SQLD
1.------1과목------

2.ENTITY
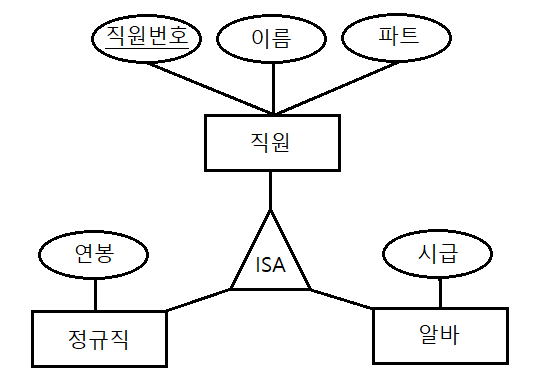
사람, 장소, 물건, 사건, 개념 등의 명사에 해당, 저장이 되기위한 어떤 것(Thing)유형, 무형의 정보업무상 관리가 필요한 관심사에 해당함. 업무에서 필요로 하는 정보이어야 한다.유일한 식별자에 의해 식별이 가능해야 함영속적으로 존재하는 인스턴스의 집합 두개 이
3.속성(Attribute)
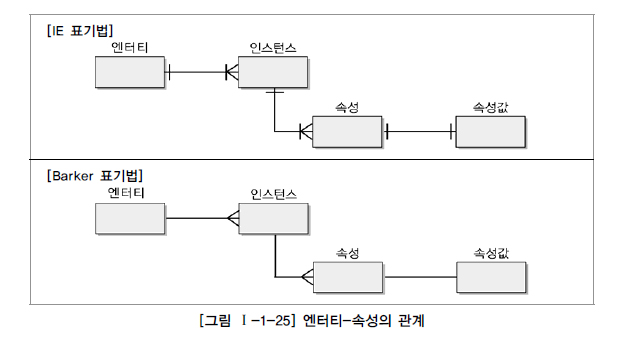
속성의 개념과 정의 > 업무에서 필요로 하는 인스턴스로 관리하고자 하는 의미상 더 이상 분리되지 않는 최소의 데이터 단위 >>- 업무에서 필요로 한다. 의미상 더 이상 분리되지 않는다. 엔터티를 설명하고 인스턴스의 구성요소가 된다.
4.관계(Relationship)
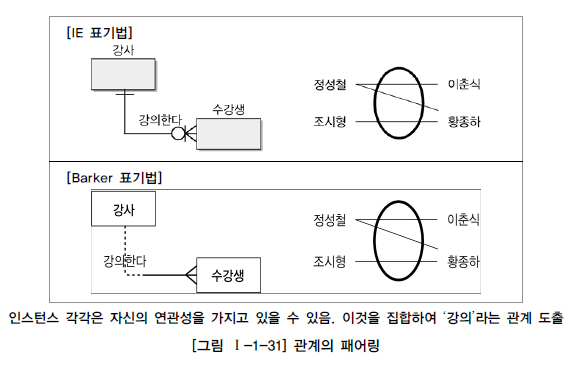
엔터티의 인스턴스 사이의 논리적인 연관성으로서 존재의 형태로서나 행위로서 서로에게 연관성이 부여된 상태, 관계 페어링의 집합ex) 강사 - 가르친다(관계) - 수강생페어링 : 엔터티 안에 인스턴스가 개별적으로 관계를 가지는 것유의해야 할 점은 관계는 패어링을 집합의 관
5.식별자(Identifiers)
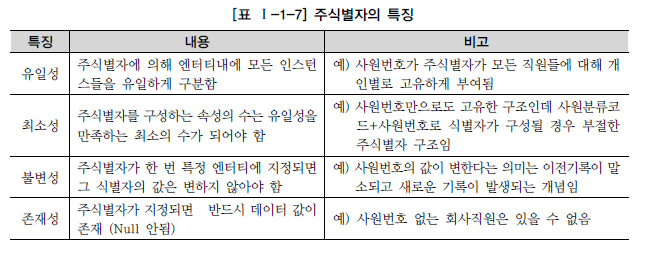
엔터티는 인스턴스들의 집합이다.그렇다면 여러 개의 집합체를 담고 있는 하나의 통에서 각각을 구분할 수 있는 논리적인 이름이 있어야 하는데 이 구분자를 식별자라고 한다.엔터티 내에서 인스턴스를 구분하는 구분자 식별자는 논리적, Key는 물리적 데이터 모델링에서 사용된다.
6.데이터 모델링
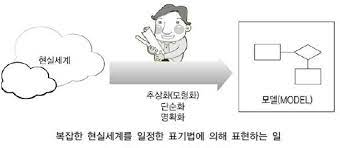
1.데이터 모델의 개요 ※정보화 시스템 구축 현실세계에서 일어나는 사건들을 전산화 하기 위한 것. 정보화 시스템 과정에서 구축된 데이터베이스는 현실세계의 특정부분을 반영 현실세계를 개념화 단순화 하여 가시적으로 표현한 것 > 이런식
7.성능 데이터 모델링
성능 데이터 모델링이란 데이터베이스 성능향상을 목적으로 설계딴계의 데이터 모델링 때부터 정규화, 반정규화, 테이블 통합, 테이블 분할, 조인구조, PK,FK등 여러가지 성능과 관련된 사항이 데이터 모델링에 반영될 수 있도록 하는것.분석/설계 단계에서 데이터 모델에 성능
8.정규화(Normalization)
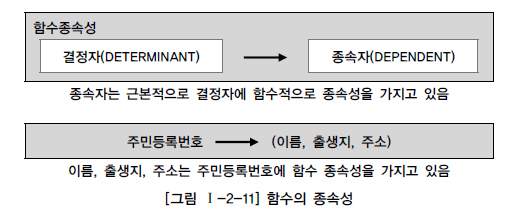
데이터들이 어떤 기준값에 의해 종속되는 현상반복적인 데이터를 분리하고 각 데이터가 종속된 테이블에 적절하게 배치되도록 하는 것.데이터의 중복속성을 제거하고 결정자에 의해 동일한 의미의 일반속성이 하나의 테이블로 집약되므로 한 테이블의 데이터 용량이 최소화되는 효과가 있
9.반정규화(De-Normailzation)
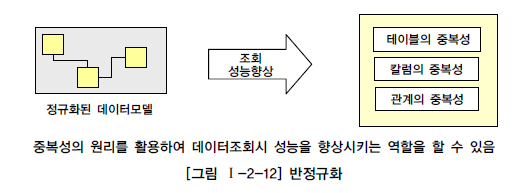
반정규화 = 역정규화 같은 표현이다.정규화된 엔터티, 속성, 관계에 대해 시스템의 성능향상과 개발과 운영의 단순화를 위해 중복, 통합, 분리등을 수행하는 데이터 모델링의 기법협의의 반정규화는 데이터를 중복하여 성능을 향상시키기 위한 기법조회 시 디스크 I/O가 많거나
10.대량 데이터
하나의 테이블에 대량의 데이터가 존재하는 경우에는 인덱스의 Tree구조가 너무 커져 효율성이 떨어져 데이터를 처리(입력,수정,삭제,조회)할 때 디스크 I/O를 많이 유발하게 된다.한 테이블에 많은 수의 칼럼이 존재하게 되면 데이터가 디스크의 여러 블록에 존재하므로 인해
11.데이터베이스 구조와 성능
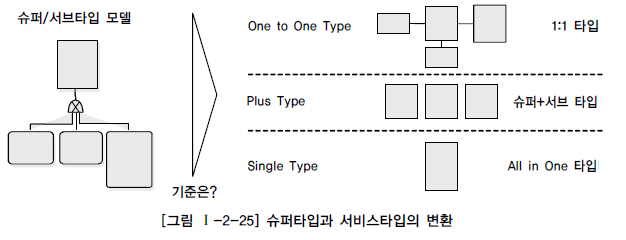
Extended ER모델이라고 부르는 슈퍼/서브타입 데이터 모델은 논리적인 데이터 모델에서 이용되는 형태이고 분석단계에서 많이 쓰이는 모델이다.따라서 물리적인 데이터 모델을 설꼐하는 단계에서는 슈퍼/서브타입 데이터 모델을 일정한 기준에 의해 변환해야 한다.물리적인 데이
12.분산 데이터베이스
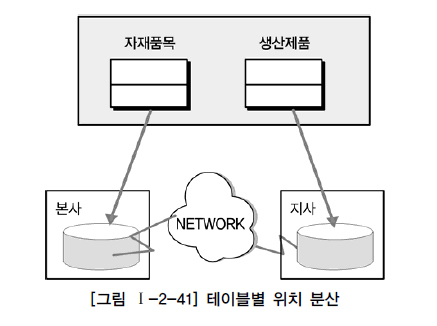
여러곳으로 분산되어있는 DB를 하나의 가상 시스템으로 사용할 수 있도록 한 DB논리적으로 동일한 시스템에 속하지만, 컴퓨터 네트워크를 통해 물리적으로 분산되어 있는 데이터들의 모임.분할 투명성 (단편화) : 하나의 논리적 Relation이 여러 단편으로 분할되어 각 단
13.------2과목 1장 SQL 기본 개요------
여기서 부터 2과목 시작
14.관계형 데이터베이스
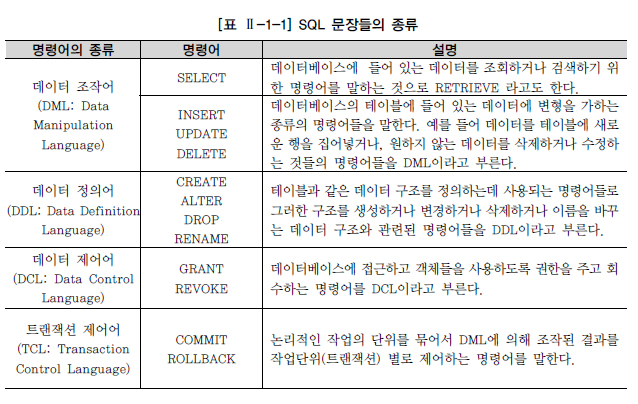
특정 기업이나 조직 또는 개인이 필요에 의해 데이터를 일정한 형태로 저장해놓은 것.1\. 정규화를 통해 이상(Anomaly)현상을 제거하고 데이터 중복을 피할 수 있다.2\. 동시성 관리, 병행제어를 통해 데이터 공유3\. 데이터의 표현방법체계화 및 데이터 표준화, 데
15.DDL(데이터 정의어)
SQLD 시리즈에 있는 모든 쿼리문은 Oracle 기준으로 작성됩니다.데이터 유형은 데이터베이스의 테이블에 특정 자료를 입력할 때, 그 자료를 받아들일 공간을 자료의 유형별로 나누는 기준이다.테이블에 존재하는 모든 데이터를 고유하게 식별할 수 있으면서 반드시 값이 존재
16.DML(데이터 조작어)
테이블의 관리하기를 원하는 자료들을 입력, 수정, 삭제, 조회하는 데이터 조작어.해당 칼럼명과 입력되어야 하는 값을 서로 1:1로 매핑해서 입력해야한다.칼럼의 데이터 유형이 날짜형 혹은 CHAR 혹은 VARCHAR2일 경우 \` \` 을 붙여야한다.컬럼리스트를 지정할
17.TCL(트랜잭션 제어어)

TCL이란 DML에 의해 조작된 결과를 작업단위(트랜잭션)별로 제어하는 기능1.데이터 베이스의 논리적 연산단위2.하나의 트랜잭션에는 하나 이상의 SQL문장이 포함된다.3.밀접히 관련되어 분리될 수 없는 한 개 이상의 DB조작4.그렇기 때문에 전부 적용하거나 전부 취소(
18.WHERE(조건절)
사용자들은 WHERE절을 이용하여 자신이 원하는 자료만을 검색할 수 있다.WHERE 절에는 두 개 이상의 테이블에 대한 조인 조건을 기술하거나 결과를 제한하기 위한 조건을 기술할 수도 있다.형식WHERE절은 FROM절 다음에 위치한다.WHERE절에 사용되는 연산자는 3
19.내장 함수(BUILT-IN FUNCTION)
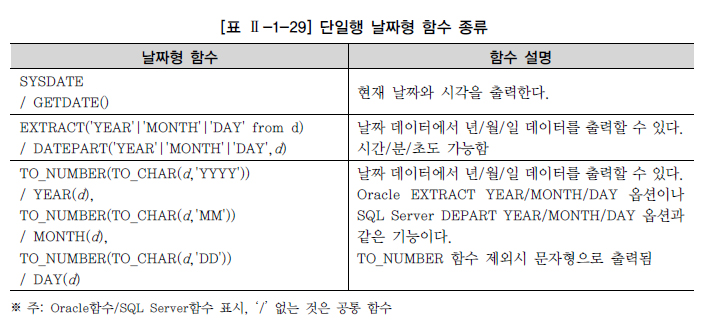
SQL을 더욱 강력하게 해주고 데이터 값을 간편하게 조작하는데 사용한다.단일행 값이 입력되는 단잉핼 함수(Single-Row Function)여러행의 값이 입력되는 다중행 함수(Multi-Row Function)집계 함수(Aggregate Function)그룹 함수(G
20.GROUP BY/HAVING
여러 행들의 그룹이 모여서 그룹당 단 하나의 결과를 돌려주는 함수이다.GROUP BY절은 행들을 소그룹화 한다.SELECT 절,HAVING 절,ORDER BY 절에 사용할 수 있다.해당칼럼에 값이 NULL인 것을 제외하고 계산한다.COUNT(\*)은 NULL값을 포함한
21.ORDER BY 정렬
SQL 문장으로 조회된 데이터들을 다양한 목적에 맞게 특정한 칼럼을 기준으로 정렬하여 출력하는데 사용한다.ORDER BY절에 칼럼명 대신 ALIAS 명이나 칼럼 순서를 나타내는 정수도 사용 가능하다.DEFAULT 값으로 오름차순(ASC)이 적용되며 DESC 옵션을 통해
22.JOIN
두 개 이상의 테이블들을 연결 또는 결합하여 데이터를 출력하는 것.일반적으로 행들은 PK나 FK 값의 연관에 의해 JOIN이 성립된다.5가지 테이블을 JOIN 하기 위해서는 최소 4번의 JOIN과정이 필요하다.(N-1)FROM절에 여러 테이블이 나열되더라도 SQL에서
23.-------2과목 2장 SQL 활용-------
24.표준 조인
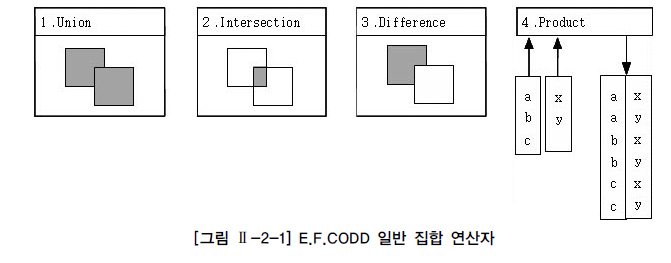
두 개 이상의 테이블에서 조인을 사용하지 않고 연관된 데이터를 조회할 때 사용한다.SELECT 절의 칼럼 수가 동일하고 SELECT 절의 동일 위치에 존재하는 칼럼의 데이터 타입이 상호 호환 가능할 때 사용가능 하다.UNION과 UNION ALL의 결과가 같다면 정렬
25.계층형 질의
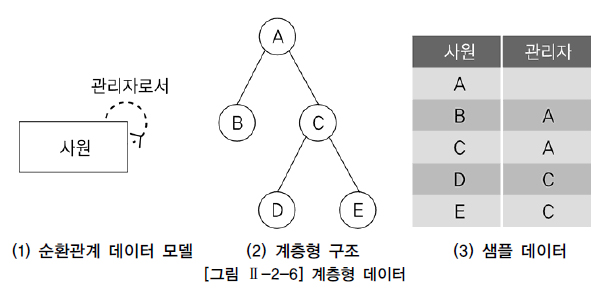
계층형 질의는 테이블에 계층형 데이터가 존재하는 경우 데이터를 조회하기 위해 사용한다.게층형 데이터란 동일 테이블에 계층적으로 상위와 하위 데이터가 포함된 데이터를 말한다.계층형 질의에서 사용되는 구문계층형 질의에서 사용되는 가상 칼럼계층형 질의에서 사용되는 함수\->
26.셀프조인
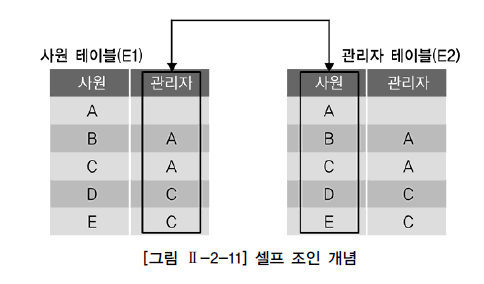
동일 테이블 사이의 조인이다.즉 한 테이블 내 두 칼럼이 연관 관계가 있을 때 동일 테이블 사이의 조인.FROM 절에 동일 테이블이 2번 이상 나타난다. 반드시 테이블 별칭을 사용해야 함.SMITH의 매니저 이름을 구하는 예시\-> 결과
27.서브 쿼리

서브쿼리란 _하나의 SQL문 안에 포함되어 있는 다른 SQL문을 뜻한다. 알려지지 않은 기준을 이용한 검색에 사용함._ 서브쿼리 주의사항 > - 서브쿼리는 반드시 괄호로 둘러 쌓아햐 한다. 서브쿼리는 메인쿼리가 실행되기 이전에 한번만 실행된다. 서브쿼리는 단일 행
28.그룹 함수
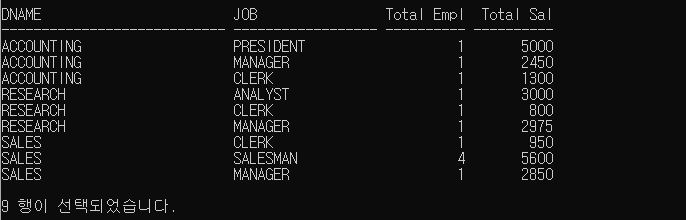
ROLLUP에 지정된 GROUPING COLUMNS LIST는 SUBTOTAL을 생성하기 위해 사용되어지며, GROUPING COLUMNS의 수를 N 이라고 했을 때 N+1 LEVEL의 SUBTOTAL이 생성된다.즉 소그룹간의 합계를 구하는 함수이며,인수 계층 구조인수
29.윈도우 함수
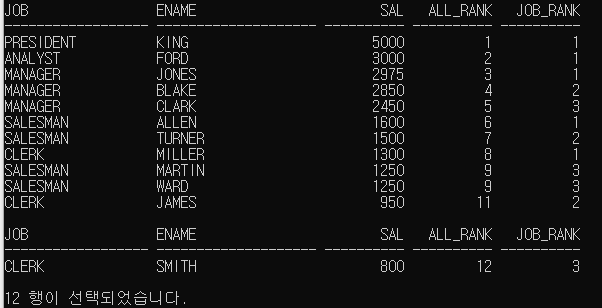
행과 행간의 관계를 정의하거나 행과행간을 비교, 연산하는 함수이며윈도우는 데이터의 집합을 나타내는 개념이다.윈도우 함수의 종류는 크게 5가지로 분류가 된다.1\. 그룹 내 순위 관련 함수 RANK, DENSE_RANK, ROW_NUMBER 2\. 그룹 내 집계
30.DCL
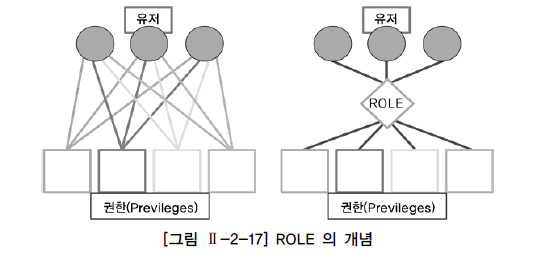
유저를 생성하고 권한을 제어할 수 있는 명렁어 이다.대부분의 DB는 데이터 보호와 보안을 위해서 유저와 권한을 관리함.개별 오브젝트에 대한 작업을 위해서는 오브젝트 권한 부여 필요유저를 통해 DB에 접속하는 형태이다.ID와 PW방식으로 인스턴스에 접속을 하고 그에 해당
31.SQLD 49회 합격 후기

😂😂합격 해부러따😂😂