컴파일-1
- 프로세서(CPU)는 특정 비트패턴을 인식하여 명령을 수행한다.
- 예를 들어, 1001'1011'0000'0100 라는 명령어가 두 레지스터의 값을 더하라는 뜻으로 프로세서가 해석한다.
- 근데, 저러한 비트패턴을 사람이 일일이 쓰기 힘들어서 Assembly어가 탄생했다.
- 위와 같은 패턴을 add r1, r2, r3 와 같이 1대1 매칭되는 Assembly어를 만들어 편의성 향상
- 근데 이것은 프로세서에 의존적이다.
- 예를 들어, ARM 프로세서의 Assembly어와 Intel 의 Assembly어는 서로 다르다.
- 이러한 불편을 해결하기 위해 C나 C++ 과 같은 HighLevel Language가 등장했다.
- Compatibility (호환성) 향상 = 이식성이 좋다 -> 호환성이란 말이 모호하지만 있는 그대로 여러 프로세서에서 사용될 수 있는 언어라는 뜻이다. 이식성이란 말도 모호하지만 하나의 언어가 여러 프로세서의 바이너리로 이식이 가능하다라는 뜻 (워낙 오래된 언어이다보니 C Compiler 를 제공하는 프로세서가 많다).
- 이제 High Level Language 부터 비트 패턴까지를 역순으로 생각해보자면...
=> High Level Language (C, C++, ...) -> Assembly어 -> 바이너리
=> 이것이 컴파일 과정이다. - mnemonic (=연상 기호) : assembly어를 의미한다. (비트 패턴과 1대1 매칭이 가능하므로)
컴파일-2
-
조금 더 자세히 생각해보자.
-
컴파일이라는 것은 결국 바이너리 이미지를 만드는 과정.
- 여기서 바이너리란 비트 패턴(Native Code)들의 집합.
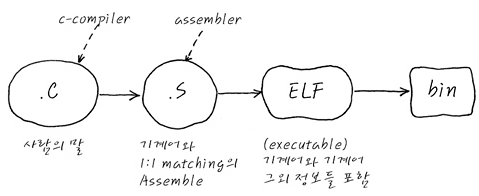
- C 나 C++ 로 만들어진 소스파일들이 결국 하나의 Binary 파일이 되는 과정.
-
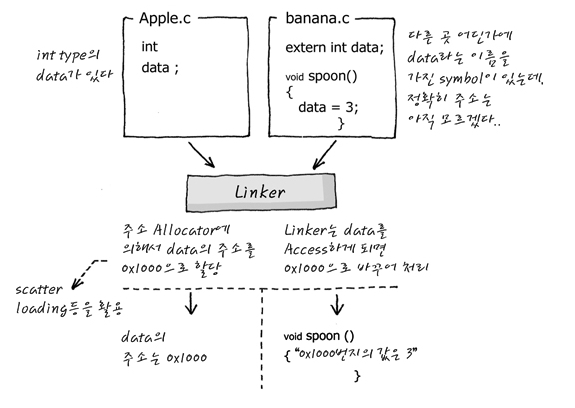
그런데, 소스파일 하나야 위 그림처럼 간단하게 바이너리 파일로 만들어지겠지만, 프로젝트에서 굉장히 많은 소스파일들이 함께 컴파일 된다고 가정해보면 매우 복잡할 것이다.
- 예를 들어 a.c 파일에 global 변수로 Count 라는 변수가 정의되어있고, k.c 파일에서 Count를 가져다 쓴다고 하면 extern 과 같은 키워드를 통해 Count 라는 변수가 다른 파일에 정의되어 있다고 알려줘야 한다. 그럼 이때 컴파일러는 이거를 어떻게 처리하냐?
-
이를 위해 Linker 라는 녀석이 필요하다.
-
여러개의 소스파일을 각각 object 파일로 만든 후, Linker를 통해 여러개의 object를 링크한다.
- 위에 Count 변수의 예시를 생각해보면 k.c를 컴파일 할 때, 컴파일러는 Count라는 변수가 어딘가에 있어~ 라고 생각하고 해당 변수의 주소를 비워두고 object 파일을 만든다. 그럼 링커가 비어있는 놈을 다른 파일에서 찾아 해당 주소로 연결시켜준다.
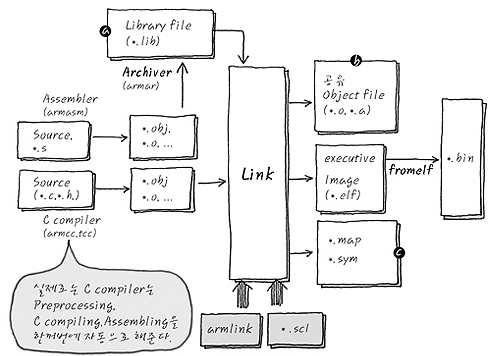
- 위 그림이 종합적인 컴파일의 과정이라고 생각하면 된다. (물론 Assembly어로 만들기 전에 전처리과정이 있다.)
a. 라이브러리 파일이란, 소스코드를 직접 제공하지 않고, 개발자가 object 파일로 미리 컴파일하여 만들어놓은것
b. scatter loading 이라는 것이 있는데, 이는 binary 를 만들 때 원하는 주소에 매핑하고 싶을 때 사용.
c. map 파일은 binary의 메모리 주소를 정리해놓은 파일.
- 결국 여러 소스파일을 (전처리 -> 어셈블리 -> 기계어) 의 과정을 거쳐 각각의 obj 파일을 만들고,
이를 링커가
- Symbol 처리(ex. k.c 파일의 Count변수는 어디에서 정의된 변수인지.),
- 메모리 재배치(ex. scatter loading을 통해 개발자가 직접 메모리에 어느 부분에 넣을 지 정의한 것을 참조하여 재배치),
실행파일 생성) 등의 일을 하여 - 하나의 실행파일을 만들어낸다.
라이브러리 파일
- 간단하게 생각해보자면 여러 소스파일들을 하나의 obj파일로 만들어서 제공하는 것.
- 라이브러리 파일을 사용하는 두가지 이유
- 소스코드를 공개하지 않기 위해
- 컴파일이 이미 되어 있어 컴파일 시간이 단축된다.
- 위 사진에서와 같이 결국 라이브러리 파일도 하나의 obj 파일이 되어 다른 obj 파일들과 묶여서 하나의 실행파일이 된다.
변수의 Scope와 생애
-
auto 변수
- auto 변수 = 지역변수
- block 내에서 태어나고 죽는다.
- automatically 하게 태어나고 죽는다고 생각하면 된다.
-
extern 변수
- global 변수
- extern 이라는 뜻은 "외부의" 라는 뜻을 갖는다.
- 즉 global 변수는 extern 의 성격을 갖는다.
- 자기 자신이 정의되어 있는 파일 외의 다른 파일에서도 해당 변수를 사용할 수 있다. (물론 다른 파일에서는 이 변수를 extern 키워드를 사용하여 다른 파일에 정의되어 있다는 것을 컴파일러에게 알려야 한다.)
-
static 변수
- 함수 내 static : 함수가 종료가 되어도 메모리에 해당 변수가 살아있다.
- global static : 다른 파일에서 해당 변수를 가져다 쓸 수 없다. -> 따라서 a.c 에 static int a 가 선언되어 있고, b.c 에 int a; 가 있다면 충돌이 발생하지 않는다.
=> 이 둘의 공통점은 사용범위는 파일 또는 함수 내로 국한시키면서, 동시에 메모리에 값이 계속 유지가 되는 특징을 갖는다.
-
volatile 변수
- 컴파일러에게 최적화 하지 말라고 얘기해주는 변수다.
Memory map 과 Symbol
- 링커를 좀더 잘 다루기위해 위에 내용을 정리해보자.
- Symbol 이라는 것은 Linker가 elf 형식을 따르는 여러 obj 파일들을 하나로 묶는데 필요한 것.
- Symbol 은 결국 자기 스스로 주소를 가질 수 있냐 없냐에 따라 달라짐.
- global 변수 : 다른 파일에서도 이 변수를 가져다 쓸 수 있다.
- static 변수 : static 변수는 특정 파일 또는 특정 함수 안으로 범위가 제한되지만, 얘는 자기만의 주소를 갖는다.
- 함수 : 당연히 다른 파일에서도 함수를 가져다 쓸 수 있으니 주소를 갖는다.
- Local 변수는 당연히 어떠한 함수 내에서 stack 에 만들어졌다가 없어지니깐 Symbol이 될 수 없다. (local 변수도 주소야 갖겠지만, 이는 절대적인 주소라고 할 수 없는게 임시로 stack 영역에 만들어졌다가 사라지니깐.)
- 변수들을 메모리 관점에서 분류해보자
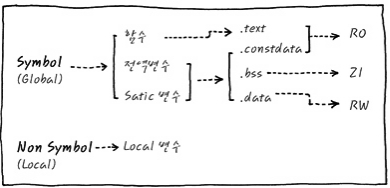
- RO(Read Only) 영역 : code + const global 변수
- RW(Read-Write) 영역 : 초기화된 global 변수
- ZI(Zero-Initialize) 영역 : 초기화되지 않은 global 변수
ELF(Executable and Linkable Format)
-
ELF 파일이라는 것은 이름 그대로 실행가능한 or 링크 가능한게 만들어주는 파일의 format을 의미한다.
- 결국 obj 파일들이 모여 Link를 하고, Link 하여 만들어진 하나의 obj 파일이 하나의 binary 이미지로 나오기 때문에 obj 파일도 결국 ELF 형식을 따르는 것이다.
- 소스파일 -> obj 파일 : elf형식을 따르는 Link 가능한 obj 파일 (=relocatable 파일이라고 부름)
- 여러 obj 파일 -> 하나의 obj 파일 : elf 형식을 따르는 실행가능한 obj 파일
- 결국 obj 파일들이 모여 Link를 하고, Link 하여 만들어진 하나의 obj 파일이 하나의 binary 이미지로 나오기 때문에 obj 파일도 결국 ELF 형식을 따르는 것이다.
-
ELF 공식문서에 나오는 사진
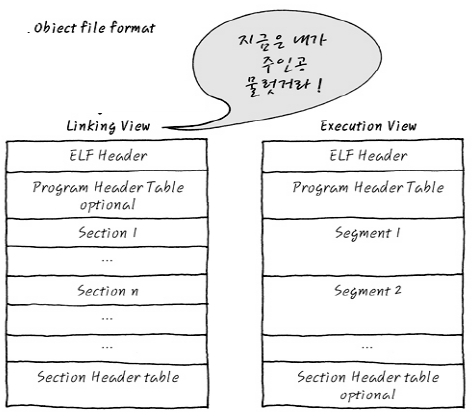
- 위에서 얘기한 내용이와 동일.
- Linking View 는 소스파일 -> obj 파일
- Execution View 는 여러 obj 파일 -> 하나의 obj 파일
- 위에서 얘기한 내용이와 동일.
-
ELF 파일 분석
-
ELF Header
-
typedef struct {
unsigned char e_ident[EI_NIDENT];
Elf32_Half e_type;
Elf32_Half e_machine;
Elf32_Word e_version;
Elf32_Addr e_entry;
Elf32_Off e_phoff;
Elf32_Off e_shoff;
Elf32_Word e_flags;
Elf32_Half e_ehsize;
Elf32_Half e_phentsize;
Elf32_Half e_phnum;
Elf32_Half e_shentsize;
Elf32_Half e_shnum;
Elf32_Half e_shstrndx;
} Elf32_Ehdr; -
CPU 정보, elf type(linking view 인지 execution view 인지) 등의 정보가 들어있다.
-
OPCode
- 실제 기계어가 들어있다.
-
Symbol Table
- 나중에 하나의 obj 파일로 Link 하기 위해 필요한 symbol 들의 정보가 들어있다.
-
결국 ELF(Linking View)에는 여러 obj 파일을 묶을 수 있는 정보와 파일에 대한 메타데이터, 기계어 코드가 들어있다.
Linker 마무리.
결국 Linker는 실제 함수 정의부의 위치와 전역변수들의 위치를 library 파일과 obj 파일을 차례대로 조사한 후에 모두 Table 에 간직하고 있다가 그 주소를 함수 호출 코드 부분에 기록해 넣는 일을 한다!!!
-
Linker 는 결국 여러 obj 파일들을 하나의 executable 한 파일로 만드는 역할을 한다.
- 위의 코드에서 알 수 있듯이 각각의 obj 파일들은 어딘가에 선언되어 있을 외부 변수 또는 함수를 비워둔 채로 있는다. 이것을 각각의 obj 파일을 뒤져서 실제 주소로 매핑해주고 하는 게 링커가 하는 일이다.
-
ELF Relocatable File
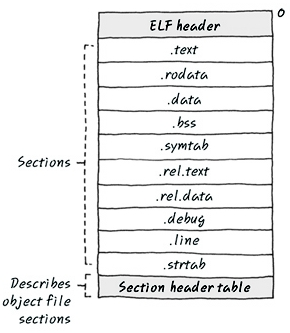
- .text : 기계어가 들어있다.
- .rodata : const data
- .data : 초기화된 전역변수
- .bss : 초기화 되지 않은 전역변수 (0)
- .symtab : 한 파일 내의 symbol 들을 저장한다.
- .rel.text : opcode 가 들어있는데, 구멍난 애들도 같이 들어가있다. executable elf 에서는 볼 수 없고, Linker 가 링킹 시에 꼭 필요한 놈이다.
- .rel.data : link 시에 참조되는 전역변수. extern 전역변수나 exter 함수이름들
-
ELF Executable File
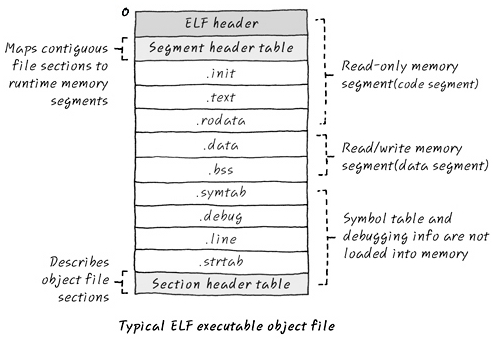
- 링크가 끝난 후이기 때문에 rel.text , rel.data 는 없다.
- .init section 은 ELF 가 실행될 때 실행되전에 initialize 를 하는 code 가 들어있다.
- 결국 여기서 제일 중요한 것은 code section 과 data section.
- debug, symtab 과 같은 정보들을 빼고 그냥 순수 RO data 와 RW 데이터 두개의 Section을 가지고 있는게 바이너리다 라고 보면 된다.
- 여기서 ZI 데이터는? 얘네는 어차피 0으로 초기화 되어 있는 놈들이기 때문에 그냥 ZI 데이터의 사이즈만큼만 메모리에서 0으로 밀어버리면 된다. 그래서 따로 바이너리가 가지고 있진 않은듯.
- bss 가 ZI 인데, bss는 Block Started by Symbol 의 약자. 왜 이런 단어가 ZI영역과 같은 의미로 쓰이냐면.. 얘네는 ROM 에 바이너리를 저장할 때 영역으로 잡혀있지 않다. (RW, RO 만 잡힘) 왜냐면 얘네는 symbol로 시작과 끝을 알려주기 때문에. 그렇게 해도 어차피 시작~끝을 0으로만 밀어주면 되는거니깐. 그래서 바이너리에 하나의 영역으로 잡히지 않고, symbol 로 잡힘.
Scatter Loading
-
SSD 를 생각해보자. SSD가 동작하도록 하는 펌웨어 실행파일 (바이너리) 는 SSD 안에 NAND Flash 메모리에 들어가있다.
-
Nand Flash 메모리는 XIP 가 불가능하다. XIP 라는 것은 결국 Word, Byte 등의 단위로 Random Access 가 가능해야하는데, NAND Flash 는 그것이 안된다.
-
그럼 앞에서 얘기한 것처럼 RAM에 바이너리 (RO, RW) 를 올리고, symbol 을 참조하여 ZI(.bss) 영역을 만들어준다. 그리고 실행한다.
-
바로 이 과정 (ROM -> RAM으로 옮겨주는 과정) 을 가능하게 해주는 것이 바로 Scatter File이다.
-
위에 컴파일 과정 그림에 보면 Linker에 scl 파일이 함께 들어가는 것을 볼 수 있다. 이것이 Scatter Loading File 이다.
-
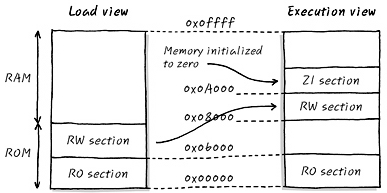
-
위 사진에서 Load View 는 Software 가 실행되기 전 저장매체에 담겨 있을때의 모습
- Flash 에 실행 이미지가 담겨 있을 때의 형태.
-
Execution View 는 Software 가 실제로 실행될 때의 모습
-
이렇게 load view 와 execution view 가 다른 이유는?
- 위에 ssd 예시에서 설명한것과 동일.
- nand와 같은 메모리에서는 random access 가 불가능하다.
- ZI(.bss) 영역이 메모리에 저장되어 있을 때에는 잡혀있지 않다. 그러나 실행할때는 잡혀있어야 한다.
-
예시를 들어보자.
- MCP 구조를 NOR+PSRAM 으로 잡아보자.
- NOR 에 저장을 하고 실행은 PSRAM 이면 RO 데이터는 그냥 NOR에 있어도 되지만, RW는 PSRAM 으로 옮겨야한다. 그래야 Read Write 가 가능하니까. ZI는 PSRAM 에 잡아주고.
- 코드
LOAD_ROM 0x0 : Load Region : Loading 되어 있는 image의 모습 { EXEC_ROM 0x0 : Execution Region : Excution할때의 image의 모습 { spaghetti.o (+RO) : 실행될때 spaghetti.o의 RO는 여기에, input section } EXEC_RAM 0x8000 : Execution Region { spaghetti.o (+RW) : 실행될때 spaghetti.o의 RW는 여기에, input sectoin } EXEC_RAM2 0xA000 : Execution Region { spaghetti.o (+ZI) : 실행될 때 spaghetti.o의 ZI는 여기에~, input section } }
-
해석해보자
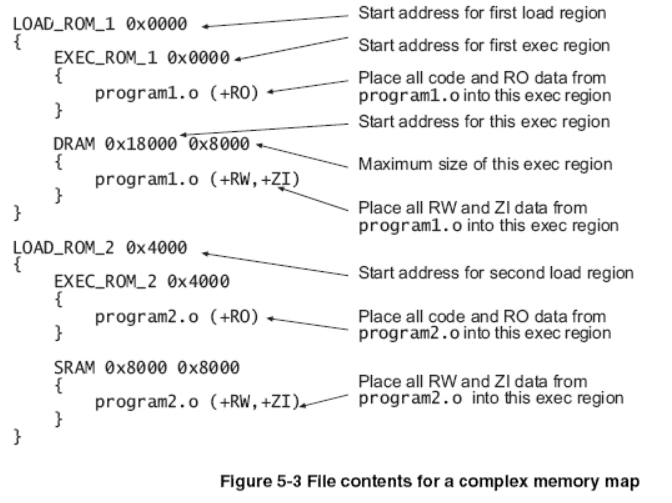
- ROM 에 0x0 번지에는 program1.o 가 저장되어있어.
- 근데 program1.o 에 RO 데이터는 실행 시에 ROM 0x0에서 실행될거고,
- program1.o 에 RW, ZI 데이터는 실행 시에 DRAM의 0x18000에 0x8000 만큼 저장되어있을거고 거기서 가져오면 돼.
- ROM 에 0x4000 번지에는 program2.o 가 저장되어있어.
- 근데 program2.o 에 RO 데이터는 ROM에 0x4000 번지에서 그대로 들고 올거고,
- RW, ZI 데이터는 실행 시에 SRAM 에 0x8000 에 0x8000 만큼의 크기에 저장해서 거기서 실행할거야.
