
데이터 조작어이다. 실제 데이터 베이스의 값을 조회, 수정, 생성, 삭제하는 언어로 사용 빈도가 가장 많고 집중적으로 공부할 부분이다
1. SELECT
1) 기본 구문
SELECT 컬럼명 FROM 테이블 WHERE 검색조건;
테이블에서 조건 설정한 특정 컬럼의 값을 조회하는 구문이다
SELECT * FROM 테이블;
모든 컬럼의 값을 조회한다.
-
SYSDATE : 시스템 상의 현재 시간을 나타내는 상수
-
DATE 날짜형 데이터 역시 조회가 가능하다.
-
별칭 지정 : 컬럼명 AS 별칭 : 별칭 띄어쓰기 X, 특수문자X, 문자만 O (AS는 생략 가능하다)
-
리터럴 : 임의로 지정한 값을 기존 테이블에 존재하는 것처럼 사용하는 것
SELECT EMP_NAME, SALARY, '원입니다.' FROM EMPLOYEE ;
이와 같이 '' 홑따옴표를 이용해서 사용한다.
"" 쌍따옴표 안에는 특수문자, 대소문자, 기호 등을 같이 나타낼 수 있다.
-
DISTINCT : 조회 시 컬럼에 포함된 중복 값을 한 번만 표기
주의사항 1) DISTINCT 구문의 SELECT 마다 딱 한 번씩만 작성 가능
주의사항 2) DISTINCT 구문은 SELECT 제일 앞에 작성되어야 한다.
2) 연산자
- 연결 연산자
‘||’를 사용하여 여러 컬럼을 하나의 컬럼인 것처럼 연결하거나 컬럼과 리터럴을 연결함
-
논리 연산자
NOT, AND, OR과 같은 제한 조건으로 하나의 결과값을 만들어줌 -
비교연산자
=, >, <, >=, <=, BETWEEN ~ AND ~, LIKE, NOT LIKE, IS NULL, IS NOT NULL, IN 과 같은 비교 처리
**LIKE의 패턴**
'%' : 포함
'___' : 글자 수
'%' 예시
'A%' : A로 시작하는 문자열
'%A' : A로 끝나는 문자열
'%A%' : A가 포함하는 문자열
'____' 예시
'A_' : A로 시작하는 두 글자 문자열
'_______A' : A로 끝나는 네 글자 문자열
'____A____' : A가 세 번째 나오는 다섯 글자 문자열
'________________' : 다섯 글자 문자열3) GROUP BY / HAVING
SELECT문 해석 순서
5 : SELECT 컬렴명 AS 별칭, 계산식, 함수식
1 : FROM 참조할 테이블명
2 : WHERE 컬럼명 | 함수식 비교연산자 비교값
3 : GROUP BY 그룹을 묶을 컬럼명
4 : HAVING 그룹함수식 비교연산자 비교값
6 : ORDER BY 컬럼명 | 별칭 | 컬럼순번 정렬방식 [ NULLS FIRST / LAST ]
GROUP BY절
같은 값들이 여러개 기록된 컬럼을 가지고 같은 값들을 하나의 그룹으로 묶음
여러 개의 값을 묶어서 하나로 처리할 목적으로 사용함
그룹으로 묶은 값에 대해서 SELECT 절에서 그룹 함수를 사용함.
EX) EMPLOYEE 테이블에서 부서코드가 D5, D6인 부서의 평균 급여, 인원 수 조회
SELECT DEPT_CODE , ROUND(AVG(SALARY)), COUNT(*)
FROM EMPLOYEE
WHERE DEPT_CODE IN ('D5', 'D6')
GROUP BY (DEPT_CODE); -- DEPT_CODE로 묶어서 그룹으로 보여줄 수 있다.
4) 서브쿼리
하나의 SQL문 안에 포함된 또다른 SQL(SELECT)문
메인쿼리(기존쿼리)를 위해 보조 역할을 하는 쿼리문
SELECT, FROM, WHERE, HAVGIN 절에서 사용가능하다.
단일행 (단일열) 서브쿼리
서브쿼리의 조회 결과 값의 개수가 1개일 때
-> 조회 결과가 1행1열
다중행 (단일열) 서브쿼리
서브쿼리의 조회 결과 값의 개수가 여러개일 때
-> 행은 여러개 컬럼은 1개
다중열 서브쿼리
서브쿼리의 SELECT 절에 자열된 항목수가 여러개 일 때
-> 컬럼이 여러개, 행은 1개
다중행 다중열 서브쿼리
조회 결과 행 수와 열 수가 여러개일 때
-> 행도 여러개 컬럼도 여러개
상관 서브쿼리
서브쿼리가 만든 결과 값을 메인 쿼리가 비교 연산할 때
메인 쿼리 테이블의 값이 변경되면 서브쿼리의 결과값도 바뀌는 서브쿼리
스칼라 서브쿼리
상관 쿼리이면서 결과 값이 하나인 서브쿼리
2. INSERT
테이블에 새로운 행을 추가하는 구문
INSERT INTO 테이블명 VALUES (데이터1, 데이터2, 데이터3 ..);
-- 모든 컬럼에 값을 넣을 경우
INSERT INTO 테이블명(컬럼1, 컬럼2) VALUES (데이터1, 데이터2);
--내가 선택한 컬럼에만 값을 넣을 경우데이터의 자료형과 순서를 맞춰줘야 한다!!
3. UPDATE
데이블의 값을 수정하는 구문
UPDATE 테이블명 SET 컬럼명 = 바꿀값
[WHERE 컬럼명 비교연산자 비교값];
--> WHERE 조건 중요하다.
-- UPDATE할 컬럼과 조건을 WHERE 절에서 정하기 때문에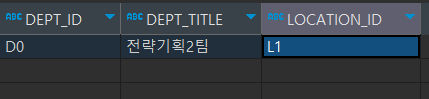
이와 같은 데이터를 수정할 때,
UPDATE DEPARTMENT2
SET DEPT_TITLE = '개발팀'
WHERE DEPT_ID = 'D0';
이처럼 수정이 가능하다
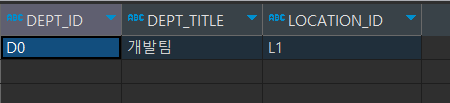
개발팀으로 변경되었다!
4. DELETE
테이블의 행을 삭제하는 구문
DELETE FROM 테이블명 WHERE 조건설정;