
SQL
SELECT SQL 각 구문별 실행순서
FROM,JOINON,WHERE- 2차 테이블 완성
GROUP BY- 그룹함수
- 3차 테이블 완성(그룹작업이 있을 경우에만)
HAVING- 4차 테이블 완성(HAVING작업이 있을 경우에만)
ORDER BYLIMIT- 고객(MySQL 클라이언트, 대표적으로 Sequel Pro, SQLYog, JDBC Driver 등)에게 전달
명령어 정의
AS (alias)
- 열 또는 테이블에 대해 별칭을 지정하는 SQL 질의어 (자바 변수명과 비슷)
- 테이블에 대한 별칭을 지정하면 SQL 문에서 테이블 이름 대신 해당 별칭을 사용할 수 있다.
# table1 -> t1 / table2 -> t2 SELECT column1, column2 FROM table1 AS t1 INNER JOIN table2 AS t2 ON t1.column1 = t2.column1;
ORDER BY
- 데이터베이스에서 검색한 결과를 정렬하는 데 사용
(오름차순ASC/ 내림차순DESC)# my_table 테이블에서 검색한 결과를 column_name 열의 값을 기준으로 내림차순으로 정렬 SELECT * FROM my_table ORDER BY column_name DESC;
JOIN
- 두 개 이상의 테이블에서 데이터를 결합하는 데 사용
INNER JOIN: 두 개 이상의 테이블에서 공통된 값을 가진 데이터만 반환LEFT JOIN: 왼쪽 테이블의 모든 행과 오른쪽 테이블의일치하는 행만 반환RIGHT JOIN: 오른쪽 테이블의 모든 행과 왼쪽 테이블의 일치하는 행만 반환FULL OUTER JOIN: 왼쪽 및 오른쪽 테이블의 모든 행을 반환하고 일치하는 행이 없는 경우 NULL 값을 반환# orders.customer_id값과 customers.customer_id값이 일치하는 값만 반환 SELECT * FROM orders INNER JOIN customers ON orders.customer_id = customers.customer_id;
ON
JOIN을 수행할 때 사용 /JOIN에서JOIN의 조건을 지정하는 데 사용# table1.column_name과 table2.column_name이 같은 경우에만 데이터를 결합 # column2_name 열의 값이 10보다 큰 경우에만 데이터를 결합 SELECT * FROM table1 JOIN table2 ON table1.column_name = table2.column_name AND table1.column2_name > 10;
WHERE
- 데이터베이스에서 데이터를 검색하는 데 사용
AND,OR,NOT등의 논리 연산자를 사용가능# my_table 테이블에서 column_name 열의 값이 'value'인 데이터만 반환 SELECT * FROM my_table WHERE column_name = 'value'; ` # my_table 테이블에서 column_name1 열의 값이 'value1'이고 # column_name2 열의 값이 10보다 큰 데이터만 반환 SELECT * FROM my_table WHERE column_name1 = 'value1' AND column_name2 > 10;
GROUP BY
- 데이터를 그룹화하고 집계 함수를 사용하여 그룹화된 데이터에 대한 통계 정보를 계산하는 데 사용
# aggregate_function은 그룹화된 데이터에 대해 수행할 집계 함수 SELECT column_name, aggregate_function(column_name) FROM table_name # 데이터를 가져올 테이블의 이름 WHERE condition 데이터를 필터링하는 조건 GROUP BY column_name; # 그룹화할 열의 이름 .# employees 테이블에서 department 열을 기준으로 데이터를 그룹화하고 # COUNT 함수를 사용하여 각 부서의 직원 수를 계산 SELECT department, COUNT(*) FROM employees GROUP BY department;
HAVING
GROUP BY절을 사용하여 집계된 결과 집합에서 특정 조건을 가진 그룹을 필터링하는 데 사용# GROUP BY 절을 사용하여 집계된 각 고객의 주문 총액을 계산하고, # 그 총액이 1000보다 큰 고객만 반환(HAVING) SELECT customer_id, SUM(order_amount) as total_amount FROM orders GROUP BY customer_id HAVING total_amount > 1000;
LIMIT
- 검색 쿼리의 결과 집합에서 반환되는 행의 최대 수를 제한
# customers 테이블에서 처음 10개의 행만 반환 SELECT * FROM customers LIMIT 10;
CONCAT
- 두 개 이상의 열을 결합하거나 열과 상수 값을 결합하는 데 사용
# 'Hello world from ChatGPT' SELECT CONCAT('Hello ', 'world', ' from ', 'ChatGPT');
TRUNCATE
AVG밖에 사용되며 소수점 자리 수를 제어 할 수 있다# 만약 score 평균이 60이면 AVG(score) # '60.0000'으로 출력 TRUNCATE(AVG(score), 1) # '60.0' 출력 TRUNCATE(AVG(score), 0) # '60' 출력
SEPARATOR
GROUP_CONCAT()함수에서 사용되는 구분자- 결합된 문자열의 각 값 사이에 삽입되는 구분자를 지정하는 데 사용
# name1, name2, name3 ... GROUP_CONCAT(name SEPARATOR ',')
UNION
- 두 개 이상의 SELECT 문의 결과를 하나의 결과로 결합하는 SQL 질의어
- 두 개의 SELECT 문이 UNION으로 결합되는 경우, 두 개의 SELECT 문은 동일한 열 수를 반환해야 하며, 열의 데이터 유형도 일치해야 한다.
# 가능 select 'A' union select 'B'; . # 불가능 select 'A' union select 'B','C';
UNION은 중복되는 데이터는 생략한다.
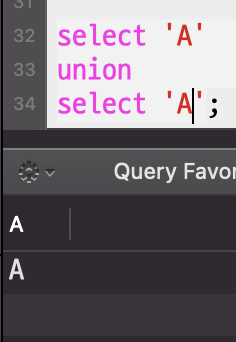
UNION ALL은 중복되는 데이터를 허용한다.
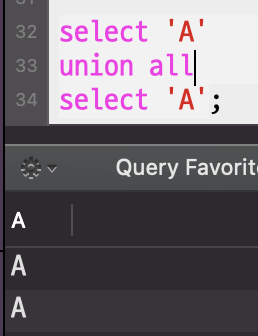

🙏