문제

예제 입력 1
5 5 1
1 4
1 2
2 3
2 4
3 4예제 출력 1
1
2
3
4
0문제 이해
전형적인 DFS 문제이긴 한데 거기에 새로운 개념이 들어왔다. 처음에 DFS 문제는 보통 2차원 배열을 이용해서 연결요소를 파악하고 탐색을 한다.
이 문제에서는 정점의 개수가 N (5 ≤ N ≤ 100,000)이기 때문에 2차원 배열로 만들면 최대 백억개가 된다. 그래서 메모리 초과가 난다. 그래서 이렇게 정점의 제한이 큰 경우에는 빈리스트를 만들고, 거기에 맞는 값을 추가해주는 방식으로 진행해야한다.
(백준의 바이러스 문제의 경우 N의 갯수는 최대 100이다. 즉, 최대 10,000개의 2차원 배열값을 할당하기에 별 문제가 없다.)
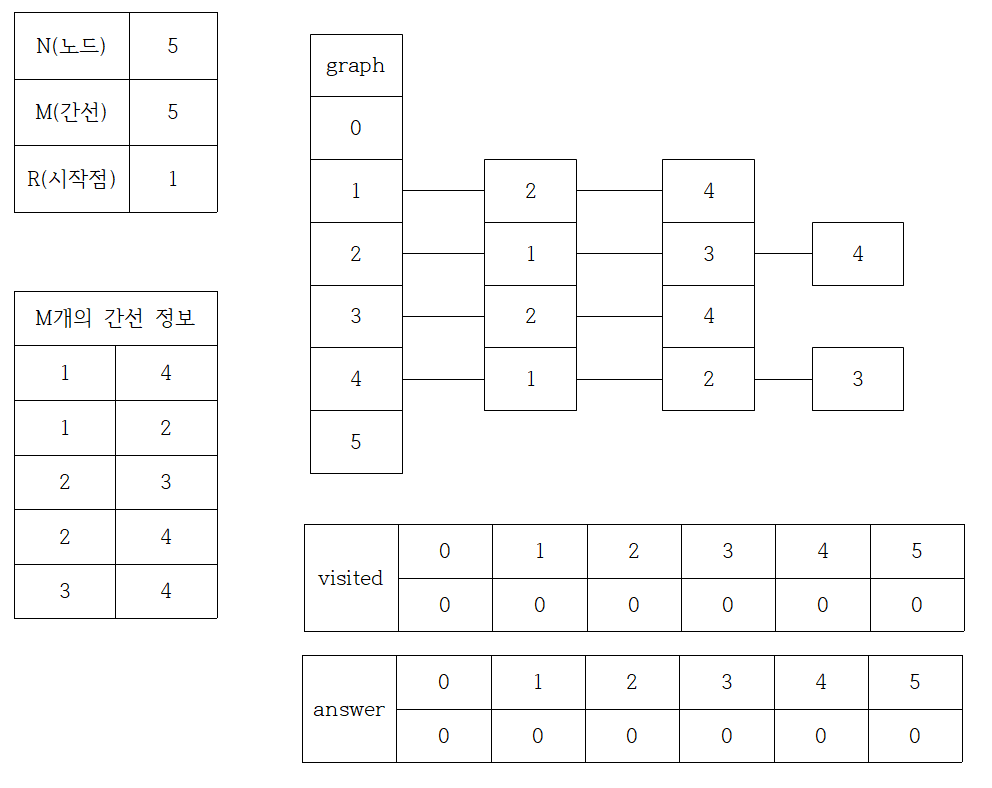
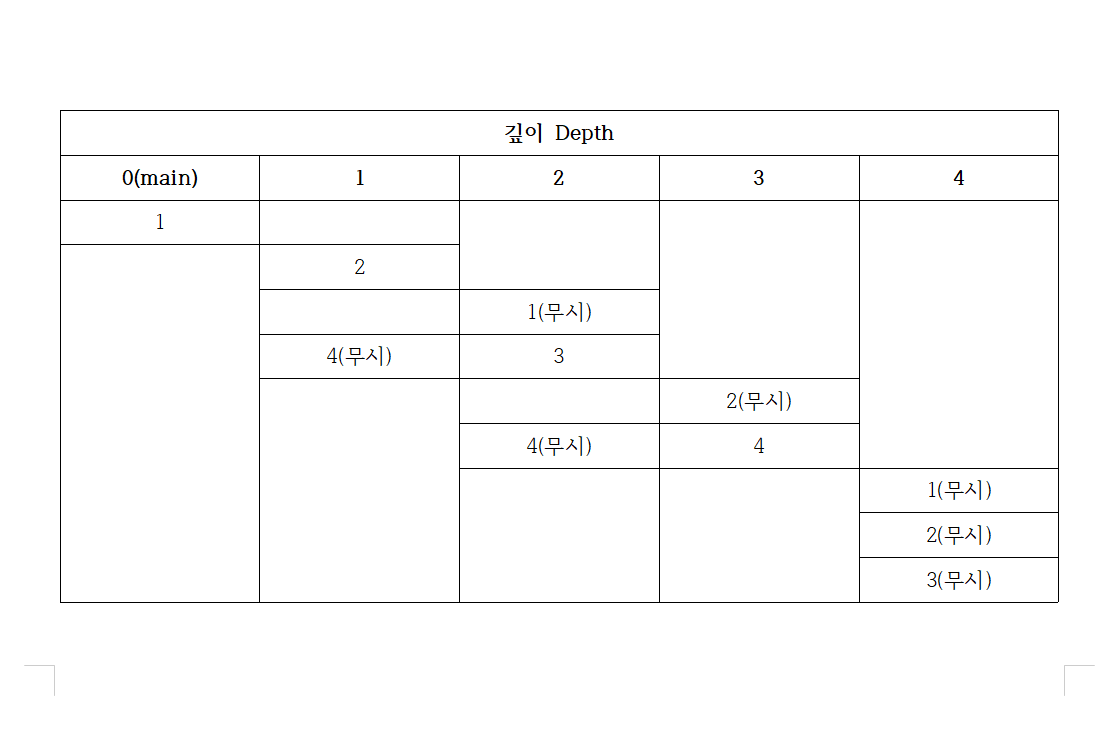
예제 1을 기준으로 만든 표와 자료
코드
# 백준 24479번 알고리즘 수업 - 깊이 우선 탐색 1
def DFS(idx):
global visited, graph, answer, order
visited[idx] = True
answer[idx] = order
order += 1
for i in graph[idx]:
if not visited[i]:
DFS(i)
# 재귀 횟수 and 읽기 속도 늘리기
import sys
sys.setrecursionlimit(10**6)
input = sys.stdin.readline
# 0. 입력 및 초기화
# N 정점, M 간선, R 시작지점
N, M, R = map(int, input().split())
graph = [ [] for _ in range(N+1)]
visited = [False] * (N+1)
answer = [0] * (N+1) # 탐색 안한 것은 0이여야 함
order = 1
# 1. 연결 요소 입력
for _ in range(M):
x, y = map(int, input().split())
graph[x].append(y)
graph[y].append(x)
# 2. 오름차순 정렬
for i in range(1, N+1):
graph[i].sort()
# 배열을 쓴다면 알아서 오름차순으로 탐색 가능 하지만 노드 갯수 제한이 크면 배열을 못씀
# graph가 더 효율적임. 딱 쓰는 메모리만 사용하는 방식. 대신 오름차순으로 정렬해줘야 한다
# 3. DFS호출
DFS(R) #idx R과 연결된 모든 요소만 탐색하는 거라서 반복문은 없음
# 4. 출력
for i in range(1, N+1):
print(answer[i])필요 스킬셋
graph를 빈 리스트로 만든 후 연결 값 넣기
graph = [ [] for _ in range(N+1)]
for _ in range(M):
x, y = map(int, input().split())
graph[x].append(y)
graph[y].append(x)만약 (1, 2)가 들어온다면 1번째 리스트에 2값을 넣어주고, 2번째 리스트에 1값을 넣어주는 방식이다.
def DFS(idx):
global visited, graph, answer, order
visited[idx] = True
answer[idx] = order
order += 1
for i in graph[idx]:
if not visited[i]:
DFS(i)DFS 함수가 호출된 인덱스의 리스트 값을 돌면서 방문하지 않았으면 DFS를 호출한다.
(answer는 방문 순서를 기억하기 위한 리스트이다.)

Make progress