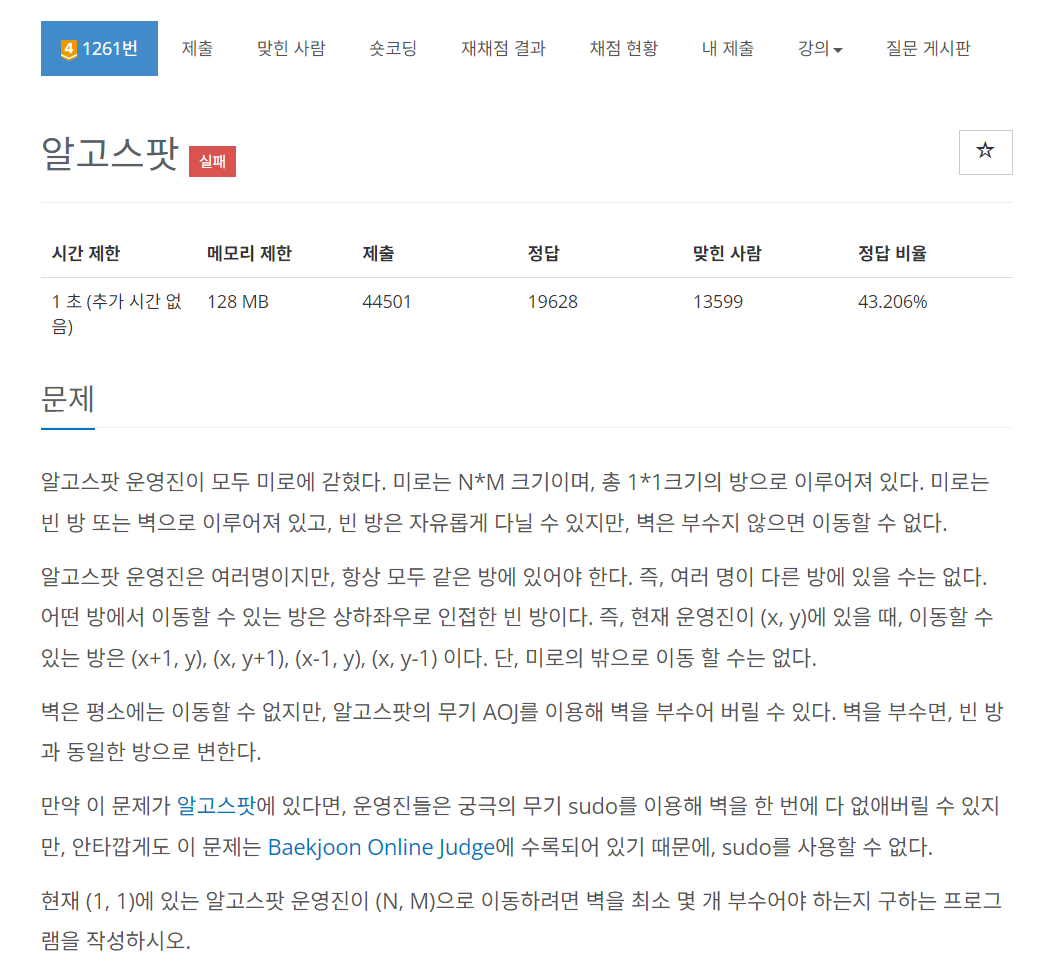
문제
입력
첫째 줄에 미로의 크기를 나타내는 가로 크기 M, 세로 크기 N (1 ≤ N, M ≤ 100)이 주어진다. 다음 N개의 줄에는 미로의 상태를 나타내는 숫자 0과 1이 주어진다. 0은 빈 방을 의미하고, 1은 벽을 의미한다.
(1, 1)과 (N, M)은 항상 뚫려있다.
출력
첫째 줄에 알고스팟 운영진이 (N, M)으로 이동하기 위해 벽을 최소 몇 개 부수어야 하는지 출력한다.
입력 예시 1
3 3
011
111
110출력 예시 1
3문제 이해
다익스트라 알고리즘을 공부하고 있다. 특히 시뮬레이션과 다익스트라가 합쳐진 이런 문제가 아직 너무 어렵다. 이번 문제는 다익스트라 보다는 BFS로 잘 풀 수 있을 것 같아서 BFS로 시도했는데 우여곡절이 많았다.
틀린 코드 1
# 백준 1261번 알고스팟
# 읽는 속도 효율화
import sys
input = sys.stdin.readline
# Import deque
from collections import deque
# 방향 벡터 동-서-남-북순
dx = [1, -1, 0, 0]
dy = [0, 0, 1, -1]
# BFS functions
def BFS(y, x, sum):
global visited, result
queue = deque()
queue.append((y, x, sum))
visited[y][x] = True
while queue:
y, x, sum = queue.popleft()
if y == N-1 and x == M-1: # 좌표값이 끝값이라면
result = min(result, sum)
for i in range(4):
nx = x + dx[i]
ny = y + dy[i]
if 0 <= nx < M and 0 <= ny < N and not visited[ny][nx]:
visited[ny][nx] = True # BFS는 큐에 넣을때 방문처리
if adj_matrix[ny][nx] == 0:
queue.append((ny, nx, sum))
if adj_matrix[ny][nx] == 1:
queue.append((ny, nx, sum+1))
# 0. 입력 및 초기화
M, N = map(int, input().split()) # M가로 N세로
visited = [ [False] * M for _ in range(N)]
INF = int(1e12)
result = INF # 여기에 각 값을 넣고 가장 작은 값을 출력한다.
# 1. Create adj_matrix
adj_matrix = []
for _ in range(N):
# 공백으로 구분되어 들어올땐 input().split()
# 공백없이 입력될 땐 input().rstrip()
adj_matrix.append(list(map(int, input().rstrip())))
# 2. Excute BFS function
BFS(0, 0, 0) # y, x, sum
# 3. Print result
print(result)나는 BFS를 사용하면 각각의 줄기로 뻗어나간다고 생각했는데 이 문제를 풀면서 개념이 흔들리기 시작했다. 왜 안되는지 이해가 안돼서 질문글을 남겼더니 댓글이 여러개 달렸다. 왜 안되는지는 이해가 됐는데 왜 틀린 코드 2처럼 해야하는지 정확히 이해가 되지는 않는다. 아마 visited 때문인 것 같은데...
틀린 코드 2
# 백준 1261번 알고스팟
# 읽는 속도 효율화
import sys
input = sys.stdin.readline
# Import deque
from collections import deque
# 방향 벡터 동-서-남-북순
dx = [1, -1, 0, 0]
dy = [0, 0, 1, -1]
# BFS functions
def BFS(y, x, sum):
global visited, result
queue = deque()
queue.append((y, x, sum))
while queue:
y, x, sum = queue.popleft()
visited[y][x] = True # 우선적으로 처리해줘야하는 상황에서는 값을 뺄때 방문처리 해야하는듯듯
if y == N-1 and x == M-1: # 좌표값이 끝값이라면
result = min(result, sum)
for i in range(4):
nx = x + dx[i]
ny = y + dy[i]
if 0 <= nx < M and 0 <= ny < N and not visited[ny][nx]:
if adj_matrix[ny][nx] == 0:
queue.appendleft((ny, nx, sum))
if adj_matrix[ny][nx] == 1:
queue.append((ny, nx, sum+1))
# 0. 입력 및 초기화
M, N = map(int, input().split()) # M가로 N세로
visited = [ [False] * M for _ in range(N)]
INF = int(1e12)
result = INF # 여기에 각 값을 넣고 가장 작은 값을 출력한다.
# 1. Create adj_matrix
adj_matrix = []
for _ in range(N):
# 공백으로 구분되어 들어올땐 input().split()
# 공백없이 입력될 땐 input().rstrip()
adj_matrix.append(list(map(int, input().rstrip())))
# 2. Excute BFS function
BFS(0, 0, 0) # y, x, sum
# 3. Print result
print(result)이 코드는 예제 입력은 다 예제 출력처럼 잘 출력되는데 시간초과가 났다. 결국 다익스트라 처럼 풀어야 하는 것 같다.
정답 코드 (BFS인데 다익스트라 개념을 섞은)
# 백준 1261번 알고스팟
# 읽는 속도 효율화
import sys
input = sys.stdin.readline
# Import deque
from collections import deque
# 방향 벡터 동-서-남-북순
dx = [1, -1, 0, 0]
dy = [0, 0, 1, -1]
# BFS functions
def BFS(y, x):
global visited, count
queue = deque()
queue.append((y, x))
count[y][x] = 0 # 시작 지점점
while queue:
y, x = queue.popleft()
for i in range(4):
nx = x + dx[i]
ny = y + dy[i]
if 0 <= nx < M and 0 <= ny < N:
if count[ny][nx] == -1: # 방문이 처음이면
if adj_matrix[ny][nx] == 0:
queue.appendleft((ny, nx)) # 우선적으로 큐에 넣기 때문에 appendleft
count[ny][nx] = count[y][x] # 지금까지 벽을 깬 값을 넘겨준다다
if adj_matrix[ny][nx] == 1: # 벽이 있다면
queue.append((ny, nx))
count[ny][nx] = count[y][x] + 1 # 지금까지 벽을 깬 값에 +1
# 0. 입력 및 초기화
M, N = map(int, input().split()) # M가로 N세로
count = [ [-1] * M for _ in range(N)]
# 1. Create adj_matrix
adj_matrix = []
for _ in range(N):
# 공백으로 구분되어 들어올땐 input().split()
# 공백없이 입력될 땐 input().rstrip()
adj_matrix.append(list(map(int, input().rstrip())))
# 2. Excute BFS function
BFS(0, 0) # y, x
# 3. Print result
print(count[N-1][M-1])다익스트라 알고리즘을 다시 공부해야겠다. 사실 왜 방문이 처음일때만 큐에 넣는지 아직 잘 모르겠고, 우선적으로 appendleft를 써서 넣어주는데 아마 PriorityQueue에는 뭘 기준으로 우선적으로 큐에 넣는 로직이 있나보다. 그 부분을 공부하면 이 코드도 완벽하게 이해할 수 있을 것 같다. 문제 푸는 것은 중단하고 그 부분부터 공부해야겠다.
2024.12.23 추가
PriorityQueue는 큐안에 들어있는 첫번째 인덱스의 값을 기준으로 가장 작은 값을 우선적으로 큐에서 꺼낸다. 이 동작을 deque에서 하려면 우선적으로 큐에서 빼서 처리하기 위해서 appendleft로 값을 넣어서 우선 처리를 하게 해주는 방식이다. 아직 왜 방문 안했을 때만 처리하는지는 모르겠다. 사실상 이 문제는 그냥 다익스트라로 푸는게 훨씬 간단하다. 보통 BFS라면 인접행렬의 값이 1일때만, 또는 0일때만 큐에 넣는데 이 문제는 둘다 처리는 하는데 0이 우선적으로 탐색이 되어야해서 복잡해지는 것 같다. 위의 코드 자체가 다익스트라를 BFS로 deque로 표현하는 방식이라 그냥 다익스트라를 쓰는게 편한 것 같다.
정답 코드 (다익스트라)
# 백준 1261번 알고스팟
# 읽는 속도 효율화
import sys
input = sys.stdin.readline
# Import deque
from queue import PriorityQueue
# 방향 벡터 동-서-남-북순
dx = [1, -1, 0, 0]
dy = [0, 0, 1, -1]
# BFS functions
def Dijkstra(cur_count ,y, x):
count = [[INF] * M for _ in range(N)] # 각 좌표까지 최소 몇개의 벽 부수기가 필요한지 저장할 리스트
pq = PriorityQueue()
pq.put([cur_count, y, x])
count[y][x] = 0 # 시작 값은 0
while not pq.empty():
cur_count, y, x = pq.get() # 원래라면 cur_distance, cur_node인데 인접 행렬이라서 y, x값이다
# 이미 갱신한 값인데 그 값보다 크면 갱신할 필요가 없음.
#아래로 내려가도 갱신은 안되겠지만 불필요하게 반복문 실행을 줄이기 위해해
if cur_count > count[y][x]:
continue
# 인접 리스트면 바로 밑의 if문까지가 for adj_node, adj_distance in adj_list[cur_node]로 표현이 된다.
# 인접 행렬이면 이렇게 사용해야함.
for i in range(4):
nx = x + dx[i]
ny = y + dy[i]
if 0 <= nx < M and 0 <= ny < N: # 유효 범위 내라면
# 현재 최솟값보다 작으면
if cur_count + adj_matrix[ny][nx] < count[ny][nx]: # 원래라면 cur_distance + adj_distance 인데 인접 행렬이고, 가중치가 리스트 값이라서
temp_count = cur_count + adj_matrix[ny][nx]
count[ny][nx] = temp_count
pq.put([temp_count, ny, nx])
return count
# 0. 입력 및 초기화
INF = int(1e12)
M, N = map(int, input().split()) # M가로 N세로
# 1. Create adj_matrix
adj_matrix = []
for _ in range(N):
# 공백으로 구분되어 들어올땐 input().split()
# 공백없이 입력될 땐 input().rstrip()
adj_matrix.append(list(map(int, input().rstrip())))
# 2. Excute BFS function
count_list = Dijkstra(0, 0, 0) # 현재거리, 시작 좌표값(0, 0)
# 3. Print result
print(count_list[N-1][M-1])확실히 다익스트라 개념을 완전히 이해하지 못해서 이 문제에서 고생한 것 같다. 지금 듣고 있는 인프런 강의는 개념 설명이 좀 많이 부족한 것 같다. 나동빈 유튜브의 다익스트라 알고리즘 강의를 봤더니 쉽게 이해할 수 있었다. 그저 goat다.
참고 사이트:
https://ji-gwang.tistory.com/302
이 사람의 최근글을 보고 감탄했다.