본 포스팅을 기점으로 '시스템 프로그래밍' 전반에 대한 개념 공부 과정을 Velog에 기록하고자 한다. 본인의 복습이 포스팅의 가장 큰 목적이다. 본 포스팅의 내용은 Randal E. Bryant와 David R. O'Hallaron이 공동 저술한 'Computer Systems: A Programmer's Perspective'를 토대로 한다.
Control Flow
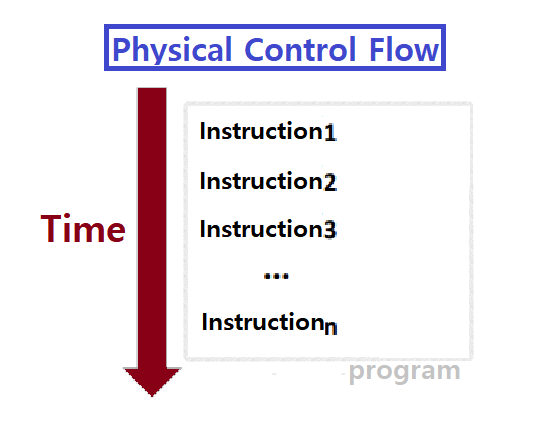
Physical Control Flow
물리적인 '제어 흐름', 'CPU 관점에서의 제어 흐름'을 우리는 Physical Control Flow라고 부른다.
모두 알다시피, 현대 전자기기는 여러 개의 CPU 또는 코어가 탑재된다. 하지만, 본 학습에서는 학습 편의성을 위해 '단일 CPU(프로세서)' 상황을 기준으로 한다.
CPU는 '한 순간에 한 명령'만 수행한다.
프로그램의 Source Code가 Compile되어 Machine Language가 되고, 라이브러리 Linking 후, Loader를 통해 DRAM 메모리에 코드가 올라가 프로그램이 실행된다.
~> 이때, 메모리 공간 하나하나는 단 하나의 명령을 저장한다. 이러한 관점에서, 프로그램을 'Set of Instructions'라고 할 수 있다.
~> CPU 입장에서 프로그램을 실행한다는 것은 결국, 그저 '명령어의 Sequence, Set'을 Iterative하게 처리하는 것이다. 매우 단순하게 말이다!
CPU 관점에서 이 상황을 다시 한 번 들여다보자.
1) CPU가 메모리(ex. Volatile DRAM)에서 데이터를 긁어 Data Bus를 통해 가져온다. (Fetch)
2) 그리고 이 데이터를 CPU의 Instruction Register 저장공간에 저장한다.
3) CPU의 Program Counter는 '그 다음'의 명령이 담긴 주소를 가리키도록 조정된다. (PC++)
4) CPU는 레지스터에 든 명령을 Decode하고 Execute한다. (Decode & Execute)
5) 하드웨어적으로 Clock이 뛰면서 이 과정이 계속해서 반복된다. PC를 증가시키면서 말이다.
~> CPU는 언제나 '한 번에 한 명령씩' 처리한다. 시작부터 종료되는 순간까지 언제나 동일한 'Read & Execute'를 반복한다. (현대의 파이프라이닝 CPU는 논외)
=> 이러한, 1)에서부터 5)까지의 과정을 우리는 'Physical Control Flow', 짧게 줄여서 'Control Flow'라고 부른다. ★★★
Exception: corrupt 'Control Flow'
학부 2학년 수준까지 학습한 상태에서는, Control Flow를 흐트리는 두 가지의 경우를 알고 있을 것이다.
1) Jump와 Branch : 점프와 분기
2) Call과 Return : 함수의 호출과 반환
~> 이 둘은 순차적인 Control Flow를 변경한다. 이들은 프로그램 관점에서의 흐름 변화, 즉, 'Change in the Program State'이다.
=> 우리가 다루고자 하는 것은, 'Change in the System State'이다. 즉, 시스템 관점에서의 흐름 변화이다. 프로그램 내부에서 Code-Level의 분기나 함수 호출을 논하지 않는다.
시스템 관점에서 Flow가 흐트러지는 상황은 어떤 것이 있을까? 바로 아래와 같은 것들이다. 우리는 이를 'Exception', 즉, 예외라고 부른다.
Example Situation
CPU가 CPU 외부에 위치한 '메모리' 내의 어떠한 정보를 읽어올 때, 그 정보가 언제 CPU로 도착할지는 CPU 입장에서 알 도리가 없다.
CPU는 메모리에서 읽어오는 정보가 언제 넘어올지를 모른다.
-
ex) 예를 들어보자. 어떤 응용 프로그램 'APP'이란 것은 메모리에 적재된 'temp'라는 1MB 파일에서 4KB만큼 데이터를 읽어오는 기능을 수행한다.
-
즉, APP의 소스코드 안에는 "f = open(~), ptr = malloc(1MB짜리 buf, ~), fread(f, ptr, 4KB만큼)" 이런식으로 명령이 있을 것이다. (C기준)
-
'CPU 외부의' 디스크/SSD/네트워크에는 'temp'라는 파일이 들어가 있다. 이 파일에서 4KB만큼을 읽어서 메인메모리 내 버퍼에 채울 것이다.
-
APP 프로그램이 특정 OS(운영체제) 위에서 수행된다. 이때, APP의 읽기 명령이 컴퓨터에 하달되어, OS는 SSD에 "나 읽을거야~"라고 명령을 보낸다.
-
OS 내에 있는 자료구조에 보조기억장치의 메모리 구조가 형성되어 있다. OS는 거기서 temp의 위치를 파악해, SSD DMA에 'ptr', 'read 명령', '읽을 size' 정보를 보낸다.
-
이 명령을 받은 SSD는 Direct Memory Access (DMA)를 통해 해당 부분의 데이터를 복사해서 메인메모리로 보내준다.
- 여기서 Cache니 DMA니 뭐니 하는 세부 개념은 추후 설명할 것
-
이때, CPU 입장에서는, SSD가 보내는 "나 메모리 읽었다~ 메인메모리에 이거 보낼게~"라는 것을 어떻게 알 수 있을까? CPU는 이 메세지가 오는 시점을 예측할 수 있을까? 없다. 모른다는 것이다.
-
허나, 요청 데이터가 언제 올지를 모른다고 해서 CPU는 그냥 마냥 기다려야할까?
마냥 기다리기만 하면 CPU의 능력이 너무 아깝다!
=> 따라서, 컴퓨터 효율성을 위해, APP의 fread가 수행되면, CPU는 APP 실행(처리)을 잠시 접어두고(Suspend), 다른 일을 하게 된다.
=> 또는, 때때로 어떤 상황에서는 아무런 일도 하지 않고 기다린다.
==> 이러한 상황들이 바로 Control Flow가 깨진 것이다.
Ex) Data를 디스크나 네트워크에서 가져오는 상황
Ex) Division by Zero 상황
Ex) 키보드에서 'Ctrl+C'가 눌린 상황
Ex) System Timer Expiration 상황
이렇게 대표적으로 4가지 정도의 '시스템 관점에서의 예외' 상황이 존재한다. 이들은 모두 Control Flow를 흐트리는 Event들이다.
~> 이런 예외들을 처리하는 플로우를 'Exceptional Control Flow(예외 처리 흐름)'이라 한다.
System needs mechanisms for 'Exceptional Control Flow'
여담) 프로세스가 종료되어 OS로 제어권이 넘어가는 것도 Exception의 일종이다. 프로그램이 정확히 언제 끝날지 시스템 입장에서는 예측할 수 없기 때문이다.
※ 프로세스 : 프로그램이 obj코드가 되어 메모리에 적재되면, 메모리 위에 있는 그 '명령의 시퀀스'를 '프로세스(Process)'라고 한다.
Exceptional Control Flow
예외 처리 흐름은 아래의 두 가지 종류가 있다.
-
Low-Level한 Exceptional Control Flow 매커니즘
- 'System Event(Change in System State)'에 대해 반응한다.
- HW와 OS Software를 이용해 대응한다.
-
High-Level한 Exceptional Control Flow 매커니즘
- Process Context Switch, Signal, Nonlocal Jump 등에 대해 반응한다.
- Process Context Switch의 경우, OS와 HW Timer를 이용해 대응한다.
- Signal의 경우, OS Software를 이용해 대응한다.
- Nonlocal Jump의 경우, C언어의 런타임 라이브러리로 대응한다.
~> 다 곧 다루게될 개념이다. 우선, 이 범주를 기억하도록 하자.
시스템 이벤트는 Low-Level한 ECF로, Context Switch나 Signal, Jump는 High-Level한 ECF로 대응한다.
Exception
Exception(예외)을 엄밀하게 정의하면 아래와 같다.
Exception : 특정한 이벤트에 의해 현재 'CPU 제어권(Control)'을 Application Program에서 OS Kernel로 넘겨주는 것
~> 이때, Event라 함은, 앞서 말한 4가지 경우를 포함해, Overflow, Page Fault, I/O 상황 등이 포함된다.
- Question) CPU 입장에선 OS도 프로그램이잖아요, OS 위의 응용 프로그램과 OS를 어떻게 구분하죠?
- Answer) CPU가 명령을 수행할 때, Mode Bit라는 것이 있다. 0과 1로 이를 구분한다.
- CPU 안에는 MMU(Memory Manager Unit)라는 것이 있다. 그 안에 Mode Bit가 있다. 이 비트의 값을 기준으로 User Level Code와 OS Kernel Code를 구분한다.
- Answer) CPU가 명령을 수행할 때, Mode Bit라는 것이 있다. 0과 1로 이를 구분한다.
Exception Handler
-
OS Kernel : OS의 '메모리 상주(Memory-Resident)' 부분이다.
- CPU 입장에서 '예외'는, APP 명령을 수행하다가 OS 명령을 수행하게 되는 것이다.
-
CPU는 오로지 한 가지 명령을 수행한다. APP 명령을 수행하고 있다가 Exception이 발생하면, 제어권이 커널로 넘어간다. 커널에서 예외에 대한 처리를 수행한다. 뭐로? Exception Handler로!
- Exception Handler란, OS Kernel Code에 있는 특정 Code Module이다.
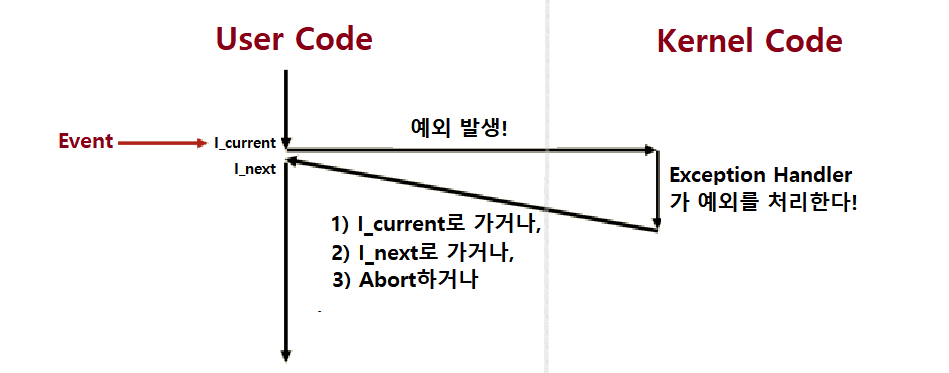
- 커널의 예외 처리에는 3가지 옵션이 있다. (Handler)
- Return to I_current (현재 명령으로 복귀)
- Return to I_next ((현재의) 다음 명령으로 복귀)
- Abort (종료)
Exception Table
- 이때, OS 안에는 'Exception Table'이 있고, 여기에 '예외에 맞는 처리(Handler)'가 목록화되어 있다. 0번부터 인덱스가 있고, 각각의 인덱스 번호에 해당하는 Exception Handler Code의 Address를 담고 있다.
- k라는 인덱스에 해당하는 예외가 발생하면, 그 예외에 대한 처리 코드를 담고있는 Excepion Handler의 코드 부분의 주소가 반환된다.

Classes of Exception
예외의 크게 두 가지 Class로 나뉜다.
Asynchronous Exception
- Interrupt : I/O 장치로부터 시그널을 처리해야할 때 나타나는 이벤트이다.
- 데이터가 언제 오는지 알 수 없다.
- 인터럽트가 걸리게 되면, 현재 수행하는 명령을 끝내고, 잠시 Suspend 되어 있다가, 다 읽어오면, 잠시 멈췄던 시점으로 돌아가 다음 명령을 계속 수행한다.
- 위의 fread(Input하는) 상황, 즉, 디스크나 네트워크에서 데이터를 읽어오는 상황이 바로 이 인터럽트에 해당한다.
즉, 인터럽트 상황에선 항상 I_next로 돌아간다.
Synchronous Exception
- Trap : System Call처럼, 프로그래머가 의도적으로 발생시킨 예외이다.
- 역시 잠시 Suspend 되어 있다가, 다 읽어오면, 다시 멈췄던 시점으로 돌아가 다음 명령을 계속 수행한다.
즉, 트랩 상황에선 항상 I_next로 돌아간다.
- 역시 잠시 Suspend 되어 있다가, 다 읽어오면, 다시 멈췄던 시점으로 돌아가 다음 명령을 계속 수행한다.
- Fault : Page Fault나 Segmentation Fault 같은 예외이다. 프로그램 명령어의 결과물로서 발생하는 이벤트로, 가능 결과가 두 가지이다.
-
Potentially Recoverable Error
- I_current로 돌아가거나 (Possible Result 1)
- 또는, 그냥 종료하거나 (Possible Result 2)
-
Page Fault : Virtual Memory와 관련된 예외이다.
-
물리적인 메인 메모리 DRAM이 있고, 이 주메모리가 1GB라고 하자. 32비트 CPU 컴퓨터를 기준으로 한다.
-
32비트 컴퓨터이므로 2^32, 즉, 약 4GB 정도의 '프로그래머가 할당할 수 있는 'Addressing Range를 가진다.
-
그러나, 실제 물리적인 주기억장치 DRAM의 크기는 1GB라고 하자.
-
OS는 Virtual Memory로 메모리를 Mapping해주는데, Virtual Memory 4GB 중 1GB는 실제 DRAM으로, 나머지 3GB 정도는 보조기억장치 디스크/SSD의 일부분에 맵핑한다.
-
가장 쉽게 말하면(실재와 차이가 있음), 프로그램이 특정 메모리를 접근할 때, 0~1GB 정도는 DRAM을 읽는 것이고, 1GB~4GB 정도는 디스크 쪽을 읽는 것이다.
-
알다시피, 프로그래머 입장에는 이를 결정할 수 없다. OS가 가상 메모리를 알아서 처리해주기 때문이다.
-
이때, DRAM에 맵핑되지 않은 메모리를 접근할 때, 바로 이 'Page Fault'가 발생한다.
- "어라랏? Virtual Memory로 봤을 땐 DRAM이었는데, 실제 DRAM에 맵핑되어 있지는 않네?! Paging에 실패했네?!"
- Paging의 의미는 추후 설명
- "어라랏? Virtual Memory로 봤을 땐 DRAM이었는데, 실제 DRAM에 맵핑되어 있지는 않네?! Paging에 실패했네?!"
-
OS는 이 상황에서, 디스크에서 데이터를 읽어서 DRAM으로 가져와야 한다. 그 후, CPU는 다시 DRAM을 읽어서(I_current로 돌아가) 해당 데이터를 취급하게 된다.
- 그래서 Page Fault는 'I_current'로 돌아가는 것이다. 실패했던 명령을 다시 시도하려고! 왜냐? 이번엔 반드시 DRAM에 있을거니까!
즉, Page Fault가 발생하면, CPU는 두 다리(SSD->DRAM)를 거쳐온 데이터를 읽게 된다.
즉, 폴트 시에는 I_current로 돌아간다. (또는 Abort)ex) a[24] = 3;이라는 배열 요소 접근 명령이 수행되는데, CPU의 MMU가 이를 분석했더니, DRAM이 아니라 디스크에 있다는 것을 알게 되었다. 그래서 Page Fault가 발생했다. OS의 핸들러가 이 예외를 처리하는데, 디스크에서 DRAM으로 해당 데이터를 가져오고, Fault를 발생시켰던 그 명령(어셈블리어 관점에서 LOAD)을 다시 실행하는 것이다. 또는 상황에 따라 Abort할수도 있다(SegFault).
-
-

-
Abort : 하드웨어 에러로 인해 발생하는 예외이다.
-
Nonrecoverable Error : HW 문제로 발생하는 예외는 회생불가이다.
- Unlike 'Recoverable Error(Fault)'
- 바로 종료(Abort)해버린다. (Never Returns)
- Abort한다는 것은, 에러의 원인 프로세스를 종료시킨다는 것이다.
-
하드웨어 에러라 함은, Bit Flip 같은 것이 있다. 외부적(물리적) 요인으로 인해 비트가 뒤집히는 현상을 의미한다. 왠만해서는 패리티 비트 기술로 이를 커버하지만, 간혹 낮은 확률로 그렇지 못한 에러가 발생할 수 있다.
- Bit Flip이 감지되면, CPU가 커널에 이를 알리고, 커널의 Handler가 해당 Process를 Abort시킨다.
-
Difference between Async Exc and Sync Exc
CPU는 오로지 커맨드만 내린다. 커맨드의 결과가 예외일 때, CPU가 다른 일을 하면서 기다릴 때, 이를 비동기식 예외, 다른 말로, 인터럽트라고 한다.
반대로, CPU가 다른 일을 하지 않고 기다리는 것은 동기식 예외, 트랩, 폴트, 어볼트이다.

감사합니다.