문제
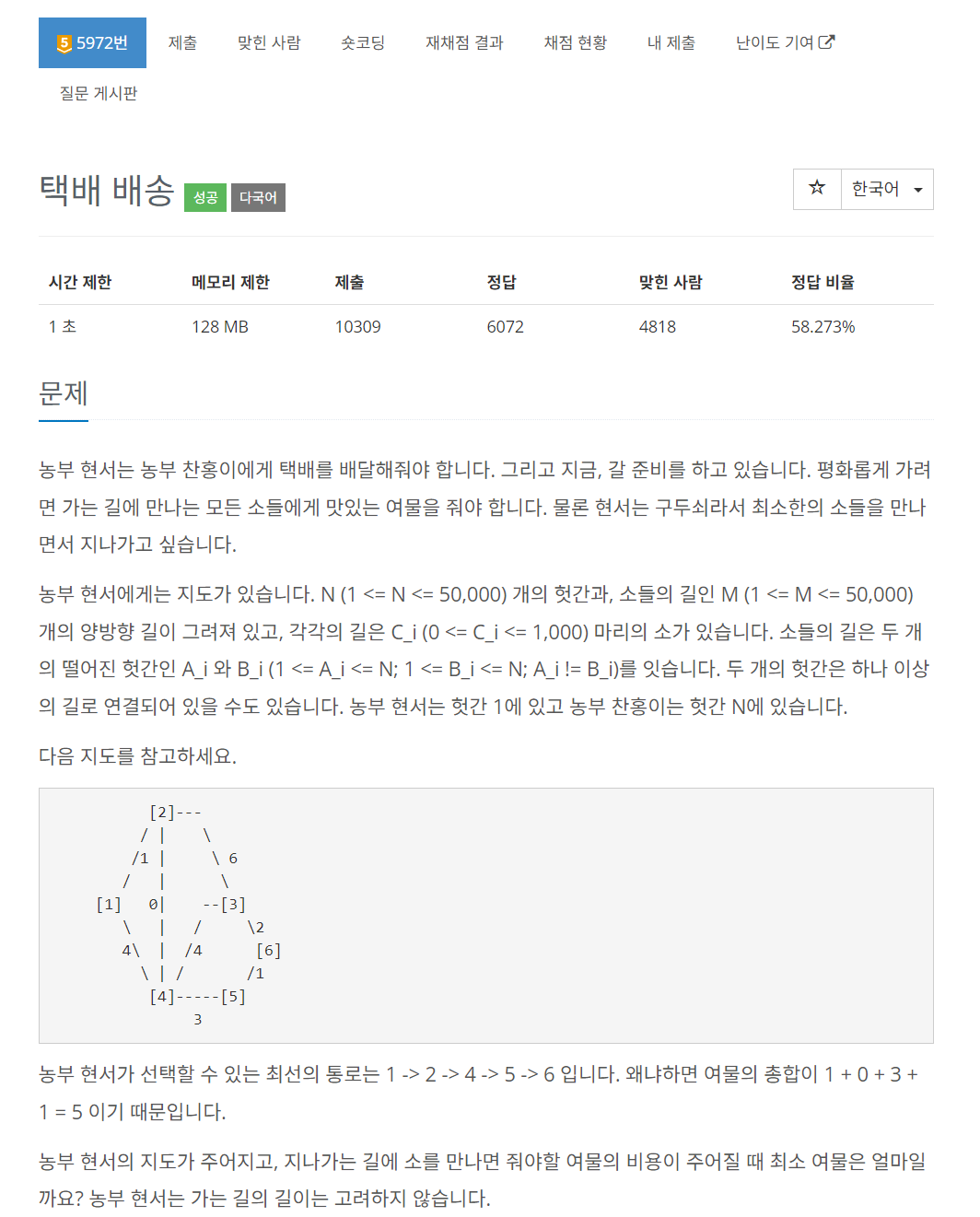
문제 이해
다익스트라 기본 구현문제이다. 정말 기본적인 구현만 하면 정답 처리를 받을 것 같다. 단 같은 경로에 두개 이상의 길이 있을 수도 있기 때문에 조건문을 하나 넣어서 불필요하게 반복문을 돌지 않도록 방지해야한다.
while not pq.empty():
cur_cost, cur_node = pq.get()
# 이 조건문
if cur_cost > cost[cur_node]:
continue
for adj_node, adj_cost in adj_list[cur_node]:
temp_cost = cur_cost + adj_cost경로가 하나씩만 있으면 굳이 필요는 없는 것 같다. 하지만 같은 경로에 길이 2개 이상이면 여러번 노드 사이를 확인해야하고 그러면 이미 들어간 값보다 큰 값도 불필요하게 반복문을 돌 수 있다. 즉, 이미 갱신된 값보다 작아야 갱신을 해주는데, 이미 갱신된 값보다 큰 값도 저 조건문이 없다면 어차피 갱신되지 않아도 반복문을 돌게 된다. 그래서 이런 불필요한 걸 줄이기 위해서 같은 경로에 2개 이상의 길이 있으면 이 조건문이 필요하다.
어떤 문제는 이 조건문이 없어서 시간초과가 나기도 했다.
코드
# 백준 5972번 택배 배송
# 읽는 속도 효율화
import sys
input = sys.stdin.readline
# Import PriorityQueue
from queue import PriorityQueue
# Function Dijkstra
def Dijkstra(cur_cost, start_node):
cost = [INF] * (N+1)
pq = PriorityQueue()
pq.put([cur_cost, start_node])
cost[start_node] = 0
while not pq.empty():
cur_cost, cur_node = pq.get()
if cur_cost > cost[cur_node]:
continue
for adj_node, adj_cost in adj_list[cur_node]:
temp_cost = cur_cost + adj_cost
if temp_cost < cost[adj_node]:
cost[adj_node] = temp_cost
pq.put([temp_cost, adj_node])
return cost
# 0. 입력 및 초기화
INF = int(1e12)
N, M = map(int, input().split()) # N 노드 갯수, M 간선 갯수
# 1. Create adj_list
adj_list = [ [] for _ in range(N+1)]
for _ in range(M):
a, b, t = map(int, input().split())
adj_list[a].append([b, t])
adj_list[b].append([a, t])
# 2. Excute Dijkstra Algorithm
cost_list = Dijkstra(0, 1) # cur_cost, start_node
# 3. Print result
print(cost_list[N])
Make progress