초기 컴퓨터 시스템은 Uniform Memory Access (UMA) 아키텍처 (SMP라고도 부름, Symmetric Multi-Processer)를 통해 모든 CPU가 동일한 메모리에 동일한 시간으로 접근할 수 있도록 설계되었다. CPU와 메모리가 메모리 컨트롤러를 통해 단일 주소 공간으로 연결되어 동일한 메모리 접근 시간을 제공할 수 있게 된다.
아래 그림처럼 우리가 흔히 아키텍쳐 시간에 배운 "기초적인 시스템 형상"이 바로 이 우마 구조이다.
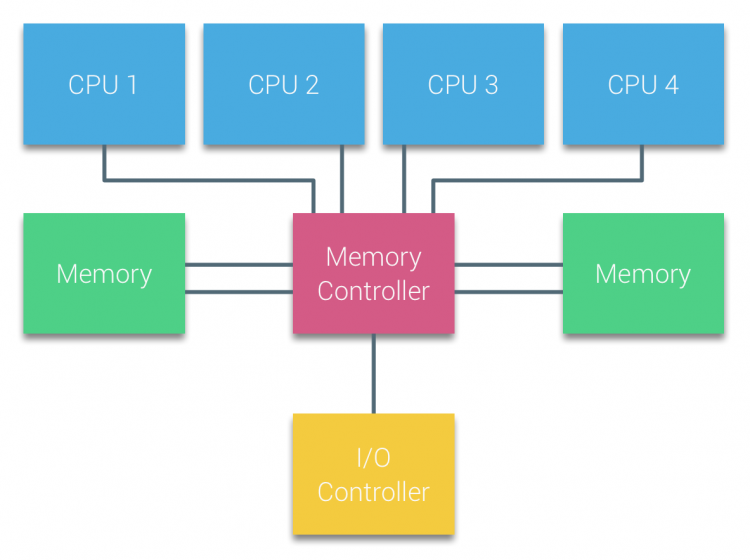
UMA는 90년대 서버에 쓰이던 수준의 CPU들이 수~개 정도 붙어 있는 형태에선 아무 문제가 없다. 당장 아직도 대부분의 개인 데스크톱은 여전히 UMA (Uniform Memory Access) 구조를 채택하고 있다.
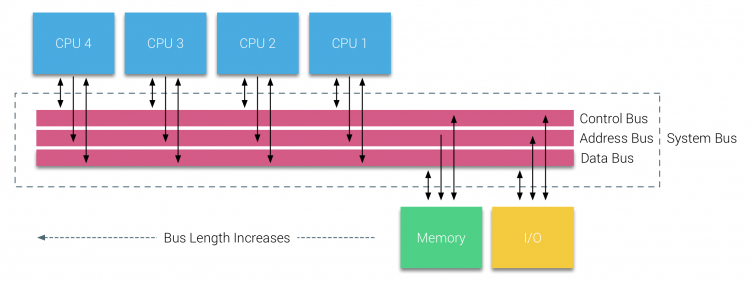
문제는 무엇이었을까, UMA는 서버나 고성능 워크스테이션처럼 여러 CPU가 필요한 환경보다는 규모가 작은 개인용 시스템에 적합해지기 시작한 것이다. 90년대 후반, 00년대 초반을 거치면서 CPU 성능 스케일업이 significant하게 이뤄짐에 따라 메모리 대역폭이 부족해진 것이다.
와중에 여러 CPU를 붙여보니 일부는 메모리를 접근하기까지의 버스 길이가 길어지면서 지연 시간이 커졌고, 동시에 버스는 너무너무 바빠진 것이다. 즉, 아키텍쳐 그 자체가 Bottleneck이 되기 시작한 것이다.
UMA는 CPU가 늘어나고 성능이 (메모리 성능 향상폭보다 더 급격하게) 좋아짐에 따라 확장성(Scaling) 문제를 겪게 된다.
UMA의 성능 병목 문제를 해결하기 위해 과거 선배들은 무엇을 했을까, 그렇다, 일단 각 CPU에 캐시를 추가하는 것이다(!). 그러나 예상하겠다만, 각 캐시에 동일한 메모리 블록의 여러 복사본이 생기면서 캐시 일관성 (Cache Coherency) 문제가 발생하게 된다. 이를 해결하기 위해선 캐싱 snoop 프로토콜 같은걸 쓰게 되는데, 우리가 아키텍쳐 수업 때 배우는 write invalidate 방식으로 다른 캐시에 저장된 중복 데이터를 무효화하여 일관성을 유지하는 프로토콜이 등장했다고 이해하면 된다.
하지만, 그럼에도 불구하고 확장성 문제는 지속되었고, Architectural한 변화를 갈구하게 된다!
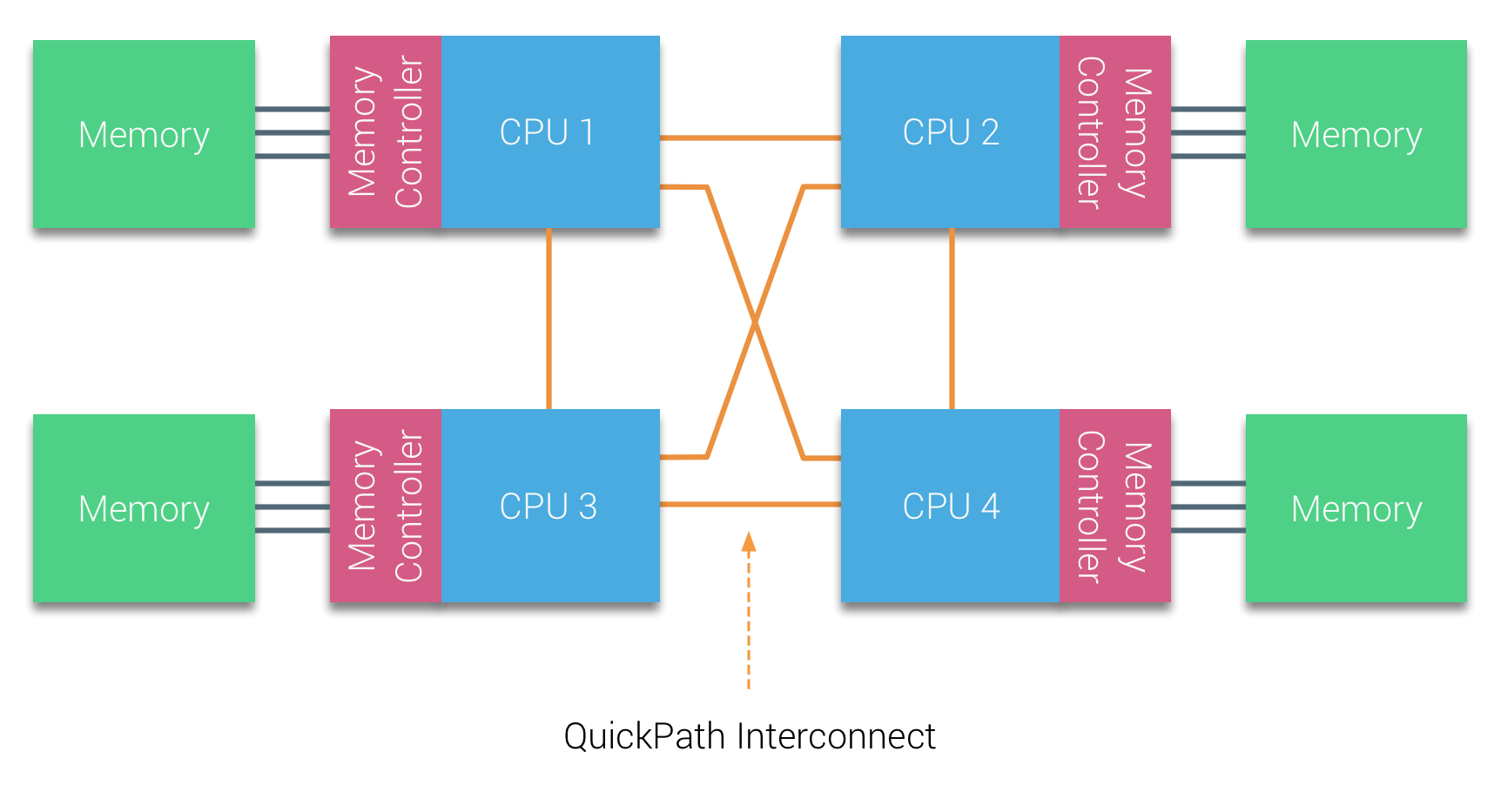
Non-Uniform Memory Access (NUMA) 아키텍처가 등장하게 된 이유가 바로 이거다. NUMA는 CPU마다 고유의 로컬 메모리를 두고, 다른 CPU의 메모리는 원격 메모리로 분류하되, 접근할 수 있게 만들어준다 (물론 이 경우 접근 시간은 로컬보다 떨어질 수 밖에 음슴).
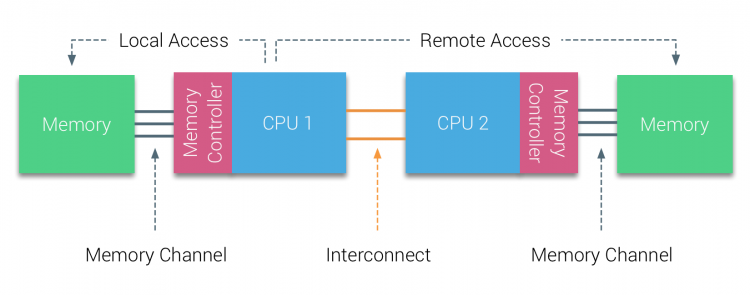
이렇게 CPU마다 자체 로컬 메모리를 할당하여 병목을 줄이고 메모리 접근 시간을 최적화하면 CPU가 늘어나도 각 CPU가 가깝게 연결된 로컬 메모리를 우선 사용할 수 있어 과거 UMA 구조랑은 다르게 중앙 메모리 버스 Bottleneck이 발생하지 않게 된다. 또한 로컬 메모리 부족하면 옆에꺼 빌려 써서 용량 문제는 해결하고,,, 이런 식이다.
암튼, 이렇게 등장한 NUMA의 특징을 요약하면 아래와 같다.
- 비일관적 메모리 접근: 메모리 위치에 따라 접근 시간이 달라지므로 CPU가 가깝게 연결된 메모리(로컬 메모리)를 우선적으로 사용해 성능을 높임.
- Point-to-Point 인터커넥트: 각 CPU를 독립적으로 연결하여 병목을 줄이고, AMD의 HyperTransport와 Intel의 QuickPath Interconnect (QPI)와 같은 기술로 대역폭을 개선함.
- 보통 10+-a의 GT/s (GT/s이란 Giga-Transfer per sec으로, GB/s으로 환산하면 대충 40GB/s 정도 됨)를 가짐 (참고로 PCIe 최근 generation들은 단순 대역폭만 놓고 보면 이것보다 수치가 더 큼. Gen5의 경우 32 GT/s정도 됨. 물론 QPI/UPI랑 PCIe는 애초에 목적이 달라서 직접 대역폭 비교는 무의미함)
- 확장 가능한 캐시 일관성: NUMA 시스템에서 증가하는 캐시 일관성 문제를 해결하기 위해, 캐시를 효율적으로 분할하고 확장 가능한 snoop 프로토콜을 통해 성능을 유지함.
이러한 누마 구조는 현대 IDC에 들어가는 고성능 서버급 멀티프로세서 시스템의 기반 구조이고, OS랑 VM도 이에 맞춰서 열심히 연구되어 왔다. 특히나 요즘 CXL 연구에서도 NUMA 아키텍쳐 특징을 활용하는 연구들이 꽤 이뤄지고 있다. 이런걸 보면 누마를 잘 알아야겠지?
자, 지금부터는 따라서 아래 글들을 읽어보자. 브로드컴에서 VMWare 개발자 중에 한 분이 작성한 글인데, 누마 특성을 이 글에서 논한 인트로덕션적 수준을 넘어서 굉장히 디테일하게 잘 설명해주고 있다 (위 그림들도 다 이 분 글에서 따온 거임).
누마 알고 싶은 사람들은 언능 읽어보도록~
NUMA Deep Dive Part 1: From UMA to NUMA
NUMA Deep Dive Part 2: System Architecture
--> 현대 누마 구조에서 Uncore HW 모듈의 역할, 그리고 interleave 설정 등이 미치는 영향, QPI 설정 등등 다루고 있음.
NUMA Deep Dive Part 3: Cache Coherency
NUMA Deep Dive Part 4: Local Memory Optimization
NUMA Deep Dive Part 5: ESXi VMkernel NUMA Constructs
본 글에 담긴 Claim격의 서술은 모두 제 개인의 의견일 뿐이며 아무런 대표성을 가지지 않습니다.
