리스트 : 자료를 정리하는 방법 중의 하나
ex)
- 오늘 해야 할 일: (청소, 쇼핑, 영화관람)
- 버킷 리스트 : (세계여행, 영어 마스터, 마라톤..)
- 요일들 : (일, 월, 화, 수 ..)
배열로 구현된 리스트
장점: 구현이 간단하고 속도가 빠르다.
단점 : 리스트의 크기가 고정된다는 것. 동적으로 크기를 늘리거나 줄이는 것이 힘들다. 삽입 삭제가 힘듬
연결 리스트
장점: 크기가 제한되지 않고(동적 생성), 삽입, 삭제가 쉬움 트리, 그래프, 스택, 큐 같은 자료구조 등을 구현하는데 사용됨.
연결 리스트의 구조
연결리스트는 노드들의 집합. 각 노드들은 포인터로 연결이됨.
즉 노드들은 메모리의 어떤 위치에나 있을 수 있으며, 다른 노드로 가기 위해서는 현재 노드가 가지고 있는 포인터를 이용하면 된다.
노드 = 데이터 필드 + 링크 필드
- 데이터 필드 : 사용자가 저장하고 싶은 데이터( 정수, 구조체..)
- 링크 필드 : 다른 노드를 가리키는 포인터가 저장
- 헤드 포인터: 첫 번째 노드를 가리키고 있는 변수
- 헤드 포인터를 알아야 전체 노드에 접근 가능
- 마지막 노드의 링크 필드는 NULL
- 각 노드들은 필요할 때 마다 malloc()을 이용하여 동적으로 생성
연결 리스트의 종류
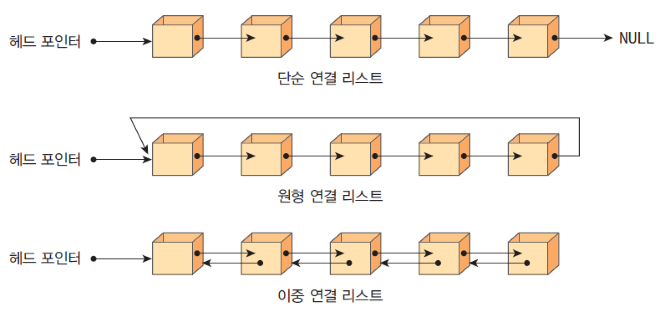
단순 연결 리스트
- 노드의 정의
typedef int element; // 노드의 들어갈 데이터 타입을 정의
typedef struct ListNode { // 노드 타입을 구조체로 정의
element data;
struct Listnode * link; // 자기 참조 구조체
}ListNode;
data : element 타입의 데이터를 저장
link : 다음 노드의 주소 저장자기참조구조체는 말 그래도 자기 자신을 참조하는 포인터를 포함하는 구조체이다.
-
공백 리스트의 생성
ListNode *head = NULL;
단순연결 리스트는 헤드 포인터만 잇으면 모든 노드를 찾을 수 있다. 현재는 노드가 없으므로 head의 값은 NULL이 된다.
-
노드의 생성
head = (ListNode *)malloc(sizeof(ListNode));
일반적으로는 연결리스트에서는 필요할 대마다 동적 메모리 할당을 이용하여 노드를 동적으로 생성한다. 이 동적 메모리가 하나의 노드가 된다.
head->data = 10;
head->link = NULL; 이런식으로 노드를 채워나가면 된다.
-
노드의 연결
ListNode *p; p = (ListNode *)malloc(sizeof(ListNode)); p->data = 20; p->link = NULL;
동일한 방식으로 노드를 하나 더 생성하고 두 노드를 연결해보자.
head->link = p;간단하다.
단순 연결 리스트의 연산 구현
insert_first : 리스트의 시작 부분에 항목을 삽입하는 함수
insert() : 리스트의 중간 부분에 항목을 삽입하는 함수
delete_first() : 리스트의 첫 번째 항목을 삭제하는 함수
delete() : 리스트의 중간 항목을 삭제한느 함수
print_list() : 리스트를 방문하여 모든 항목을 출력하는 함수
다음 함수들을 밑에서 더 자세히 알아보자.
#include <stdio.h>
#include <stdlib.h>
typedef int element;
typedef struct ListNode { // 노드 타입
element data;
struct ListNode *link;
} ListNode;
// 오류 처리 함수
void error(char *message)
{
fprintf(stderr, "%s\n", message);
exit(1);
}
ListNode * insert_first(ListNode *head, int value)
{
ListNode *p = (ListNode *)malloc(sizeof(ListNode)); //노드 동적생성
p->data = value; //노드의 데이터값 넣기
p->link = head; //다음 노드를 가르킴
head = p; //힙 메모리에서 동적 할당된 주소를 가진 p의 값을 head로 변경
return head; //변경된 head포인터 반환
}
// 노드 pre 뒤에 새로운 노드 삽입
ListNode *insert(ListNode *head, ListNode *pre, element value)
{
ListNode *p = (ListNode *)malloc(sizeof(ListNode)); 1
p->data = value; 2
p->link = pre->link; 3
pre->link = p; 4
return head; 5
}
//10->20->30->40이 연결되있고 value = 50을 20과 40 사이에 넣기로 가정해보자.
//1. 먼저 노드를 생성
//2. 노드에 값(50)을 넣음
//3. 생성된 노드는 40노드를 가르킴
//4. 20노드는 생성된 노드를 가르킴
//5. 변경된 연결 리스트를 반환
ListNode* delete_first(ListNode *head)
{
ListNode * removed;
if( head == NULL) return NULL; // 연결된 노드가 없으면 NULL 반환
removed = head; // 첫 번째 노드의 주소를 준다.
head = removed->link; // 두 번째 노드의 주소를 받는다.
free(removed); // 첫 번째 노드를 반환.
return head; // 변경된 연결 리스트를 반환.
}
// pre가 가리키는 노드의 다음 노드를 삭제한다.
ListNode* delete(ListNode *head, ListNode *pre)
{
ListNode * removed;
removed = pre->link; //pre가 가리키는 노드의 다음 노드 주소를 준다.
pre->link = removed->link; // 제거될 노드의 다음 주소를 준다.
free(removed); // 동적 반환
return head; //변경된 연결 리스트 반환
}
void print_list(ListNode * head)
{
for(ListNode *p = head; p != NULL; p->link) // 각 노드들 방문
printf("%d->", p->data); // 노드의 data출력
printf("NULL\n");
}
int main(void)
{
ListNode *head = NULL;
for(int i = 0; i < 5; i++){
head = insert_first(head, i);
print_list(head);
}
for(int i = 0; i < 5; i++){
head = delete_first(head, i);
print_list(head);
}
return 0;
}!!!!!!!!!!!!여기서 잠깐!!!!!!!!!!!!!!
매인함수에 있는 head와 insert_first()함수의 매개변수 head는 서로 다른 head이다. 매개변수 head는 메인함수에 있는 head를 가르키는 또 다른 포인터 변수!!! call by address가 아니다!!
즉 함수안에서 head를 바꿔도 매인함수에서의 head는 안바뀐다. 함수에서 바뀐 head를 return 하여 매인함수의 head가 받는것이다.
//////////////////////////////////////////////////////////
책에 있는 함수 이외에 delete_last()와 insert_last를 직접 만들어 보았다.
ListNode* delete_last(ListNode* head) {
ListNode* removed = head;
if (head == NULL || head->link == NULL) return NULL;
while (removed->link->link != NULL)
{
removed = removed->link;
}
free(removed->link->link);
removed->link = NULL;
return head;
}
ListNode* insert_last(ListNode* head, element value) {
ListNode* r;
ListNode* p = (ListNode*)malloc(sizeof(ListNode)); //동적할당
p->data = value; // 값을 data에 넣는다
p->link = NULL; // p 링크에 NULL을 넣는다
r = head; // r이 head값을 얻는다
if (head == NULL) { // head에 연결된 노드가 없으면 첫 노드 연결 후 반환
head = p; return head;
}
while (r->link != NULL) // r link가 NULL이 아닐때까지 반복
r = r->link; // 다음 노드로 이동
r->link = p; // r link는 p값을 얻는다
return head; // inert함수의 head리턴
}
그 외
특정한 값을 탐색하는 함수
ListNode* search_list(ListNode *head, element x)
{
ListNode *p = head;
while (p != NULL) {
if (p->data == x) return p;
p = p->link;
}
return NULL; // 탐색 실패
}두 개의 리스트를 하나로 합치는 함수
ListNode* concat_list(ListNode *head1, ListNode *head2)
{
if (head1 == NULL) return head2;
else if (head2 == NULL) return head2;
else {
ListNode *p;
p = head1;
while (p->link != NULL)
p = p->link;
p->link = head2;
return head1;
}
}
리스트를 역순으로 만드는 함수
ListNode* reverse(ListNode *head)
{
// 순회 포인터로 p, q, r을 사용
ListNode *p, *q, *r;
p = head; // p는 역순으로 만들 리스트
q = NULL; // q는 역순으로 만들 노드
while (p != NULL) {
r = q; // r은 역순으로 된 리스트.
// r은 q, q는 p를 차례로 따라간다.
q = p;
p = p->link;
q->link = r; // q의 링크 방향을 바꾼다.
}
return q;
}첫 헤드노드의 다음 노드부터 데이터가 있고 데이터들을 정렬하여 노드 안의 데이터만 바꾸자는 생각
연결리스트 정렬

교수님 강의자료 보다 정리가 잘 되어있네요 감사합니다~