📖 LB
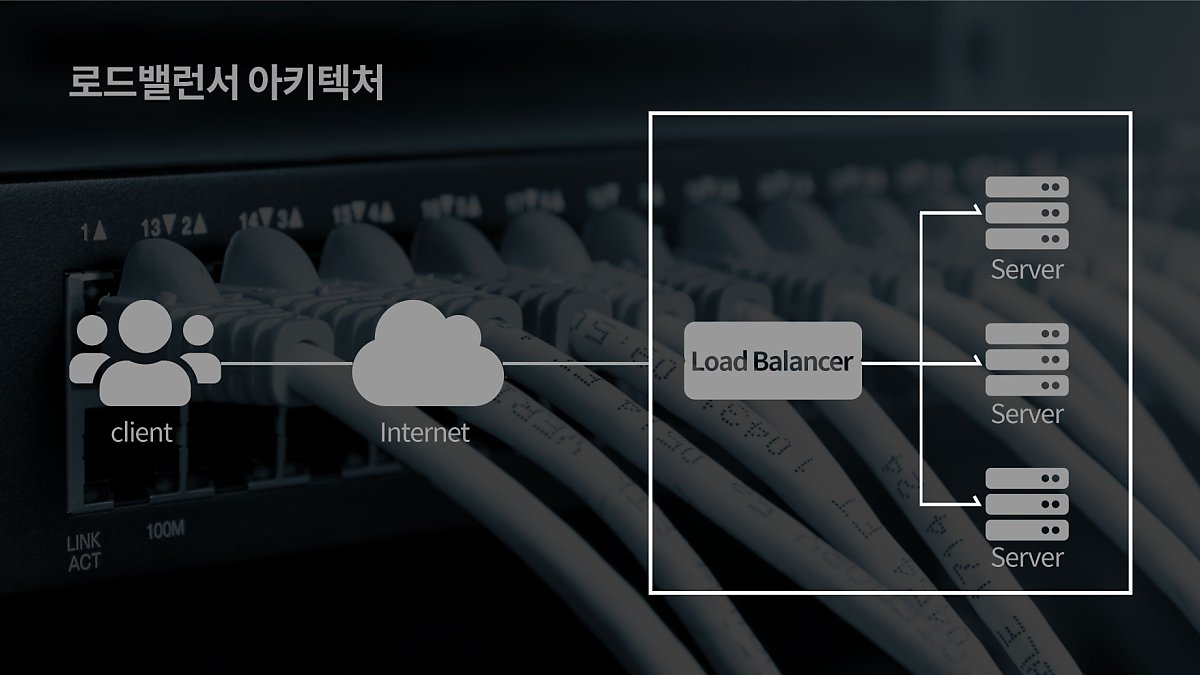
뒤에 나올 Eureka를 위해 LB를 먼저 알아보자
대부분의 서비스는 인터넷을 이용한다. 댓글, 로그인, 검색, 스트리밍, 채팅까지 사실상 인터넷이 없이는 불가능한 일이다.
유튜브나 네이버같이 유저의 요청이 엄청나게 많은 회사에서 서버가 한개라면 요청을 버틸 수 있을까?
절대 못버틴다.
그래서 돈 좀 있는 회사는 서버를 여러대 준비하고있다.
여기서 많은 서버에 트래픽을 골고루 분산하기 위해 배분해주는 기술이 필요한데, 이 때 이용되는 것이 LB(Load Balancer)이다.
✍ 그래서 LB 어떻게 써먹는디
LB는 MSA의 각 모듈에 대한 연결 정보(ip, port, hostname)를 알고 있다. 우리는 각 모듈의 연결 정보를 LB에 등록해야 한다.
또 다른 일도 해줘야한다.
CI/CD를 수행하면서 각 모듈은 계속해서 업그레이드 된다.
그 과정을 통하면서 연결정보가 바뀌게 되고 그럼 그 때마다 LB에 새롭게 등록해야한다.
뒤지게 귀찮다. 그래서 나온것이 Eureka다
넷플리스는 신이야!
📖 Eureka
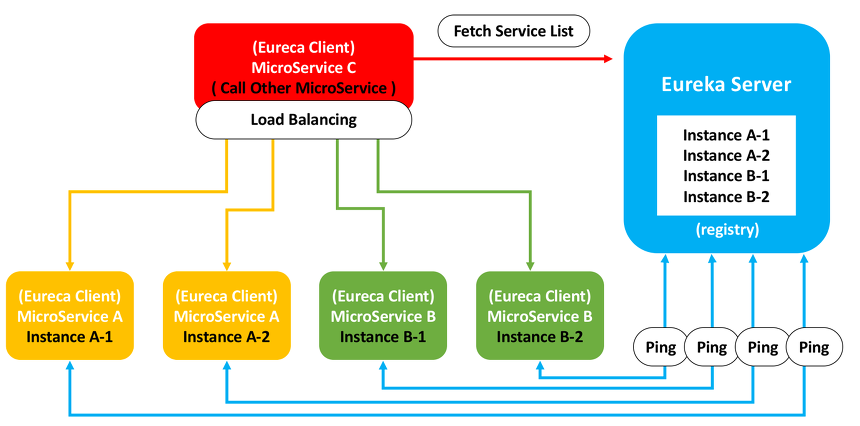
Eureka는 Netflix에서 제공한 MSA를 위한 클라우드 오픈소스이다.
LB와 Middle-tier-server에 에러 대응을 위해 만든 Rest 기반의 서비스이며, 서비스 디스커버리로 정의할 수 있다.
유레카는 Client < - > Server의 방식으로 동작하며
각각의 인스턴스는 하나의 클라이언트와 같고, 본인들의 IP와 Port 그리고 Instand Id를 Eureka Server로 전달하고 이를 Fetch 하는 방식으로 클라이언트와 통신한다.
👍 Eureka의 중요성
- MSA는 주로 Cloud 환경에서 이루어지고, Cloud는 수시로 서버가 늘어나거나 줄어들거나한다.
- 로드 밸런싱을 위해선 LB가 ip, Port등의 정보를 가져야 하는데 서버의 수가 달라질때마다 이걸 수동으로 기록하는건..음...
- 유레카는 등록과 해지, Fetch 등의 개념을 구체화하여 이를 자동화 해준다.
📌 Fetch가 뭐임?
Fetch는 간단하게 말하면 서비스의 인스턴스 정보를 Eureka서버에서 가져오는 동작을 의미한다.
git에서 많이 봤죠?
Eureka는 서비스 디스커비를 위해 사용되며, 클라이언트가 서비스 인스턴스를 찾아내고 해당 서비스와 통신하기 위해 Eureka서버로 부터 정보를 가져온다.
클라이언트가 Eureka서버에게 특정 서비스의 인스턴스 목록을 요청함으로써 해당 서비스의 위치를 알아내는데, 이 때 "Fetch"는 이 목록을 가져오는 동작을 의미한다.
📃 동작 방식 요약
- 클라이언트가 서비스를 시작하면서 자신의 정보를 서버에 등록한다.
- 등록된 클라이언트는 서버로부터 다른 클라이언트의 등록정보를 받아 로컬에 저장한다.
- 30초 주기를 서버로부터 변경사항을 받고 변경이 있다면 갱신한다.(주기 변경 가능 -> default가 30초)
- 30초마다 클라이언트가 서버에 핑을 보내는데, 핑이 없다면 Registry에서 제외된다.
✍ 용어를 알고가자
✔ Discovery
서비스의 연결 정보를 찾는 것
✔ Registry
서비스의 연결 정보를 등록하는 것.
✔ Fetch
서버에 등록된 정보를 획득하는 것
✔ Cancel
유레카에 있는 본인의 인스턴스를 삭제하는 것
✔ Time Lag
서버에 등록된 정보가 변동되었을 때, 모든 클라이언트가 알기까지 시간 지연
REST, MSA, 클라우드는 절대 잊지 말자
Eureka는 Rest니까 JAVA가 아니여도 됨.
