지연로딩 & 즉시로딩 리마인드 게시글의 환경에 이어 나가겠다.
N+1 문제란?
- 연관 관계에서 발생하는 이슈로 연관 관계가 설정된 엔티티를 조회할 경우에 조회된 데이터 갯수(n) 만큼 연관관계의 조회 쿼리가 추가로 발생하여 데이터를 읽어오게 된다. 이를 N+1 문제라고 한다.
상황
간단 요약
- 팀 엔티티와 멤버 엔티티와 1대다 관계를 가지고 있다.
- 팀 엔티티에는 3개의 데이터가, 멤버 엔티티에는 총 9개의 데이터로 1팀에 5명, 2팀에 3명, 3팀에 1명 순차적으로 관계가 맺어져 있다.
발생 사례
1. 모든 팀을 조회하는데 @OneToMany(fetch = FetchType.EAGER)일 때 발생
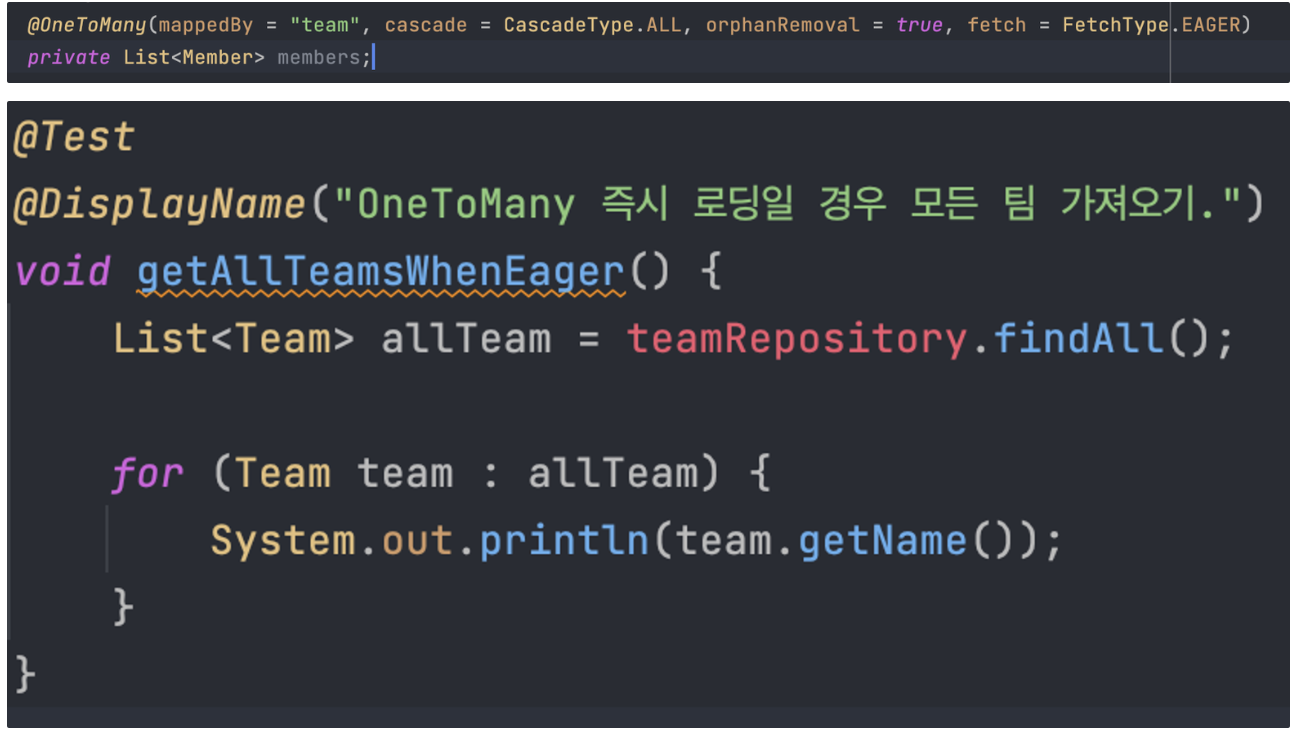
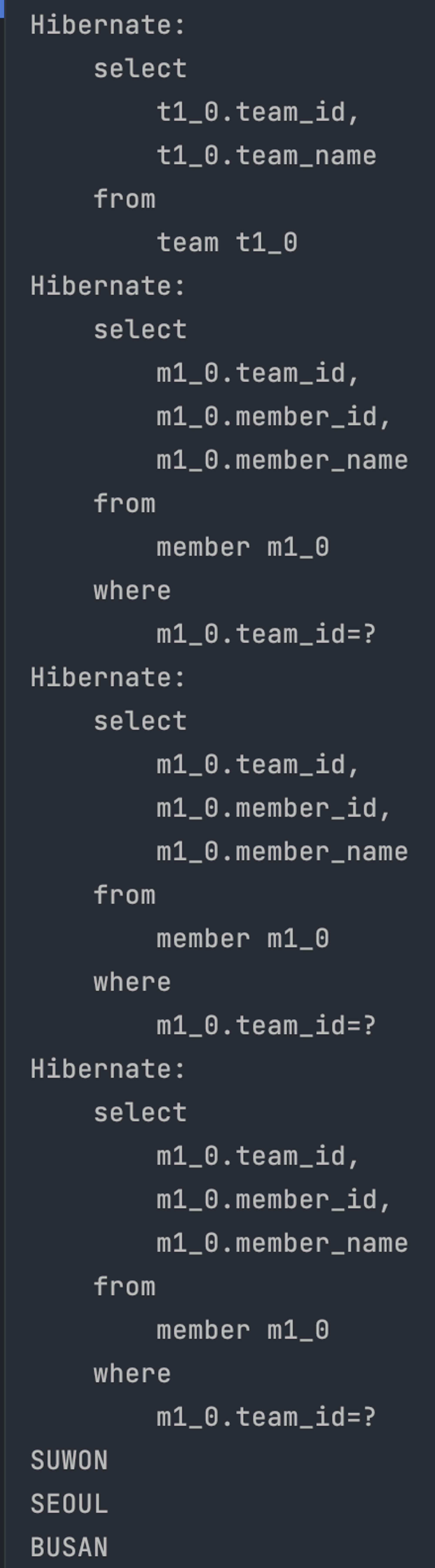
- 다음과 같이 처음 조회된 Team 엔티티의 데이터 갯수 만큼 연관관계의 조회쿼리가 추가적으로 발생한다. → N + 1 문제 발생
- 그러나 @OneToMany는 기본적으로 FetchType이 Lazy라서, 인위적으로 FetchType을 Eager로 변경하지 않는다면 이 N+1문제는 발생하지 않을 것 같다.
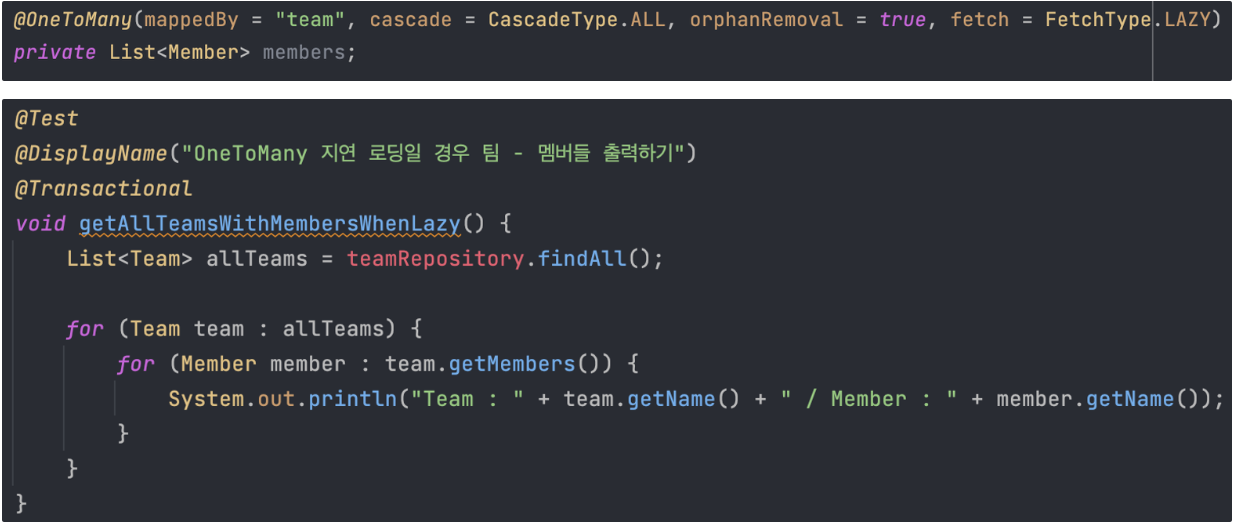
2. 팀 엔티티의 @OneToMany(fetch = FetchType.LAZY)이어도 Member엔티티의 데이터를 사용할 때
![]()
- 참고로 @Transactional을 해주지 않으면 영속성 컨테이너가
teamRepository.findAll();이때 닫혀 지연로딩으로 되어서 붙여줘야 한다. - Fetch 타입이 Lazy였어도 N+1은 발생했다.
- Team 전체 조회 쿼리 1개 (1) + 각 Team별Member 조회 쿼리 3개 (N)
- 만약 Team 데이터가 3개가 아니라 100만개였더라면 한번 조회하는데 100만번의 추가적인 쿼리가 발생하기 때문에 이를 막아야한다.
N+1이 발생하는 이유
- JPQL은 SQL을 추상화한 객체지향 쿼리 언어로서 특정 SQL에 종속되지 않고 엔티티 객체와 필드 이름을 가지고 쿼리를 한다.
- JPQL 입장에서는 연관관계 데이터를 무시하고 해당 엔티티 기준으로 쿼리를 조회하기 때문이다. 그렇기 때문에 연관된 엔티티 데이터가 필요한 경우, FetchType으로 지정한 시점에 조회를 별도로 호출하게 된다.
→ 즉, JPA가 JPQL을 분석해서 SQL을 생성할 때는 글로벌 Fetch 전략을 참고하지 않는다.
- Fetch 전략이 즉시 로딩인 경우
- JPQL에서 만든 SQL을 통해 데이터를 조회 (select t1_0.team_id, t1_0.team_name from team t1_0)
- 이후 JPA에서 Fetch 전략을 가지고 해당 데이터의 연관 관계인 하위 엔티티들을 추가 조회 → N+1 문제 발생
- Fetch 전략이 지연 로딩인 경우
- JPQL에서 만든 SQL을 통해 데이터를 조회
- JPA에서 Fetch 전략을 가지지만, 지연 로딩이기 때문에 추가 조회는 하지 않음
- 하지만, 하위 엔티티를 가지고 작업하게 되면 추가 조회가 발생 → N + 1 문제 발생
해결 방안
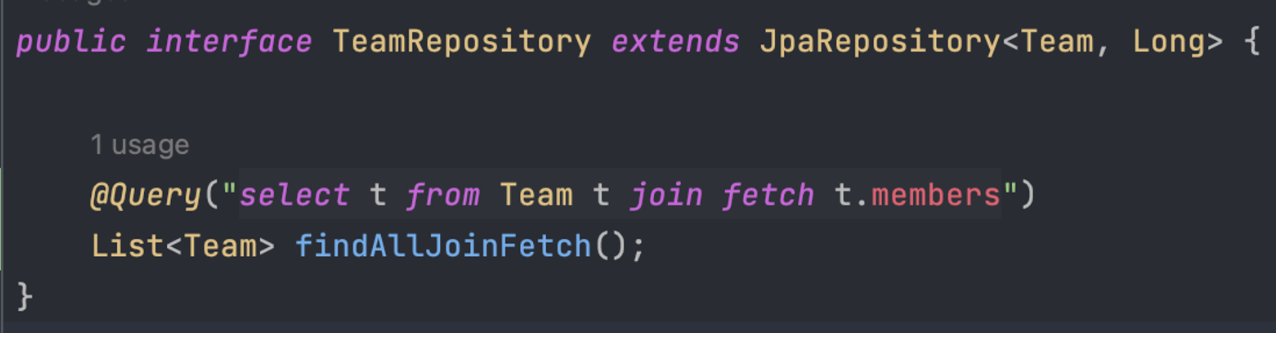
1. Fetch Join
-
JPQL에서 쿼리를 작성 한다.

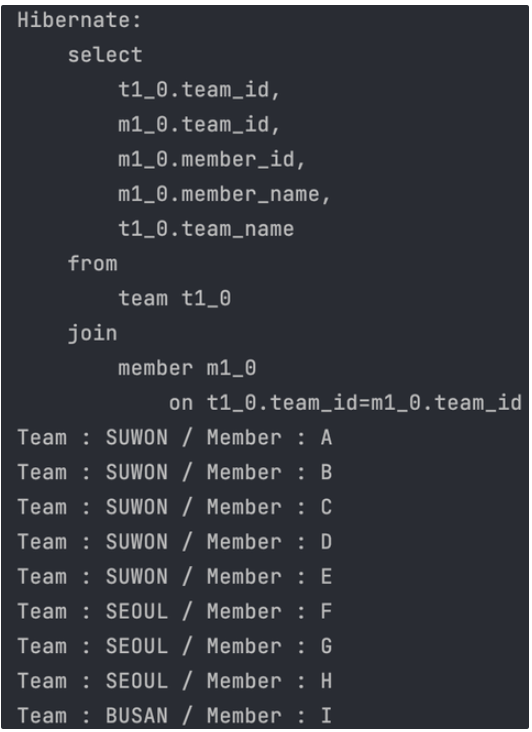
-
한 번의 Inner Join 쿼리문으로 조회가 가능하다.
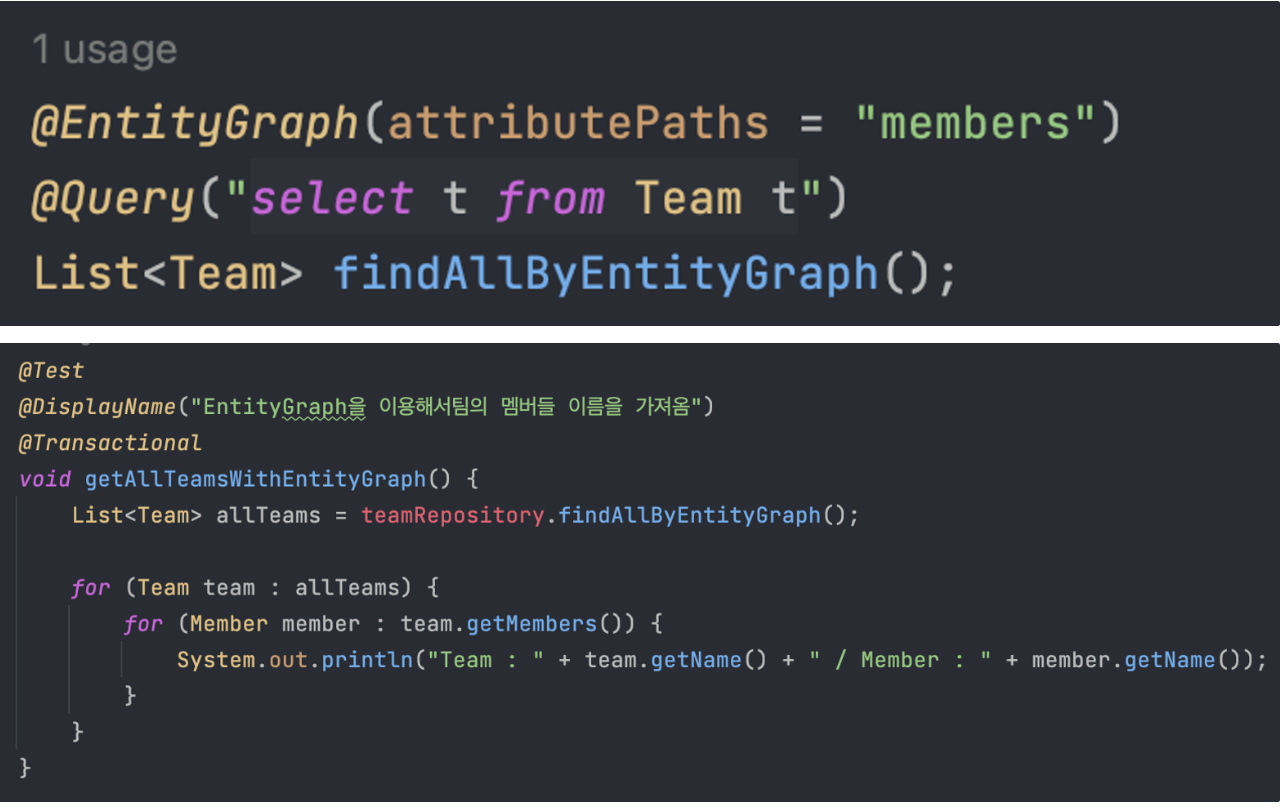
2. @EntityGraph
- @EntityGraph 의 attributePaths에 쿼리 수행시 바로 가져올 필드명을 지정하면 Lazy가 아닌 Eager 조회로 가져오게 된다.
![]()
- fetch join과는 다르게 left outer join을 이용해서 가져온다.
Fetch Join과 EntityGraph 주의할 점
Fetch Join과 EntityGraph는 JPQL을 사용하여 JOIN문을 호출한다는 공통점이 있다. 또한, 공통적으로 카테시안 곱(Cartesian Product)이 발생하여 Team의 수만큼 Member 중복 데이터가 존재할 수 있다. 그러므로 중복된 데이터가 컬렉션에 존재하지 않도록 주의해야 한다.
- 해결 방법
- 컬렉션을 Set을 사용하게 되면 중복을 허용하지 않는 자료구조이기 때문에 중복된 데이터를 제거할 수 있다.
- JPQL을 사용하기 때문에 distinct를 사용하여 중복된 데이터를 조회하지 않을 수 있다.
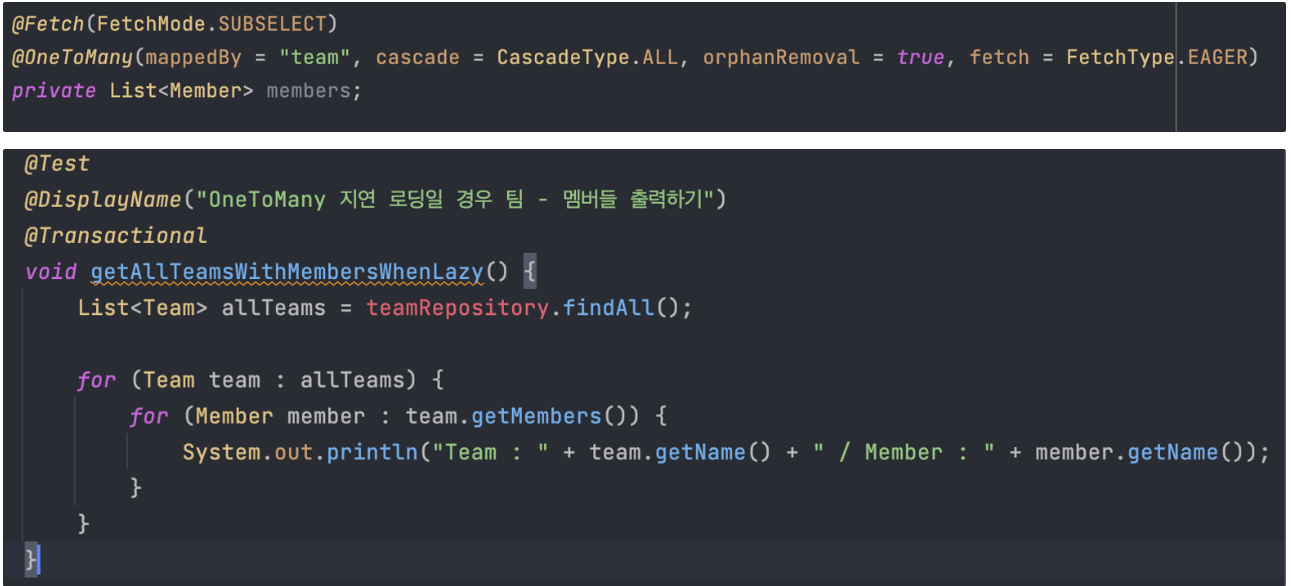
3. FetchMode.SUBSELECT
- 해당 엔티티를 조회하는 쿼리는 그대로 발생하고 연관관계의 데이터를 조회할 때 서브 쿼리로 함께 조회하는 방법이다.
![]()
- 먼저 Team을 조회하고, Team의 Id를 가지고 서브 쿼리로 함께 조회를 하는 방식이다.
- 즉시로딩으로 설정하면 조회시점에, 지연로딩으로 설정하면 지연로딩된 엔티티를 사용하는 시점에 위의 쿼리가 실행된다. 모두 지연로딩으로 설정하고 성능 최적화가 필요한 곳에는 JPQL 페치 조인을 사용하는 것이 추천되는 전략이다.
4. BatchSize
- 하이버네이트가 제공하는
org.hibernate.annotations.BatchSize어노테이션을 이용하면 연관된 엔티티를 조회할 때 지정된 size 만큼 SQL의 IN절을 사용해서 조회한다.
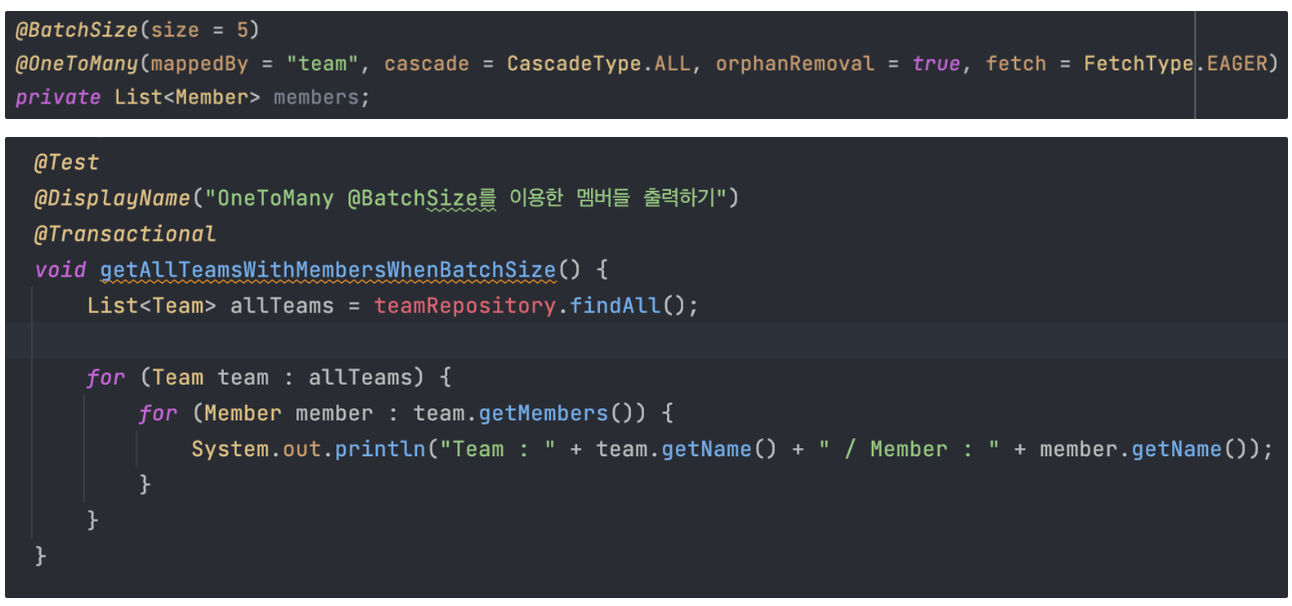
![]()
- 즉시로딩이므로 Team를 조회하는 시점에 Member를 같이 조회한다.
@BatchSize가 있으므로 Team의 row 갯수만큼 추가 SQL을 날리지 않고, 조회한 Team 의 id들을 모아서 SQL IN 절을 날린다. size는 IN절에 올수있는 최대 인자 개수를 말한다. 만약 Team의 개수가 10개라면 위의 IN절이 2번 실행될것이다.- 그리고 만약 지연 로딩이라면 지연 로딩된 엔티티 최초 사용시점에 5건을 미리 로딩해두고, 6번째 엔티티 사용 시점에 다음 SQL을 추가로 실행한다.
5. QueryBuilder를 사용해보자
- Mybatis, QueryDSL, JOOQ, JDBC Template 등으로 로직에 최적화된 쿼리를 구현할 수 있다.
정리
- Spring Data JPA에서 N+1 문제가 발생하는 이유 : JPQL 입장에서는 연관관계 데이터를 무시하고 해당 엔티티 기준으로 쿼리를 조회하기 때문이다. 그렇기 때문에 연관된 엔티티 데이터가 필요한 경우, FetchType으로 지정한 시점에 조회를 별도로 호출하게 된다.
- Fetch Join이나 EntityGraph를 사용한다면 Join문을 이용하여 하나의 쿼리로 해결할 수 있지만 중복 데이터 관리가 필요하다.
- SUBSELECT는 두번의 쿼리로 실행된다.
- BatchSize는 연관관계의 데이터 사이즈를 정확하게 알 수 있다면 최적화할 수 있는 size를 구할 수 있겠지만, 사실상 연관 관계 데이터의 최적화 데이터 사이즈를 알기는 쉽지 않다.
참고

방구석개발자