2주 전에 간단하게 크롤링 한답시고 bs4 인터프리터를 추가한 후 간단하게 지니뮤직, 영화사이트를 웹스크래핑을 한 경험이 있다.
웹스크래핑이란?
웹 스크래핑(web scraping)은 웹 페이지에서 우리가 원하는 부분의 데이터를 수집해오는 것을 뜻한다.
한국에서는 같은 작업을 크롤링 crawling 이라는 용어로 혼용해서 쓰는 경우가 많다.
원래는 크롤링은 자동화하여 주기적으로 웹 상에서 페이지들을 돌아다니며 분류/색인하고 업데이트된 부분을 찾는 등의 일을 하는 것을 뜻한다.
지니뮤직, 영화사이트를 웹 스크래핑할 때에는 버튼누르는 건 상상도 못했다.
상상이 현실이 되야할 때가 와버렸다.
나는 먼저 천천히 하나한 해보자는 식으로 위에서부터 쭉 웹스크래핑을 해왔다.
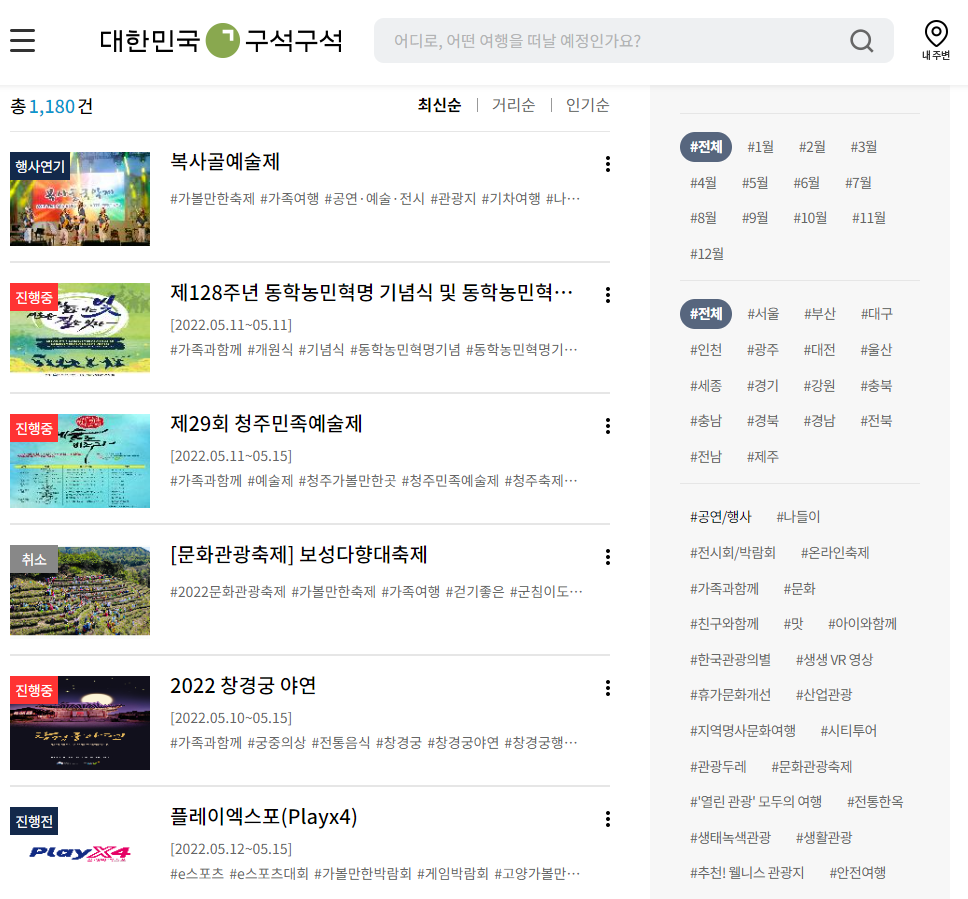
복사골예술제, 제128주년 동학농민혁명... 등 전과 같은 방식을 사용했다.
우클릭 -> 검사 -> copy -> copy selector
나는 분명 같은 방식으로 웹 스크래핑을 하였고 코드에도 문제가 없어보였다. 근데 출력값은???
None.
식은땀이 흐르고 나는 생각했다. 땀 닦으면서
동적 웹페이지라 None이 나오는구나. 동적인 웹페이지를 웹스크래핑 할 때에는 어떻게 해야할까?
그리고 나온 답은? 셀레니움
셀레니움 형님을 쓰는 법은 비슷했다. 내가 아는 선에선.
셀레니움이란?
프로그래밍으로 브라우저 동작을 제어해서 마치 사람이 이용하는 것 같이 웹페이지를 요청하고 응답을 받아올 수 있는 것이다.
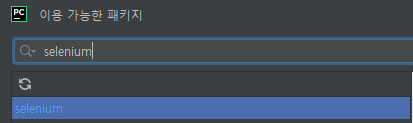
먼저 selenium을 패키지를 추가했다.

이 작고 귀여운 친구도 크롬 버전에 맞게 설치 후 넣어준다!!
driver = webdriver.Chrome('./chromedriver') # 드라이버를 실행합니다.
url = "주소"
driver.get(url) # 드라이버에 해당 url의 웹페이지를 띄웁니다.
sleep(1) # 페이지가 로딩되는 동안 1초 간 기다립니다.
req = driver.page_source # html 정보를 가져옵니다.
driver.quit() # 정보를 가져왔으므로 드라이버는 꺼줍니다.기본적인 구조는 이렇다.
저 빈 공간 사이에 나는 제목과 날짜는 물론

밑에 이 친구들까지 눌러줘야했다.
제목과 날짜를 가져왔으니 이제 버튼을 눌러서 다음장에 있는 축제들의 정보도 긁어와야했다.
우클릭 -> 검사 -> copy -> copy selector
그런데 값이 이상했다. #\32 이게 뭐지.. 양현진을 보는 것 같군..
고민을 해보다가 아 이대론 안되겠다
우클릭 -> 검사 -> copy -> copy xpath
로 값을 복사했더니 그럴싸한 값이 나왔다. //*[@id="2"] 음.. 이건 윤강희 같군..
버튼을 누를 수 있는 find_element_by_xpath() 이 함수를 사용하여 실행!
driver.find_element_by_xpath('//*[@id="2"] ').click()하지만 값이 이상하게 나온다.
c++을 자주써본 나로선 vs가 익숙해 디버깅도 쉽게 하지 못하는 상황이었다.
하지만 난 이 문제를 꼭 해결하고 자고 싶었다. 디버깅을 천천히 돌려보는데 어라?????
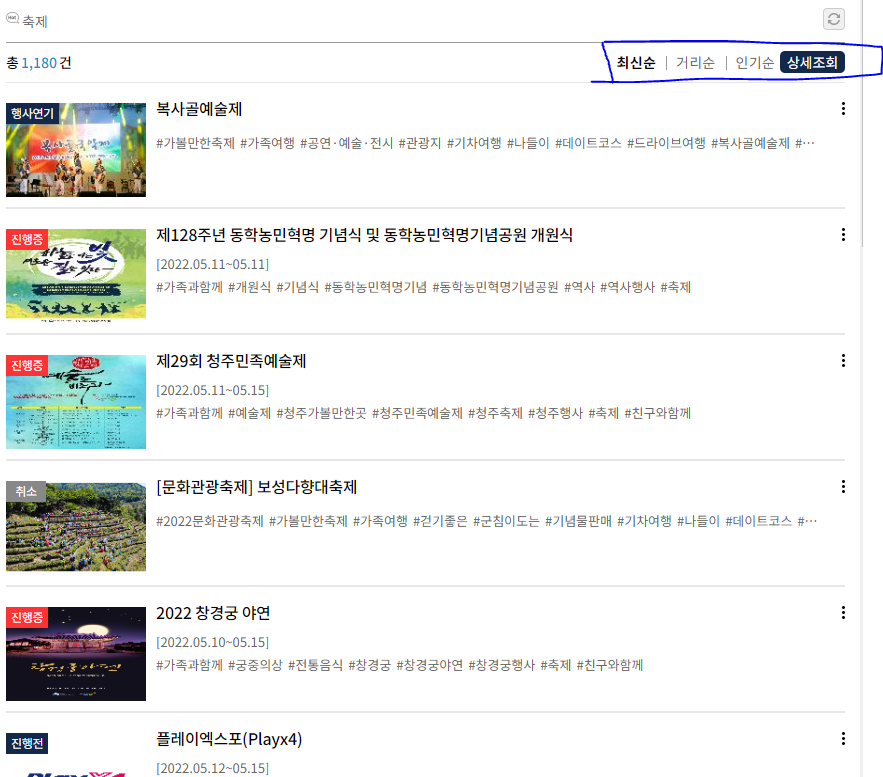
저 최신순, 거리순, 인기순이 눌리네?
우클릭 -> 검사 -> copy -> copy xpath
해본결과 다음 페이지로 넘어가는 버튼들과 값이 똑같았고(//*[@id="2"]) 나는 한단계 위에 감싸고 있는 녀석까지 긁어왔다.
driver.find_element_by_xpath('//*[@id="contents"]/div[2]/div[1]/div[2]//*[@id="' + str(i) +'"]').send_keys(Keys.ENTER)그 후 성공을 하였고 나는 꿀잠을 잤다.
끝!!
