메트릭이란?
수집하는 시계열 데이터를 말한다.
- 로그와 달리 메트릭은 주기적으로 발생한다, 통상 로그는 무언가 발생했을 때 로그파일에 기록되는 반면, 메트릭은 주기적으로 발생하는 또는 수집하는 이벤트라 보면 될 것 같다.
- 예를 들면 시스템 리소스 모니터링에 정기적으로 수집되는 데이터들(CPU사용량, 시간당 데이터 처리량, 분당 네트워크 속도 등등) 등을 생각하면 될 것 같다.
- 프로메테우스의 메트릭은 "메트릭명{필드1=값, 필드2=값} 샘플링데이터" 와 같이 수집된다.
Prometheus

프로메테우스는 대상 시스템으로부터 각종 모니터링 지표를 수집하여 저장하고 검색할 수 있는 시스템이다.
- 그라파나를 통한 시각화 지원
- 많은 시스템을 모니터링할 수 있는 다양한 플러그인을 가지고 있다.
- 쿠버네티스의 메인 모니터링 시스템으로 많이 사용된다.
- 프로메테우스가 주기적으로 exporter(모니터링 대상 시스템)로부터 pulling 방식으로 메트릭을 읽어서 수집한다.
Grafana

그라파나는 프로메테우스를 비롯한 여러 데이터들을 시각화해주는 모니터링 툴이다.
- 키바나는 주로 로그 메세지 분석에 사용된다.
- 그라파나는 시스템 관점(CPU, 메모리, 디스크)의 메트릭 지표를 시각화하는데 특화되어 있다.
- 메트릭
- CPU와 메모리 사용량을 나타내는 System Metric
- HTTP 상태 코드 같은 서비스의 상태를 나타내는 Service Metric
- 키바나는 elasticsearch에 묶여 있지만, 그라파나는 다양한 데이터베이스를 선택할 수 있다.
- 그라파나는 알람기능을 무료로 사용할 수 있다.
Node Exporter
Prometheus Node Exporter는 하드웨어의 상태와 커널 관련 메트릭을 수집하는 메트릭 수집기입니다. Prometheus는 Node Exporter의 metrics HTTP endpoint에 접근하여 해당 메트릭을 수집할 수 있습니다. Node Exporter로 부터 수집한 메트릭을 Prometheus내의 TSDB에 저장하여 PromQL로 메트릭을 쿼리해 서버 상태를 모니터링할 수 있습니다.
- Node Exporter는 해당 노드, 즉 호스트 자체를 모니터링하기 위한 툴이다. CAdvisor와 다른 점은 도커 엔진이 아닌 호스트 자체에 대한 데이터를 주로 제공한다는 점이다.
CAdvisors
도커 호스트에 컨테이너로서 실행되는 모니터링 툴로, 도커 엔진 및 컨테이너, 이미지 등에 대한 데이터를 수집해준다. /metrics endpoint로 데이터를 수집할 수 있다.
alertmanager
alert.yml
groups:
- name: example
rules:
# Alert for any instance that is unreachable for >2 minutes.
- alert: service_down
expr: up == 0
for: 2m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 2 minutes."
- alert: high_load
expr: node_load1 > 0.5
for: 2m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} under high load"
description: "{{ $labels.instance }} of job {{ $labels.job }} is under high load."인스턴스 중 하나라도 2분동안 down된 경우, 0.5 이상의 CPU 부하에 대한 알람이 오도록 다음과 같이 작성했다.
이 페이지를 참고해서 따라하면 됨
prometheus.yml
- prometheus.yml 파일에 메트릭을 수집할 컨테이너들을 다음과 같이 작성한다.
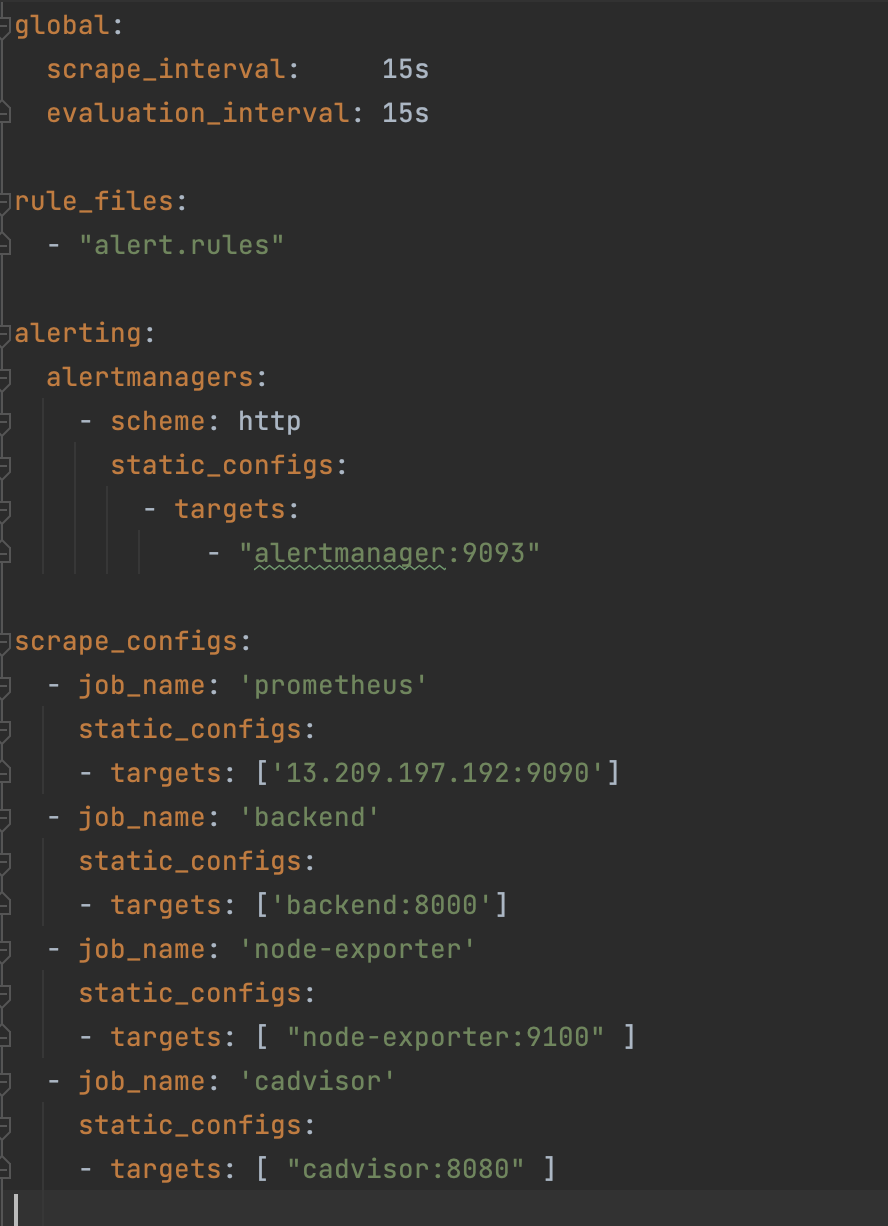
—> prometheus.yml 작성방법


prometheus 도커 컴포즈 파일
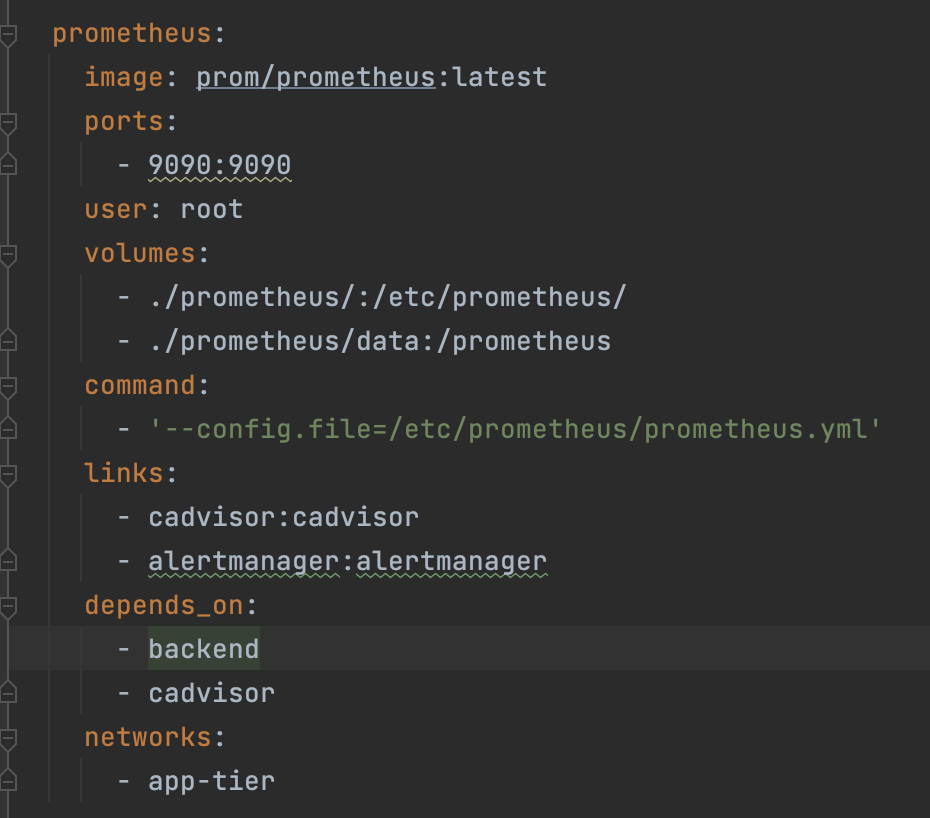
alertmanager 도커 컴포즈 파일
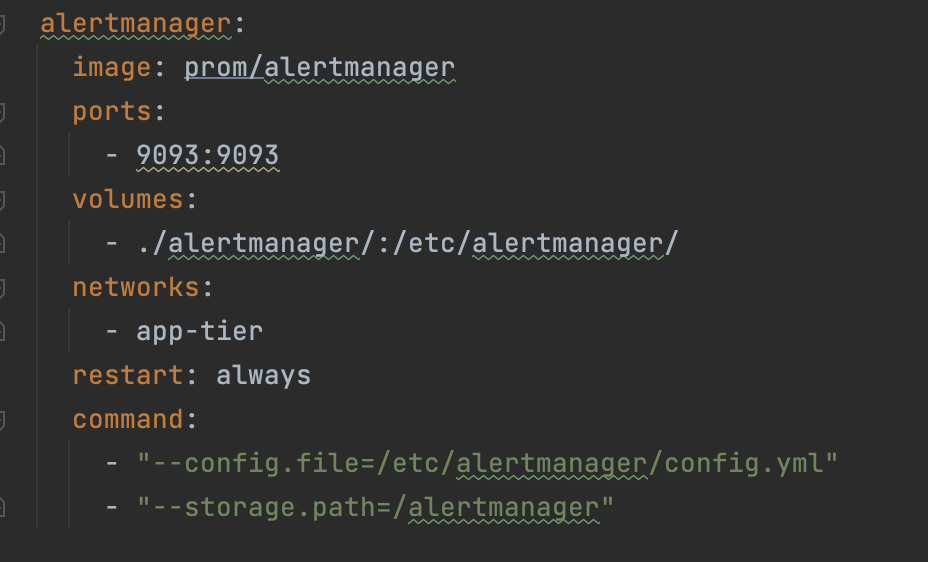
alertmanager디렉토리 config.yml파일
global:
slack_api_url:
route:
receiver: 'slack-notifications'
repeat_interval: 2m
receivers:
- name: 'slack-notifications'
slack_configs:
- channel: '#_monitoring'
send_resolved: true
title: "{{ range .Alerts }}{{ .Annotations.summary }}\n{{ end }}"
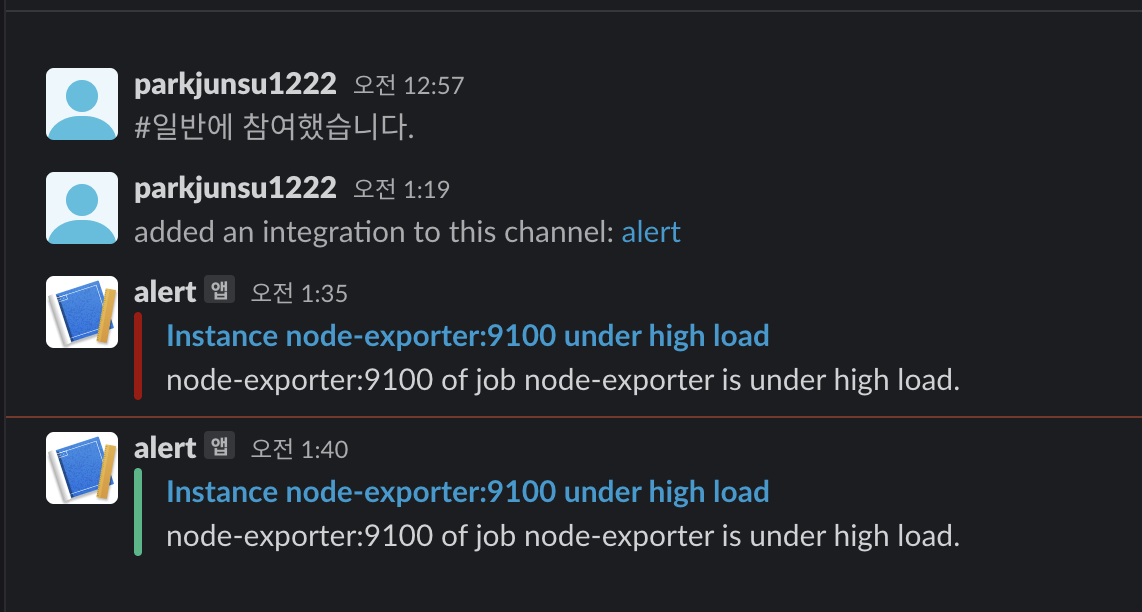
text: "{{ range .Alerts }}{{ .Annotations.description }}\n{{ end }}"Slack알람
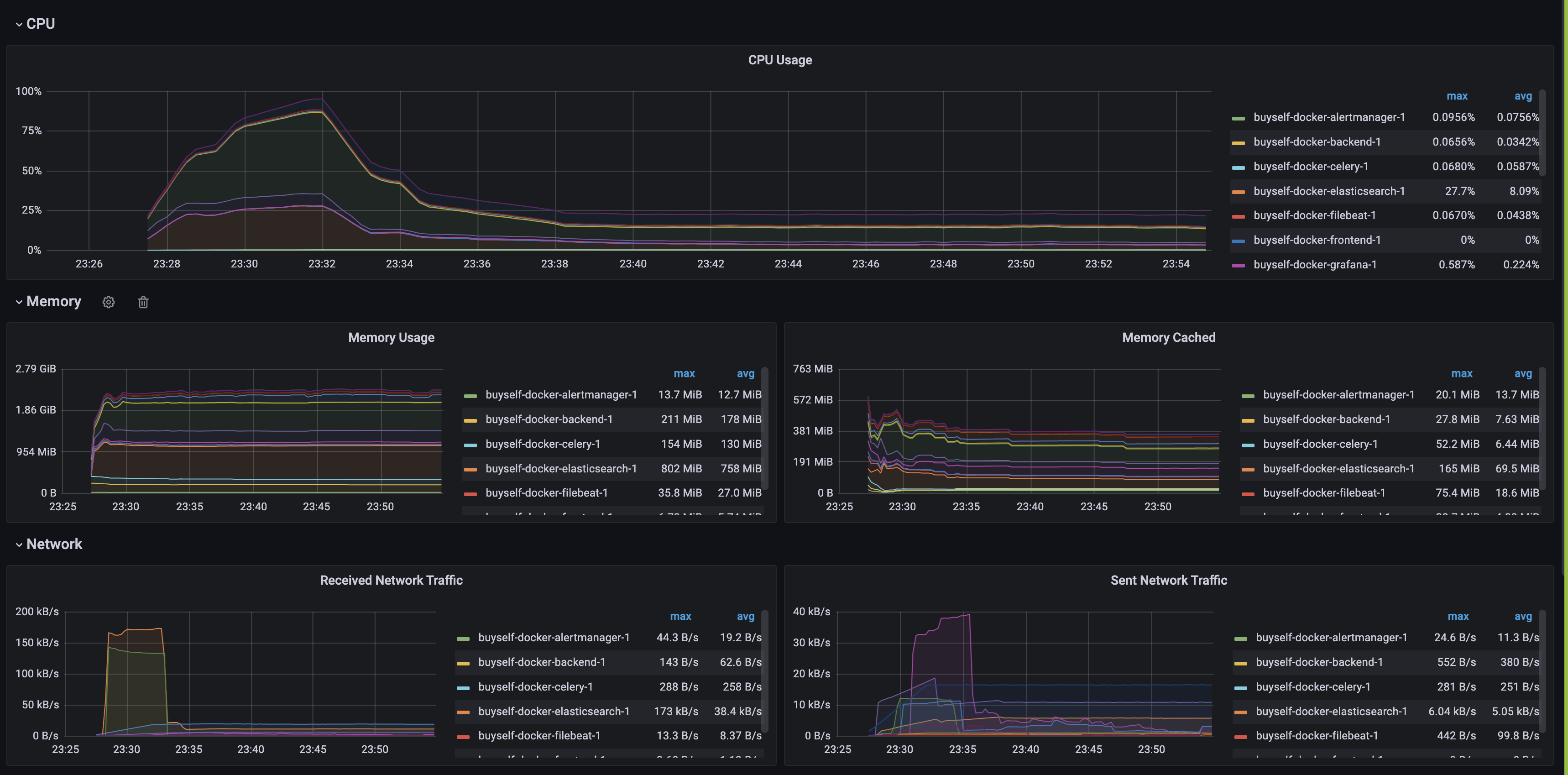
Cadviser
- 도커 컨테이너의 cpu, memory사용량, 캐시, network 트래픽을 모니터링
node-exporter
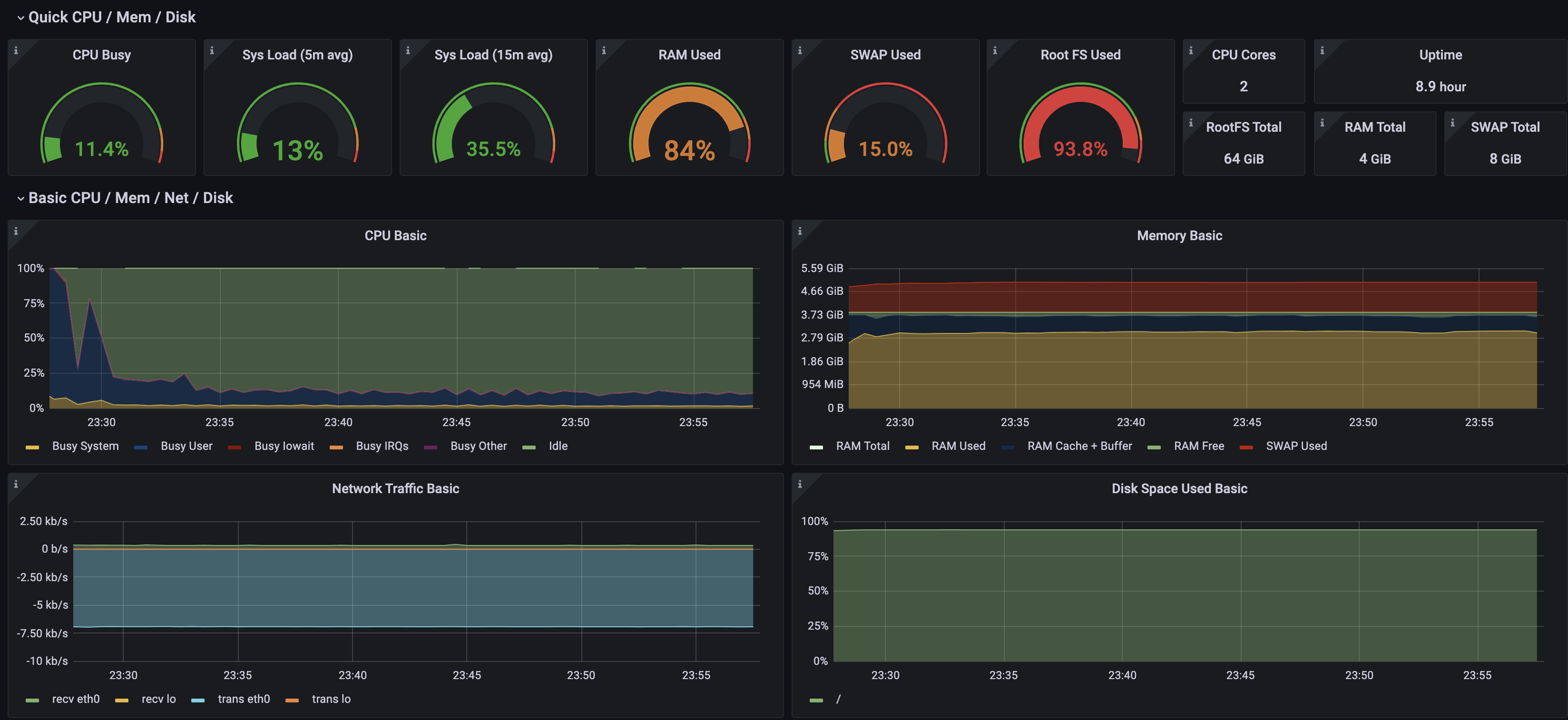
- ec2 서버의 (cpu, memory , network 트래픽) 상태, 디스크 사용량을 모니터링
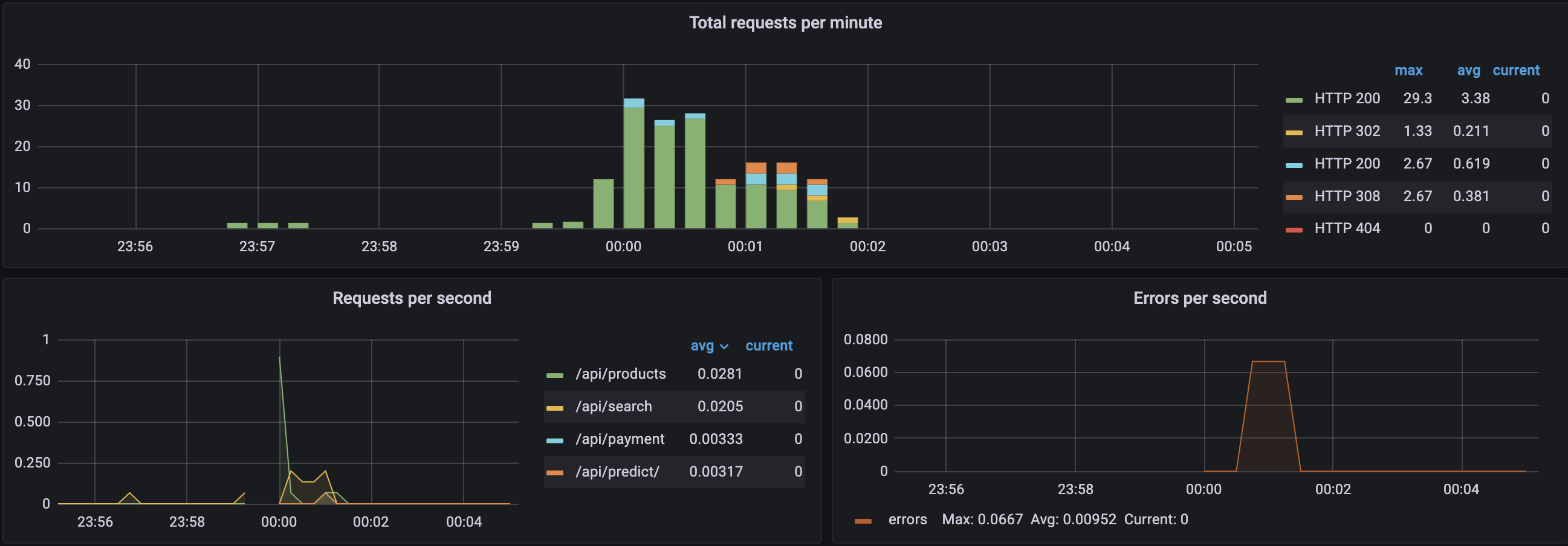
flask
- 사용자의 HTTP 요청 종류와 횟수, 에러 상태 모니터링
add your datasource에서 연결 후 '+' 버튼의 import에 대쉬보드 번호를 쓰면 된다.
grafana lab사이트에서 괜찮은 대쉬보드를 찾으면 된다.
참고 : 프로메테우스&그라파나//Prometheus란?//함봐바//node exporter 예시//프&그예제
