문제
입력
첫 번째 줄에 수빈이가 있는 위치 N과 동생이 있는 위치 K가 주어진다. N과 K는 정수이다.
출력
첫째 줄에 수빈이가 동생을 찾는 가장 빠른 시간을 출력한다.
둘째 줄에 어떻게 이동해야 하는지 공백으로 구분해 출력한다.
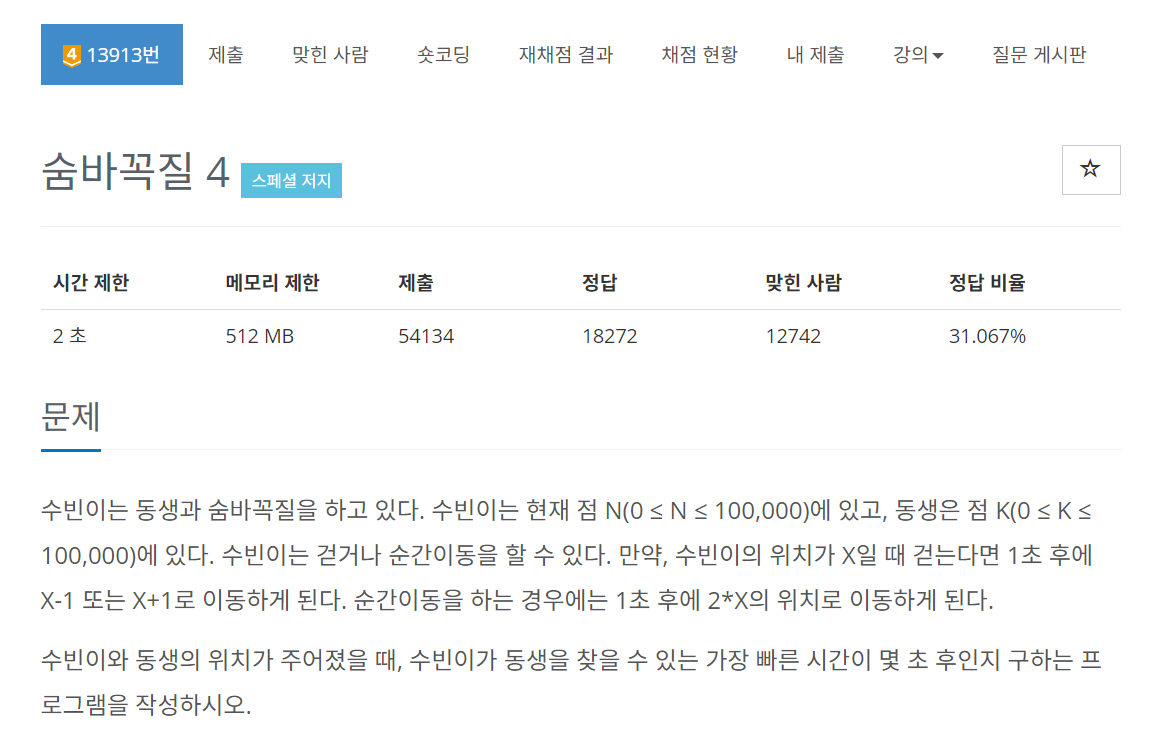
입력 예시 1
5 17출력 예시 1
4
5 10 9 18 17문제 이해
같은 숨바꼭질 시리즈인데 이번에는 가장 빠른 경로를 BFS로 구하고, 그 경로를 출력해야한다.
경로는 각 BFS의 줄기마다 달라야 하니까 매개변수로 리스트를 넣어주고, 매번 값을 큐에 넣을때 그 값을 리스트에 넣어준다. 풀이 자체는 어렵지 않은데 구현하려니 좀 생각할게 많은 문제이다.
오답 코드
# 백준 13913번 숨바꼭질 4
# 읽는 속도 효율화
import sys
input = sys.stdin.readline
from collections import deque
#function BFS
def BFS(x, times, result_list):
global visited
queue = deque()
queue.append((x, times, result_list))
visited[x] = 1
while queue:
x, times, result_list = queue.popleft()
if x == K:
print(times)
print(" ".join(map(str, result_list)))
return
for nx in [x*2, x-1, x+1]:
if 0 <= nx <= MAX and not visited[nx]:
visited[nx] = 1
queue.append((nx, times+1, result_list.append(nx)))
# 0. 입력 및 초기화
MAX = 100000
N, K = map(int, input().split())
visited = [0] * (MAX+1)
# 1. BFS호출
BFS(N, 0, [N])
VScode에서 이 코드를 실행하면 AttributeError가 난다.
문제가 되는 부분
for nx in [x*2, x-1, x+1]:
if 0 <= nx <= MAX and not visited[nx]:
visited[nx] = 1
queue.append((nx, times+1, result_list.append(nx)))위 코드에서 큐에 값을 넣을때, result_list.append(nx)를 하는데. 우리가 여기서 원하는 동작은 nx값을 result_list에 넣어주고 그 리스트를 큐에 넣고 싶은 건데 이런 방식으로 코드를 짜면 생각대로 작동하지 않는다. append를 하게 되면 값 처리를 하고 나서 반환값으로 None을 리턴한다. 그래서 큐에는 None값이 들어가게 되어서 정상 작동을 하지 못한다.
주의할 코드
for nx in [x*2, x-1, x+1]:
if 0 <= nx <= MAX and not visited[nx]:
visited[nx] = 1
result_list.append(nx)
queue.append((nx, times+1, result_list))
이렇게 코드를 짜도 정상작동하지 않는다. 그 이유는 아마 BFS가 여러갈래로 뻗어나가는데 그 각각의 result_list에 nx값을 넣어주기 때문에 문제가 생기는 것 같다. 그래서 그냥 큐에 넣을때 result_list + [nx] 방식으로 넘겨주면 문제없이 작동한다.
2차 오답 코드
# 백준 13913번 숨바꼭질 4
# 읽는 속도 효율화
import sys
input = sys.stdin.readline
from collections import deque
#function BFS
def BFS(x, times, result_list):
global visited
queue = deque()
queue.append((x, times, result_list))
visited[x] = 1
while queue:
x, times, result_list = queue.popleft()
if x == K:
print(times)
print(" ".join(map(str, result_list)))
return
for nx in [x*2, x-1, x+1]:
if 0 <= nx <= MAX and not visited[nx]:
visited[nx] = 1
# append시키면 다른 갈래의 BFS의 result_list에도 append가 된다.
# 그래서 원래 리스트에 값을 붙여주는 방식으로 매개변수를 넣는다.
queue.append((nx, times+1, result_list + [nx]))
# 0. 입력 및 초기화
MAX = 100000
N, K = map(int, input().split())
visited = [0] * (MAX+1)
# 1. BFS호출
BFS(N, 0, [N]) #수빈 위치, 횟수, 경로이 코드를 제출했는데 시간초과가 났다. 그래서 서칭을 해보니 딕셔너리를 써야한다는 말도 있는데 제일 신빙성이 있는건 N이 K보다 클때를 따로 처리해주면 된다는 것이다.
정답 코드
# 백준 13913번 숨바꼭질 4
# 읽는 속도 효율화
import sys
input = sys.stdin.readline
from collections import deque
#function BFS
def BFS(x, times, result_list):
global visited
queue = deque()
queue.append((x, times, result_list))
visited[x] = 1
# N이 K보다 작을때 (N부터 K까지 1씩 빼면서 경로 출력)
# 이걸 따로 처리 안해주면 계속 BFS를 돌리면서 경로를 찾아서 시간초과가 난다.
if N > K:
print(N-K) # 시간
for i in range(N, K-1, -1):
print(i, end=" ") # 경로
return
while queue:
x, times, result_list = queue.popleft()
if x == K:
print(times)
print(" ".join(map(str, result_list)))
return
for nx in [x*2, x-1, x+1]:
if 0 <= nx <= MAX and not visited[nx]:
visited[nx] = 1
# append시키면 다른 갈래의 BFS의 result_list에도 append가 된다.
# 그래서 원래 리스트에 값을 붙여주는 방식으로 매개변수를 넣는다.
queue.append((nx, times+1, result_list + [nx]))
# 0. 입력 및 초기화
MAX = 100000
N, K = map(int, input().split())
visited = [0] * (MAX+1)
# 1. BFS호출
BFS(N, 0, [N]) #수빈 위치, 횟수, 경로N이 K보다 크다면 어차피 N값에서 K값이 될때까지 -1계속 빼준 값을 출력하면 굳이 BFS를 실행하지 않고도 빠르게 값을 찾을 수 있다. 이 로직하나만 추가해줘도 보란듯이 정답판정을 받는다.
흔적
여담

여담으로 드디어 실버2에 도달했다. 티어 올리는 재미도 있는 것 같다. 학교 복학 전까지 알고리즘 이것저것 배우면서 골드까지 찍어야겠다.
