🍦 주제
- 무인 아이스크림 인식 계산대
- 계산하려는 상품들을 카메라에 인식하고 감지하여 상품의 결제 기능 제공
- 마트의 상품을 미리 확인할 수 있는 전체상품 리스트 제공
- 사전에 살 제품을 생각해 놓을 수 있는 장바구니 체크리스트 기능 제공
📚 주기능 개발 범위
- 아이스크림 상품 종류 구별
- AI Hub에서 제공하는 상품 데이터셋을 통해 YOLOv5 모델 학습
- 아이스크림 상품 검색 기능
- DB에서 상품 정보 반환
- Elasticsearch 활용
- 장바구니 체크리스트 기능
- 상태관리 라이브러리를 통해 장바구니 기능 구현
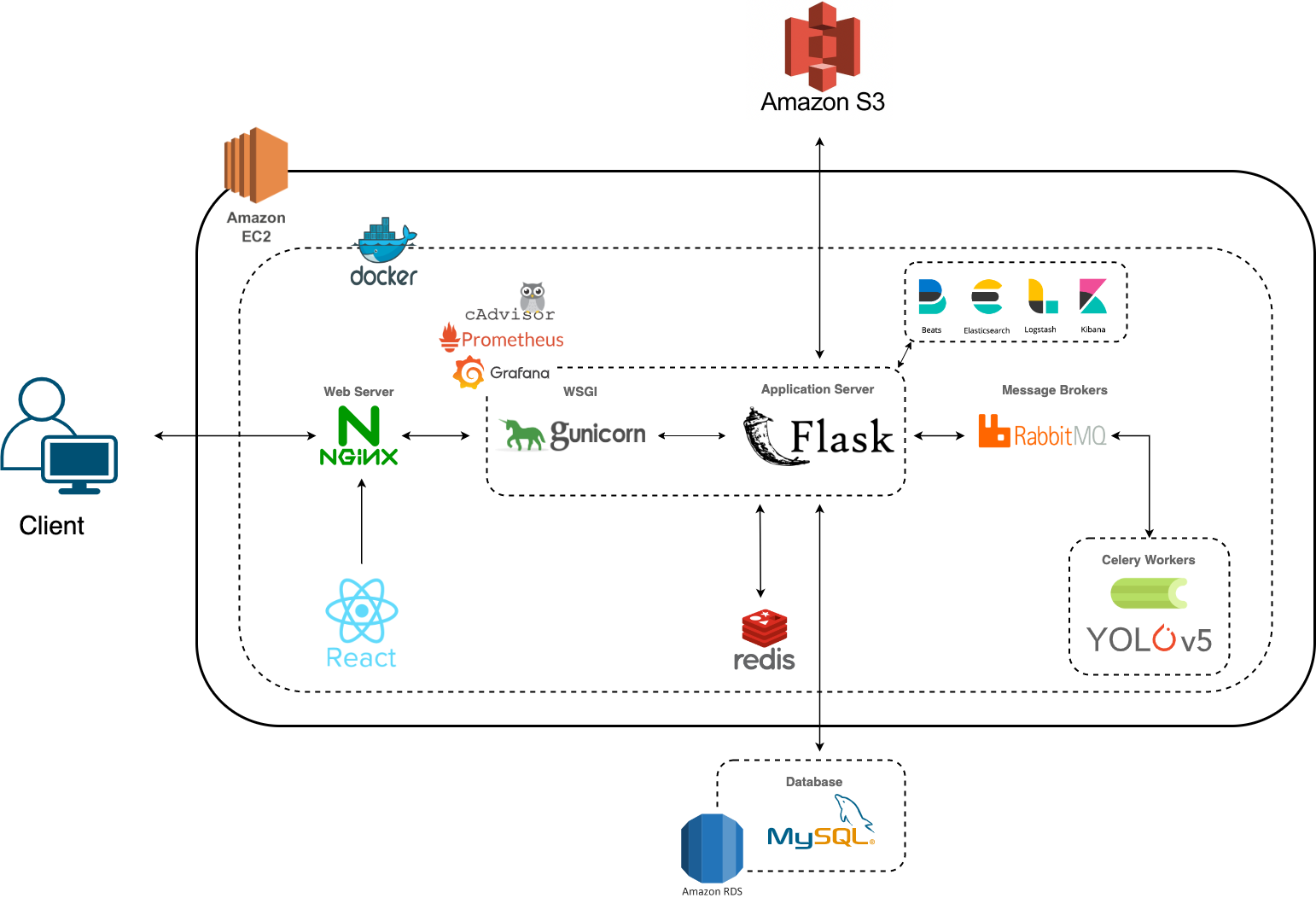
시스템 아키텍쳐
Nginx(Web server)
수많은 사용자 동시 커넥션을 유지하고, 정적 파일에 대한 요청을 처리하여 WAS의 부하를 줄이기 위해 Ngnix를 사용 (리버스프록시: 클라이언트 요청을 대신 받아 내부 서버로 전달해주는 것, 로드밸런싱을 위해서도 사용 가능)
- nginx에 리액트 코드가 담겨있다. -> 클라이언트가 정적인 요청을하면 nginx에 담겨 있는 리액트가 정적인 소스를 보내준다. -> 클라이언트가 동적인 요청을 하면 nginx에 담겨 있는 리액트가 was에게 동적으로 동작할 수 있게하는 정보를 준다 -> was가 처리한 데이터를 반환
React
React는 현재 프론트엔드 시장에서 가장 많이 쓰이는 라이브러리이고, 레퍼런스가 풍부하다. JS 기반이기 때문에 HTML과 JS를 알면 개발이 가능하여 프론트엔드를 처음 접하는 팀원이 있는 우리팀에 적합하다고 생각하여 선정하였다.
- 리액트에서 Nginx로는 단방향인 이유 : Nginx는 웹서버이다. nginx에 리액트를 올려서 사용자의 요청을 받아 단방향이다.
Gunicorn(WSGI)
파이썬 애플리케이션과 웹 서버 사이에 통신하기 위한 인터페이스로 사용, 웹 서버는 파이썬 프로그램을 호출할 수 있는 기능이 없어서 사용, 멀티스레드를 만들 수 있기 때문에 Request 요청이 많아지더라도 효율적으로 처리 할 수 있다.
Flask(파이썬 웹 어플리케이션)
웹 어플리케이션 개발을 위해 Flask를 사용. 초보자가 많아서 Django(장고)보단 가볍고 유연한(라이브러리, 도구등 쉽게 확장 가능) 프레임워크를 선택
- was(동적 리소스를 반환해주며 비지니스로직을 처리, 구지 따지면 (Gunicorn+Flask)이다.)
AWS RDS(Mysql(db))
우리 프로젝트에서 변경할 데이터가 없고 단순히 조회하기 때문에 구조가 많이 바뀌지 않을 거라 생각하여 RDBMS 중 관련 레퍼런스가 풍부한 MySQL을 선정하였다.
AWS RDS에서 Mysql데이터베이스를 생성하고 플라스크와 연결시켜 클라우드 데이터베이스로 개발할 때 같은 db를 사용할 수 있게끔한다.
디비를 지금 rds로 띄웠으니까 도커로 접속할 필요가 없다.
db를 도커에 띄우는 이유는 가상환경에서 mysql도커이미지를 받아서 db컨테이너를 띄워서 db로 쓸려는건데 우리는 cloud서비스인 rds를 띄워서 db로 사용하는것이기 때문에 도커에 띄워진 db(로컬 db)를 사용할 필요가 없는거지 그래서 rds를 도커와 연관지을 필요가 없는것이다.
RabbitMQ
Flask서버와 AI서버 간의 메세지를 주고받기 위해 사용. 비동기식으로 처리를 할 수 있다.
(우리 프로젝트에서는 상품이미지를 ai서버로 보네서(Flask→RabbitMq→Celery→pytorch(Yolov5)) ai가 상품이미지를 식별하고 라벨링 후 class_num를 다시 Celey→ RabbitMq→ Flask→MySQl(db)순으로 진행됨, 이때 넓게보면 ipc통신을 하게됨), 실시간으로 처리되지 않아도 서비스에 크게 문제 없는 작업이기에 MQ를 사용
Celery
Message Broker에서 메시지를 가져와 작업을 수행하는 Worker의 역할을 담당. 파이썬은 기본적으로 싱글 스레드이기에 동기를 비동기로 작업을 처리하게 넘기고 바로 응답을 하기 위해 사용(이미지가 라벨링된 정보(class_num)를 다시 RabbitMq에 보넴)
pytorch
ai(Yolov5)를 사용하기 위해 쓰임
AWS s3
이미지를 db에 저장하는것 좋지 않음, 무한대의 객체(데이터)를 저장할 수 있으며, 확장/축소에 신경 쓰지 않아도 된다. (우린 상품 리스트에 제공할 이미지를 담는다. 아이스크림 매장으로 상품의 종류가 5~10개 정도로 하지만 대형마트의 경우 상품이 굉장히 많기에 상품의 이미지를 s3에 저장하면 좋다.)
또한 클라이언트가 이미지를 보네면 s3에서 이미지의 url을 flask로 보네주고 flask에서 그 url을 메시지큐(RabbitMq), celery를 거쳐 ai가 url을 가지고 사진을 해석(식별)해주고 라벨링을 해준다.
Amazon EC2
서비스를 실제 배포하기 위해 사용. Amazon EC2를 사용하여 원하는 수의 가상 서버를 구축하고 보안 및 네트워킹을 구성하며 스토리지를 관리할 수 있습니다. AWS EC2에 Docker 설치 및 배포 가능
Docker
Docker를 사용하면 환경에 구애받지 않고 애플리케이션을 신속하게 배포 및 확장할 수 있으며 코드가 문제없이 실행될 것임을 확신할 수 있습니다.
Redis
나중에 요청할 결과를 미리 저장해둔 후 빠르게 서비스 해주기 위해 Cache로서 사용한다. 즉, 미리 결과를 저장하고 나중에 요청이 오면 그 요청에 대해서 DB 또는 API를 참조하지 않고 Cache를 접근하여 요청을 더 빠르게 처리하게 됩니다.
Swagger
스웨거는 Web API 문서화를 위한 도구이다. 말 그대로 API들이 가지는 명세(Spec)을 관리하기 위한 프로젝트이다. Web API를 수동으로 문서화 하는 것은 굉장히 힘든일인데, Web API의 스펙이 변경되었을 때 문서 역시 변경되어야 하는데 이를 유지하는 것이 쉽지 않다.
Swagger를 사용하면 Web API가 수정되더라도 문서가 자동으로 갱신 되기 때문에 편리하다.
-
Web API를 이용하는 개발자가 Web API가 만들어질 때까지 기다린다면 작업이 상당히 느려질 수 있다. Web API를 만드는 개발자와 Web API를 사용하는 사람 간에 미리 명세를 정의하고 공유할 수 있다면 개발이 상당히 편리해질 것이다. 이러한 것들을 편리하게 해주는 도구 중에 하나가 "스웨거"이다.
-
스웨거 허브 사이트를 이용하면 Web API를 만들지 않더라도 Web API를 명세화 할 수 있다. 또한 Web API를 명세화 하는것 뿐 아니라 간단히 테스트도 할 수 있다는 장점이 있다.
ElasticSearch
오픈 소스 검색엔진
- 전문검색
내용 전체를 색인해서 특정 단어가 포함된 문서를 검색할 수 있다. 기능별, 언어별 플러그인을 적용할 수 있다.- 통계 분석
비정형 로그 데이터를 수집하여 통계 분석에 활용할 수 있다. Kibana를 연결하면 실시간으로 로그를 분석하고 시각화할 수 있다.- Schemaless
정형화되지 않은 문서도 자동으로 색인하고 검색할 수 있다.- RESTful API
HTTP기반의 RESTful를 활용하고 요청/응답에 JSON을 사용해 개발 언어, 운영체제, 시스템에 관계없이 다양한 플랫폼에서 활용이 가능하다.- Multi-tenancy
서로 상이한 인덱스일지라도 검색할 필드명만 같으면 여러 인덱스를 한번에 조회할 수 있다.- Document-Oriented
여러 계층 구조의 문서로 저장이 가능하며, 계층 구조로된 문서도 한번의 쿼리로 쉽게 조회할 수 있다.- 역색인(Inverted Index)
일반적인 색인의 목적은 ‘문서의 위치’에 대한 index를 만들어서 빠르게 그 문서에 접근하고자 하는 것인데, 역색인은 반대로 ‘문서 내의 문자와 같은 내용물’의 맵핑 정보를 색인해놓는 것이다.
역색인은 검색엔진과 같은 문서의 내용의 검색이 필요한 형태에서 전문 검색의 형태로 주로 쓰인다.- 확장성
분산 구성이 가능하다. 분산 환경에서 데이터는 shard라는 단위로 나뉜다.- 단점 : 완전 실시간은 아니다, Transaction Rollback을 지원하지 않는다, 데이터의 업데이트를 제공하지 않는다.
ELK stack
서버가 각각 나뉘어 있으면 로그를 하나하나 확인하기 어려움,
로그를 한 곳으로 집중시키고 분석하고 적당한 쿼리를 만들어 원하는 데이터를 도출 해낼 수 있는 로그 관리 솔루션 활용으로서 ELK stack 사용
Grafana and Prometheus
프로메테우스는 대상 시스템으로부터 각종 모니터링 지표를 수집하여 저장하고 검색할 수 있는 시스템이다. 그라파나는 프로메테우스를 비롯한 여러 데이터들을 시각화해주는 모니터링 툴이다.
