📖 awk란?
데이터를 조작하고 리포트를 생성하기 위해 사용하는 언어이다.
- 형식
awk 'pattern' filename
awk '{action}' filename
awk 'pattern {action}' filename📖 파일로부터의 입력
우선 vi를 통해 아래와 같은 내용의 awkfile을 생성해보자

⌨ '길동'을 포함하고 있는 라인을 출력하기 위한 명령
awk '/길동/' awkfile💻 출력 결과
⌨ 공백을 기준으로 분리되는 필드 중 왼쪽부터 첫 번째 나오는 필드 출력
awk '{print $1}' awkfile✍ 출력 명령에서 $1은 첫 번째 나오는 필드를 의미
필드는 공백단위로 구분된다.
💻 출력 결과

⌨ 시작 문자가 홍 으로 시작되는 이름 찾기
awk '/홍/{print $1, $2}' awkfile💻 출력 결과

📖 명령어로부터의 입력
awk는 명령어로부터 입력을 받기 위해서 | 파이프기호를 사용할 수 있다.
- 형식
command | awk 'pattern'
command | awk '{action}'
command | awk 'pattern {action}'awk로 df 명령어에서 원하는 정보만 출력하는 예제
df | awk '$4 > 400000'
📖 print 함수
printf 함수는 포매팅이 필요없이 간단히 출력하는데 사용됨
printf 함수는 아규먼트로 변수와 계산된 값 또는 문자열 상수를 받는다.문자열은 큰 따옴표("")로 둘러싸야 한다
콤마는 아규먼트를 분리하는데 사용된다.
⌨ 예제
awk '/정/{print "\t\t안녕하세요? " $1, $2 " 님!"}' awkfile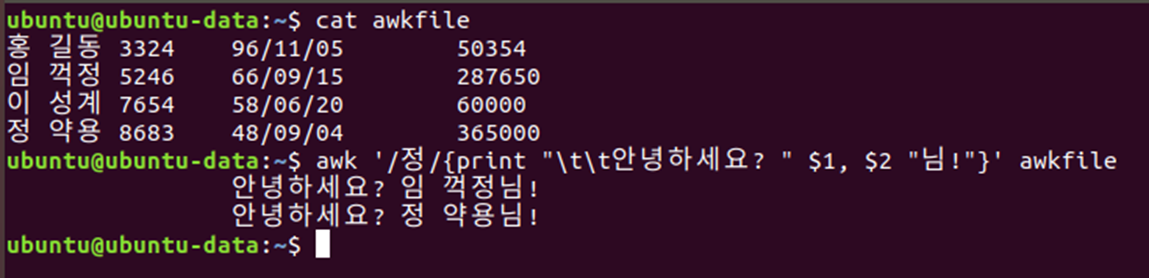
📌 awk -f
awk 액션과 명령이 파일에 작성되어 있다면 -f 옵션을 사용함
awk 명령을 특정한 파일에 저장해두고 이 파일에 입력된 명령을 사용하여 다른 파일을 처리하고자 할 때 사용하는 것이 -f 옵션이다.
- 형식
awk -f [awk 명령파일][awk 명령을 적용할 텍스트 파일]
예제 전에 awkcommand 파일에 아래와 같은 내용을 입력해두자

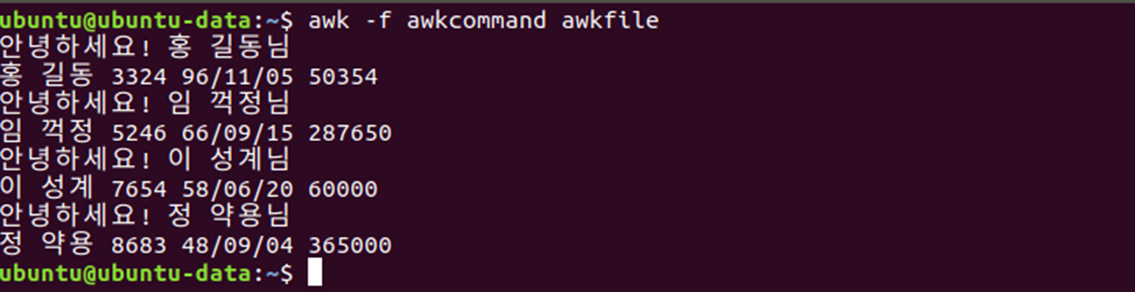
⌨ 예제
awk -f awkcommand awkfileawkfile 을 awkcommand 형식으로 결과를 내라는 의미
💻 출력
📖 레코드와 필드
📌 레코드
- awk는 입력데이터를 볼 수 없지만 포맷 또는 구조는 볼 수 있음. 기본적으로 레코드라고 불리는 각 라인은 캐리지 리턴(newline)으로 분리된다.
- 모든 레코드는 awk에서 $0로 참조된다.
awk는 디폴트로 print액션만 사용해도 모든 레코드를 출력해준다.

각 레코드들의 번호는 awk의 빌트인 변수 NR에 저장됨
레코드가 저장된 다음 NR의 값은 하나씩 증가된다.

📌 필드
- 각 레코드는 디폴트로 공백이나 탭으로 분리된 필드라는 워드로 구성된다.
- 각 워드들은 하나의 필드라고 부르며 awk는 빌트인 변수인 NF에 필드의 수를 유지한다.
NF의 값은 일반적으로 라인당 100개의 필드를 가질 수 있다.
여태까지 쓰던 $1 $2는 필드를 호출하는 녀석이다.

📖 패턴과 액션
📌 패턴
awk 패턴은 awk가 입력 라인에 어떤 액션을 할 것인지 관리한다.
- 이 패턴은 정규표현식, 참과 거짓 상태의 결과 또는 이드르이 결합으로 구성되어 있음
- 디폴트 액션은 표현식이 참의 상태인 각 라인을 출력하는 것임
⌨ 예제
- 정 약용 문자열이 포함된 레코드 라인 출력
awk '/정 약용/{print $0}' awkfile
혹은
awk '/정 약용/' awkfile- 3번 필드의 값이 6000보다 작은 레코드를 출력
awk '$3 < 6000' awkfile📌 액션
- awk에서 액션은 컬리 브레이스({})로 둘러싸인 문장이며 세미콜론(;)으로 구분된다.
- 패턴은 액션 앞에 오며 액션은 간단한 문장 또는 복잡한 문장들의 그룹으로 만들 수 있다.
- 문장들은 세미콜론(;) 또는 newline에 의해 분리된다.
pattern{ action statement; action statement; etc. }
또는
pattern{
action statement
action statement
}⌨ 예제
- 레코드가 패턴인 "정 약용" 문자열을 포함하고 있으면 "안녕하세요, 정 약용님" 문자열을 출력
awk '/정 약용/{print "안녕하세요,"$1, $2 "님"}' awkfile
액션이 없는 패턴은 패턴과 매칭되는 모든 라인을 출력한다.
문자열 매칭 패턴은 슬래시(/)로 둘러싸인 정규 표현식을 포함함

📖 awk와 정규 표현식
awk에서 정규 표현식은 슬래시(/)로 둘러싸인 문자들로 구성된 패턴이다.
- 입력 라인에서의 문자열은 정규 표현식으로 매칭되고 결과 상태는 참이며, 표현식과 연관된 액션들이 실행된다.
- 지정된 액션이 없고 정규 표현식에 의해 매칭된 라인이 검색되며 레코드 라인 전체가 출력됨.

⌨ 예제
- 정 으로 시작하는 레코드 라인을 찾아서 1~3번 필드의 내용만 출력
awk '/^정/{print $1,$2,$3}' awkfile
- 대문자로 시작하고 두 번째 문자부터 소문자를 하나 이상 포함하고 있으며, 그 두의 공백이 있는 라인을 출력
awk '/^[A-Z][a-z]+ /' awkfile2📖 match 연산자
틸드(~)로 표기되는 match 연산자는 하나의 레코드 또는 필드 안에서 표현식과 매칭되는 것이 있는지 검사하는 연산자이다.
⌨ 예제
- 2번 필드에 대문자 Kil 또는 kil과 매칭되는 것이 있는지 검색하고 검색된 결과가 있다면 해당 라인 출력
awk '$2 ~ / [Kk]il/' awkfile2- 2번 필드가 g로 끝나지 않은 라인을 검색하고 출력
awk '$2 !~ /g$/' awkfile2📖 스크립트 파일에서의 awk
- 여러 개의 awk 패턴과 액션을 사용하고자 할 경우에는 스크립트 문장을 입력하여 사용한다.
- 스크립트는 awk 코멘트와 문장을 포함하고 있는 파일이다.
✍ 스크립트파일 작성 요령
- 문장들과 액션들이 같은 라인에 있으며 세미콜론(;)으로 구분해 주어야 함
- 분리된 라인에서는 세미콜론이 필요하지 않음
- 패턴 다음에 액션이 올 때 열기 컬리 브레이스({})는 패턴과 같은 라인에 두어야 한다.
⌨ 예제
vi awkcommand2
/동/{printf "안녕하세요! " $1, $2"님"}
/성계/{print NR "번 라인: "$0}; /^정/{print "'정'으로 시작되는 이름은 : " $1, $2}}💻 출력 결과

📖 비교 표현식
비교 표현식은 어떤 상태가 참일 때만 액션이 수행되는 라인을 검색한다.
이 표현식은 관계 연산자를 사용하고 숫자나 문자열을 비교할 때 사용
⌨ 예제
- 3번 필드의 값이 8683인 라인을 찾아 출력
awk '$3 == 8683' awkfile- 3번 필드의 값이 7000보다 큰 값인 라인에서 1번 필드와 2번 필드만 출력
awk '$3 > 7000{print $1, $2}' awkfile- 2번 필드에 정규 표현식을 사용하여 "꺽정"이라는 문자열이 없는 라인을 찾아서 출력
awk '$2 !~ /꺽정/' awkfile📖 awk 변수
✍ awk 변수 주의점
- 변수는 문자가 될 수도 있고, 숫자와 문자를 결합한 값이 될 수도 있다.
- 변수를 설정하면 = 기호 우측 표현식의 타입이 된다.
- 변수를 초기화하지 않으면 0또는 공백문자(" ")가 된다.
⌨ 변수 선언 예시
name="Tom" #name 변수는 문자열
x++ #x변수는 숫자이며 0으로 초기화되고 1 증가함
number=100 #number 변수는 숫자임⌨ 형 변환
- 문자열을 숫자형으로
name+0- 숫자형을 문자열로 강제 변환
number " "📌 사용자 정의형 변수
사용자 정의형 변수는 awk에서 따로 정의하지 않는다.
- 표현식 안에서 변수의 전후 사정에 의해 데이터 타입이 추측됨
- 변수는 awk의 대입 연산자에 의해 값을 할당 받는다.
⌨ 예시
awk '$1 ~ /이/{sum=$3 +$5; print sum}' awkfile 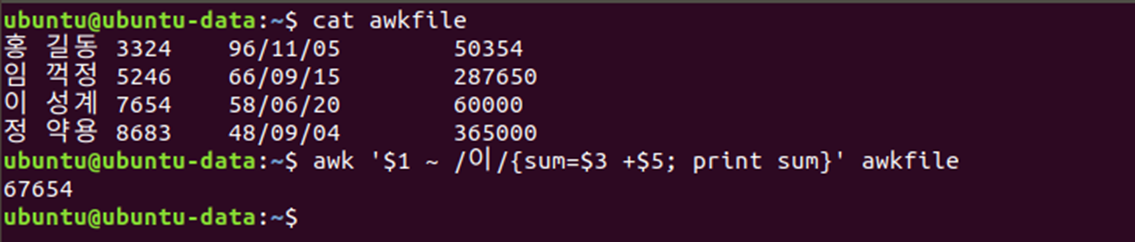
- 증감 연산자
awk 'BEGIN{x=1; y=x++; print x, y}'
# 결과
2 1
awk 'BEGIN{x=1; y=++x; x, y}'
# 결과
2 2📌 BEGIN 패턴
BEGIN 패턴은 awk가 입력 파일의 라인을 처리하기 이전에 실행되어 액션 블록 앞에 놓인다.
BEGIN 블록은 awk가 BEGIN 액션 블록이 완료될 때까지 입력을 읽어 들이지 않기 때문에 입력 파일 없이 테스트 가능함

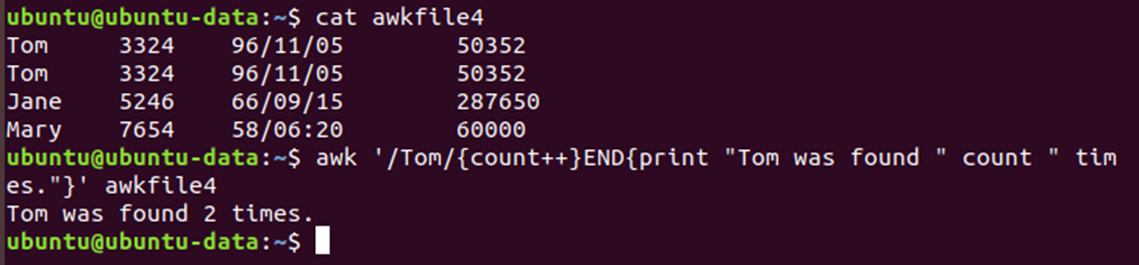
📌 END 패턴
END 패턴은 어떤 입력 라인과도 매칭되지 않으나 END 패턴과 연관된 액션들을 실행한다.
- END 패턴은 입력의 모든 라인이 처리된 후에 처리된다.
📖 입력 리다이렉션
getline 함수는 표준 입력, 파이프, 현재 처리되고 있는 파일로부터 입력을 읽기 위해 사용한다.
⌨ 예제
awk 'BEGIN{"date" | getline d; print d}'💻 출력 결과

📖 awk 파이프
awk 프로그램에서 파이프를 오픈할 때 또 다른 파이프를 오픈하기 전에 기존 파이프는 닫아주어야 한다.
- 파이프 심볼의 오른쪽 명령은 큰따옴표(" ")로 둘러쌈
⌨ 예제
- 차종에 관한 문자열을 담고 있는 cars 파일 오픈
awk '{print $1 | "sort -r"}' cars📌 파일과 파이프 닫기
awk 프로그램에서 파일이나 파이프를 다시 읽고 쓰기 위해서는 첫 번째 파이프는 닫아주어야 한다.
- 스크립트가 끝날 때 까지 오픈된 상태로 남아 있기 때문
- 첫 번째 라인에 있는 END 블록은 앞서 사용한 파이프를 닫아주는 역할을 한다.
awk '{print $1 | "sort -r"} END{close("sort -r")}' cars
📌 빌트인 내장 함수 system
system 함수는 아규먼트를 포함한 리눅스 시스템 명령들을 실행하여 awk 프로그램에게 종료상태를 리턴해준다.
- 리눅스 명령은 반드시 큰따옴표(" ")로 감싸주어야 한다.
⌨ 예제
vi awkscript
{
system("cat" $1)
}
awk -f awkscript awktext📖 반복문
📌 while
while 루프에서는 먼저 임의의 변수에 초기값을 젖아함
- 이 값은 while문의 조건 표현식에서 테스트된다.
- 표현식이 참이면 루프 아래의 문장들을 실행함
- 실행할 문장의 수가 많다면 { }로 감싸줘야 한다.
⌨ 예제
awk '{i = 1; while ( i <= NF ) {print NF, $1; i++}}' awkdata📌 for
for 루프는 괄호 안에 초기화 표현식, 테스트 표현식, 테스트 표현식의 변수를 업데이트 하기 위한 표현식과 같은 3개의 표현식을 사용하며 각 표현식은 세미콜론으로 분리한다
✍ break와 continue 문장
- 일반적인 프로그래밍 언어와 똑같다.
⌨ 예제
vi awkscripts2
{
for(i = 1; i <= NF; i++)
if ($i < 0) {
print "0보다 작은 값 발견 = " $i; break
}
}📖 next 문장
next 문장은 입력 파일로부터 입력의 다음 라인을 가져오고 awk 스크립트의 시작부터 다시 실행한다.
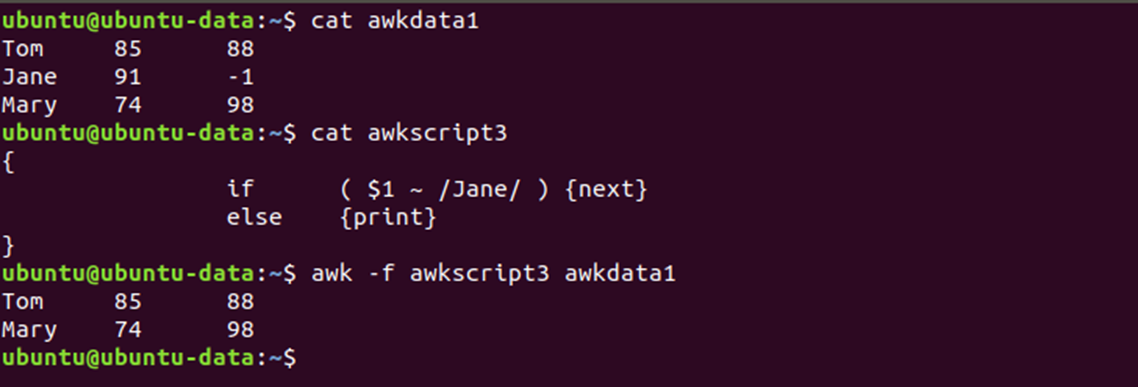
이런식으로 쓰는데 아마 거의 안쓰지 않을까 싶다.
아래처럼 해도 같은 결과가 나오고 훨씬 간결해지니깐..
고로 시험에도 안나오지 않을까? 히힣
if( $1 !~ /Jane/ ) {print}📖 연관 배열을 위한 서브 스크립트
📌 배열과 split 함수
awk의 빌트인 내장함수인 split 함수는 단어와 배열에 저장된 문자열을 자르기 위해 사용한다.
- 형식
split(문자열, 배열, 필드 분리자)
split(문자열, 배열)⌨ 예제
awk 'BEGIN{split("2023/7/21", date, "/");
print "오늘은 " date[1] "년" date[2] "월" date[3] "일입니다."}'📌 delete 함수
배열의 요소를 제거
awk 'BEGIN{split("2023/7/21", date, "/"); delete date[1];
print "오늘은 " date[1] "년" date[2] "월" date[3] "일입니다."}'📖 문자열 함수
📌 sub와 gsub 함수
- sub 함수는 레코드에서 정규표현식에 매칭되는 문자열을 찾아서 원하는 문자열로 치환하는 기능을 수행
- 이 때 치환은 각 라인에서 가장 먼저 매칭되는 하나의 문자만 치환
- 매칭되는 문자열 모두를 치환하려면 gsub 함수를 사용
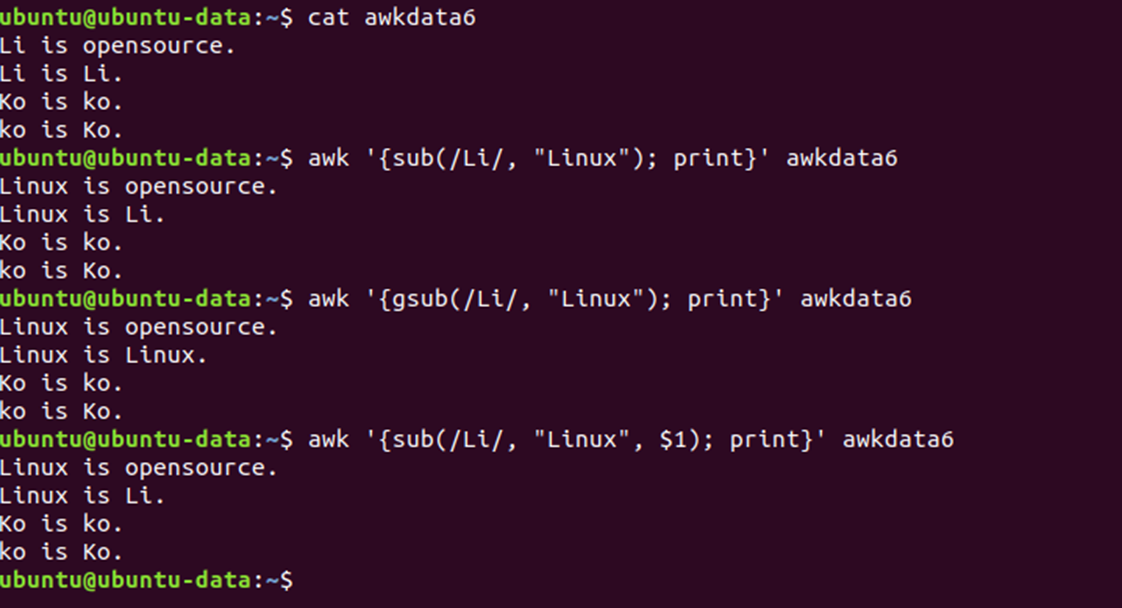
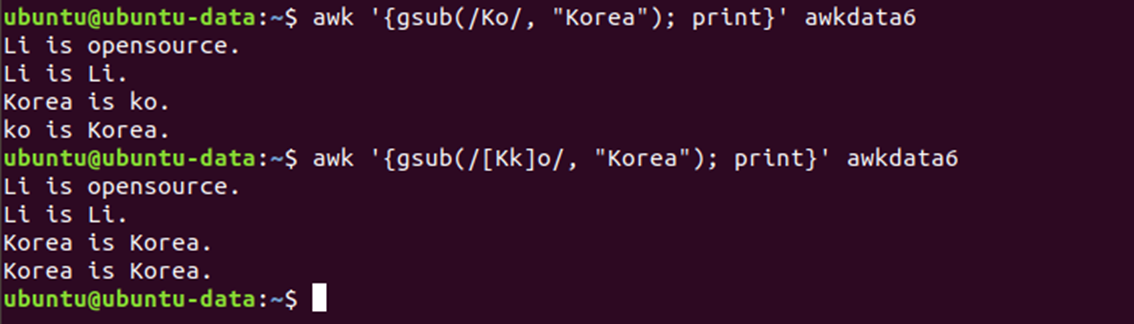
📌 index 함수
index 함수는 문자열에서 substring이 발견되는 첫 번째 위치를 리턴
- 형식
index(string, substring)⌨ 예제
awk 'BEGIN{print index("hello","lo")}'📌 length 함수
length 함수는 문자열에서 문자의 개수를 리턴한다
아규먼트 없이 사용하려면 length 함수의 한 레코드의 문자 개수를 리턴함
- 형식
length(문자열)
length
📌 substr 함수
substr 함수는 주어진 문자열로부터 지정된 시작 위치의 앞까지 모두 자른 다음 남아있는 문자열을 리턴
- 형식
substr(문자열, 시작 위치)
substr(문자열, 시작 위치, 문자열 길이)
📌 match 함수
match 함수는 정규표현식에 매칭되는 문자열이 있는 곳의 인덱스를 리턴한다
- 형식
match(문자열, 정규표현식)
📌 toupper와 tolower
영어로 된 문자열을 대문자 혹은 소문자로 변경해줌

📖 awk 수학적 빌트인 함수
📌 정수형 함수
- int 함수는 주어진 데이터를 정수형으로 만들어준다
- 실수형 데이터가 주어지면 dot(.)이하의 데이터들은 모두 제거

