
Elasticsearch
기존의 DBMS에서는 다루기 어려웠던 분야인 전문 검색과 문서의 점수화를 이용한 정렬, 데이터 증가량에 구애받지 않는 실시간 검색 등을 Elasticsearch를 이용해 구현할 수 있습니다.
Elasticsearch는 RESTful API를 지원하므로 URI를 사용한 동작이 가능하고, 필요한 기능에 대한 plug-in을 손쉽게 설치해서 기능을 확장할 수 있는 등 많은 장점들을 가지고 있습니다.
elasticsearch 검색엔진을 사용하는 이유
- 관계형 데이터베이스는 단순 텍스트매칭에 대한 검색만을 제공
- 상품검색시 MySQL에 LIKE ‘%단어%’ 검색시 완벽한 전문 검색(Full Text Search)은 지원하지 않는다.
하지만 엘라스틱서치는 분석기를 통한 역인덱싱 으로 이것을 완벽하게 지원한다.- 물론 요즘 MySQL 최신 버전에서 n-gram 기반의 Full-text 검색을 지원하지만, 한글 검색의 경우에 아직 많이 빈약한 감이 있습니다.
- 텍스트를 여러 단어로 변형하거나 텍스트의 특질을 이용한 동의어나 유의어를 활용한 검색이 가능
- 엘라스틱서치에서는 관계형 데이터베이스에서 불가능한 비정형 데이터의 색인과 검색이 가능
- 이러한 특성은 빅데이터 처리에서 매우 중요하게 생각되는 부분입니다.
- 엘라스틱서치에서는 형태소 분석을 통한 자연어 처리가 가능
- 엘라스틱서치는 다양한 형태소 분석 플러그인을 제공합니다.
- 역색인 지원으로 매우 빠른 검색이 가능
- 검색 조건으로 Cache Key를 등록하는데 검색조건이 다양하여 Cache 성능이 떨어진다.
인덱스 설정 및 생성
- 인덱스 : RDBMS에서 database와 대응하는 개념
es = Elasticsearch("http://elasticsearch:9200/")
if es.indices.exists(index='dictionary'):
return
else:
es.indices.create(
index='dictionary',
body={
"settings": {
"index": {
"analysis": {
"analyzer": {
"nori_token": {
"type": "custom",
"tokenizer": "nori_tokenizer"
}
}
}
}
},
"mappings": {
"properties": {
"id": {
"type": "integer",
},
"class_name": {
"type": "text",
"analyzer": "nori_token"
},
"price": {
"type": "integer",
},
"img_url": {
"type": "text",
},
"analyze": {
"type": "keyword"
}
}
}
}
)
- 한국어 백과사전 검색에 적합한 인덱스를 생성하기 위해 한글 형태소 분석기 nori를 통해 데이터를 토크나이징할 수 있도록 설정합니다. 예를 들어) 상품명 '짜요짜요 복숭아맛'에서 ('짜요짜요', '복숭아맛')처럼 인덱스를 생성
- mapping은 관계형 데이터베이스의 schema와 비슷한 개념으로, Elasticsearch의 인덱스에 들어가는 데이터의 타입을 정의하는 것입니다. mapping 설정을 직접 해주지 않아도 Elastic에서 자동으로 mapping이 만들어지지만 사용자의 의도대로 mapping 해줄 것이라는 보장을 받을 수 없습니다. mapping이 잘못된다면 후에 Kibana와 연동할 때도 비효율적이기 때문에 Elastic에서는 mapping을 직접 하는 것을 권장합니다. 각 필드의 타입을 정의하고 위에서 설정해준 분석기 ‘nori_token’로 'class_name'를 분석할 수 있도록 설정해줍니다.
- text 타입은 입력된 문자열을 텀 단위로 쪼개어 역 색인 (inverted index) 구조를 만듭니다. 보통은 풀텍스트 검색에 사용할 문자열 필드 들을 text 타입으로 지정합니다.
- keyword 타입은 입력된 문자열을 하나의 토큰으로 저장합니다. text 타입에 keyword 애널라이저를 적용 한 것과 동일합니다. 보통은 집계(aggregation) 또는 정렬(sorting)에 사용할 문자열 필드를 keyword 타입으로 지정합니다.
데이터 세팅
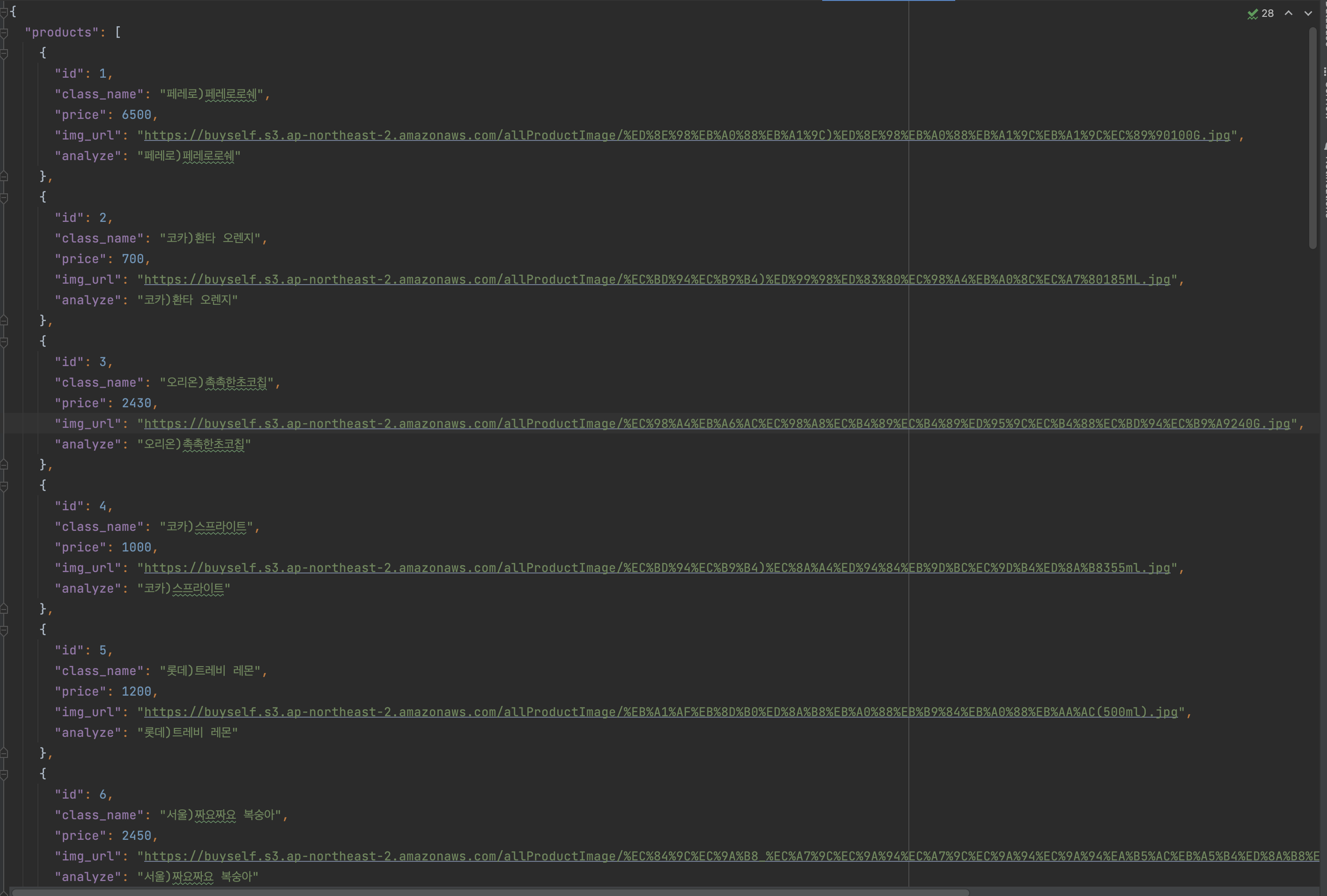
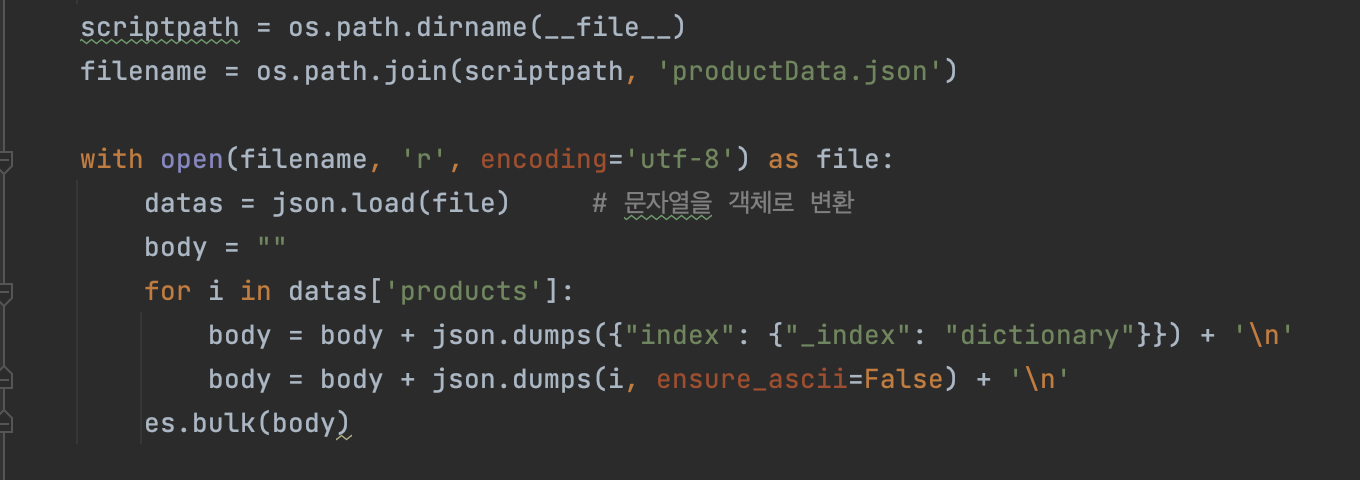
- 상품 데이터셋 Json 파일을 생성 후 여러 개의 데이터를 한 번에 Elasticsearch에 삽입하는 방법인 bulk를 사용하여 백과사전 데이터를 Elasticsearch에 삽입합니다.
Controller 구현
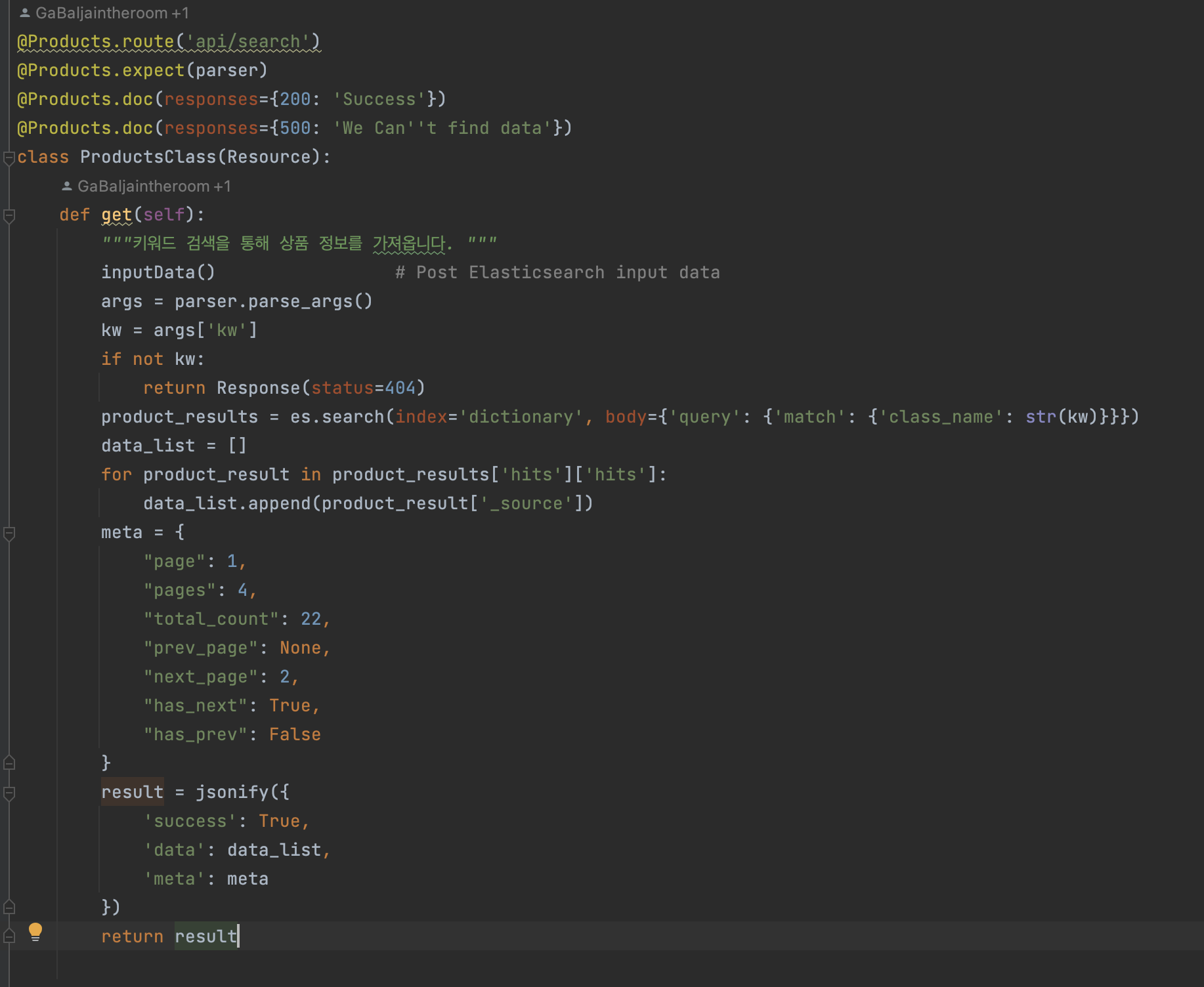
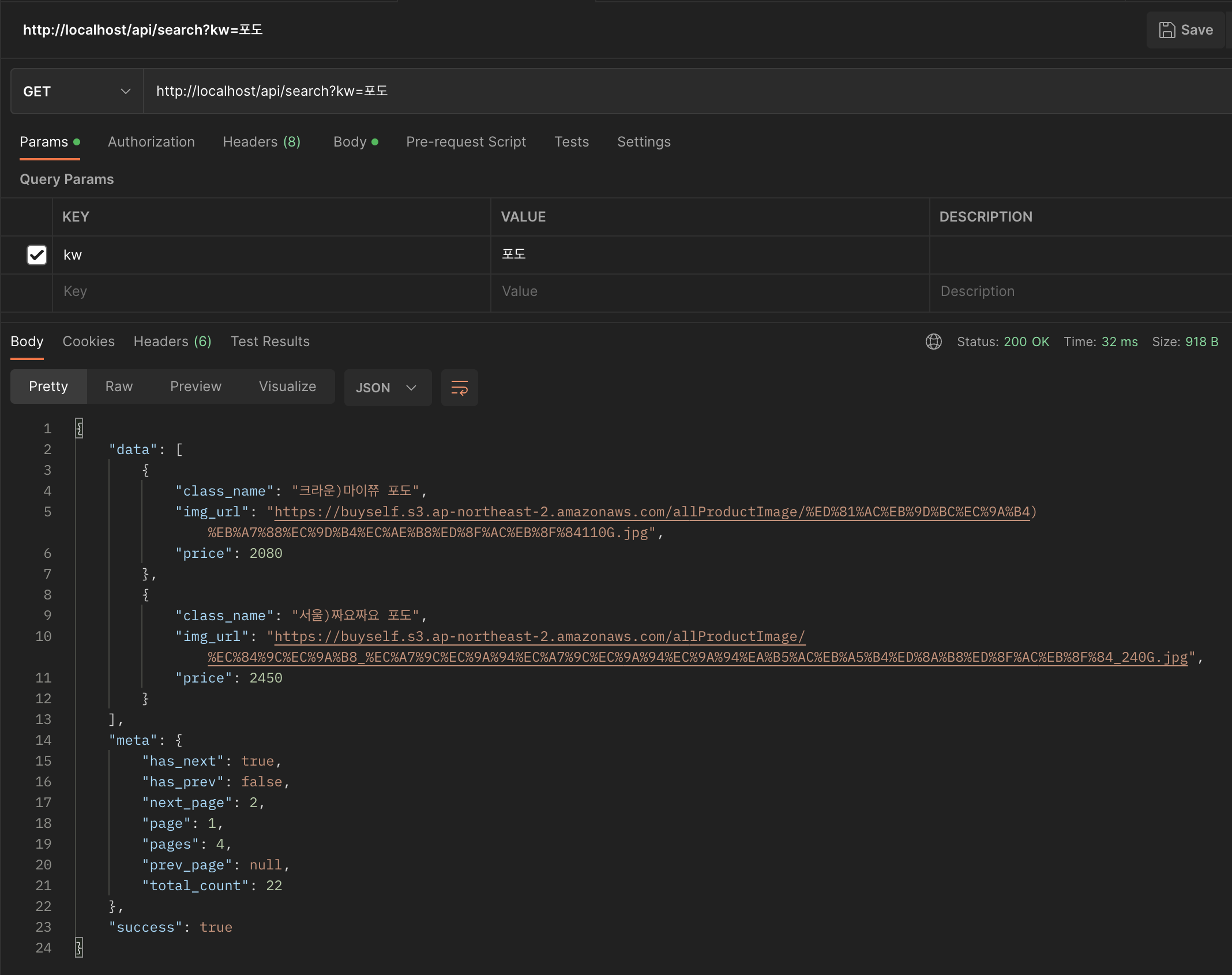
- query DSL를 이용한 상품명 검색하기
- hits ==> 검색결과, hits.hits ==> 검색결과의 실제 배열
그 외..
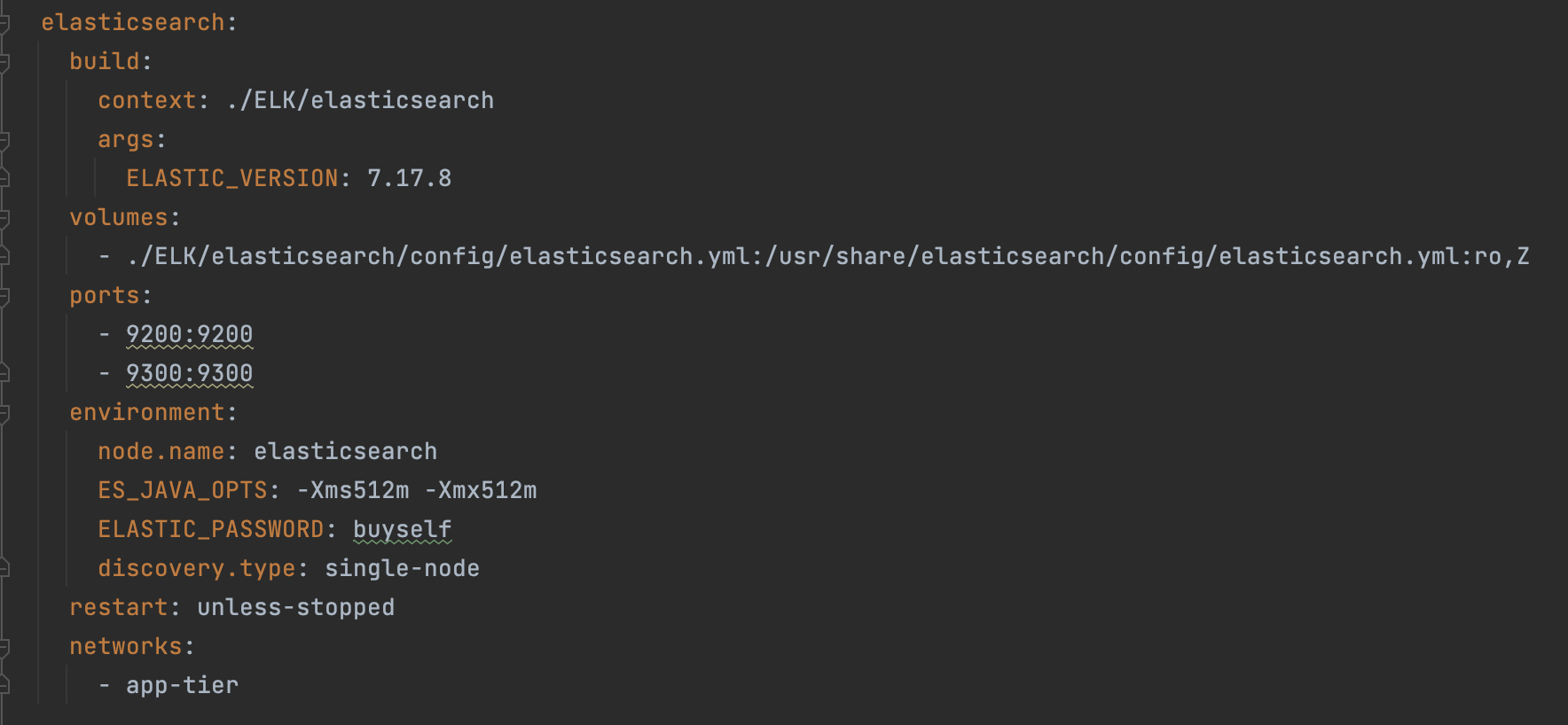 --> elasticsearch 도커 컴포즈 파일 작성
--> elasticsearch 도커 컴포즈 파일 작성
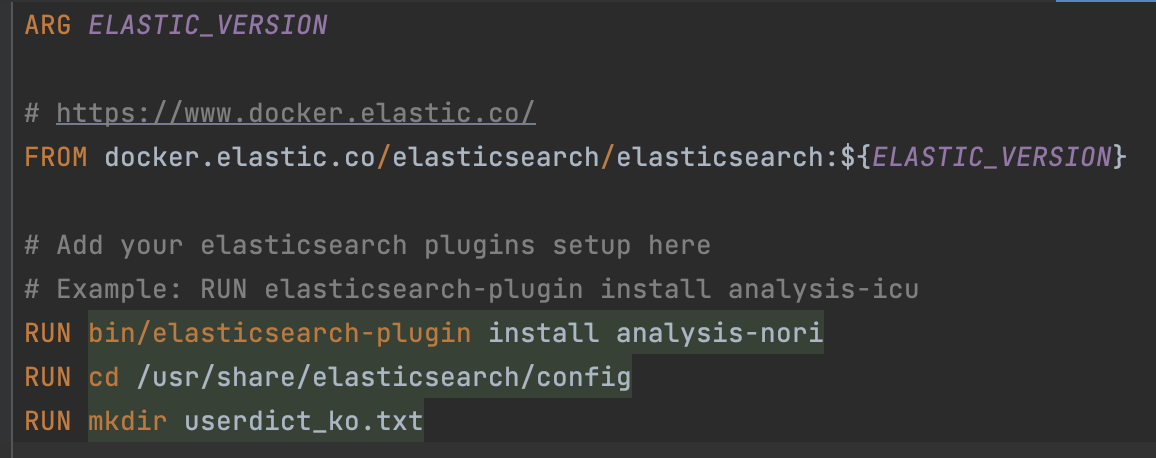 --> elasticsearch 도커 파일 작성
--> elasticsearch 도커 파일 작성
참고 : elasticsearch 기본 개념//elasticsearch 공식 문서//elasticsearch 예제//elasticsearch 검색 엔진 구현

방구석개발자