
System-Level I/O
컴퓨터공학에서 I/O(Input & Output)은 다음과 같이 정의할 수 있다.
I/O : Main Memory와 External Device 사이의 소통
Input은 External에서 Main Memory로, Output은 Main Memory에서 External로
~> 이때, External Device라 함은, HDD(Hard Disk), SSD, Terminal, Network 등이 있겠다.
-
ANSI C : 우리에게 아주 친숙한 Standard I/O Library를 제공한다. printf나 scanf가 대표적이다.
-
Linux : OS Kernel에서 제공하는 UNIX I/O(이를테면 System Call)를 사용해서 구현한 여러 가지 High-Level I/O Function을 사용한다.
- 즉, 프로그래머 입장에서, UNIX I/O를 직접 사용하는 것이 아니라, 그 UNIX I/O를 사용하는 여러 가지 Linux 고급레벨 함수를 사용한다는 것이다. ★
- 물론, 직접 사용할 수 있다.
- 즉, 프로그래머 입장에서, UNIX I/O를 직접 사용하는 것이 아니라, 그 UNIX I/O를 사용하는 여러 가지 Linux 고급레벨 함수를 사용한다는 것이다. ★
그런데, 우리가 본 Chapter2 연재에서 다룰 내용은 UNIX I/O부터이다. 프로그래머가 UNIX I/O를 사용할 일이 많지 않다면, 굳이 배울 필요가 있을까?라는 의문이 들 수 있다.
UNIX I/O를 배우면 System적인 많은 개념을 더 잘 이해할 수 있다. 또한, 간혹 UNIX I/O를 직접 사용해야하는 상황도 있다.
예를 들어, 파일의 Metadata를 추출하고 싶을 땐, Standard I/O Library에서는 관련 함수를 찾을 수 없다. stat이라는 System Call로만 이 일을 할 수 있다. stat은 대표적인 UNIX I/O이다. 또한, 네트워크 입출력에서도 Library는 사용할 수 없다.
~> 따라서, 우리는 UNIX I/O를 배워야한다.
File
File : Linux에서 File이라 함은, 여러 바이트의 시퀀스이다.
- (여담) 파일을 '섹터(Sector)의 집합'이라고도 한다.
- Hard Disk의 구조를 보면, 가장 작은 단위는 Sector라 할 수 있다. Sector는 보통 512B 정도 크기를 지닌다. 즉, 0.5KB 정도 크기인 것이다.
- 여기서 착안해, 파일을 '섹터의 집합'이라고도 표현한다.
- Hard Disk의 구조를 보면, 가장 작은 단위는 Sector라 할 수 있다. Sector는 보통 512B 정도 크기를 지닌다. 즉, 0.5KB 정도 크기인 것이다.
"모든 것이 파일이다."
-
모든 I/O Device는 파일로 표현할 수 있다.
- /dev/sda2 ~> /usr Disk Partition
- /dev/tty2 ~> 터미널
-
디렉토리도 파일이다.
-
Kernel도 파일이다.
- /boot/vmlinuz-3.13.0-55-generic ~> 커널 이미지
- /proc ~> OS 커널의 자료구조
-
당연히, 프로그램도 파일이다.
- /bin/ls : ls 프로그램
각 Device와 데이터를 파일화(Mapping to Files)하는 이유는, Kernel이 이를 뽑아낼 수 있게 하기 위함이다.
즉, 모든 입출력 데이터를 파일화한다.
- 파일 관련 기본 Unix I/O (System Call)
- open() : 파일 열기
- close() : 파일 닫기
- read() : 파일 읽기
- write() : 파일 쓰기
- lseek() : 'Current File Position'을 찾는다.
- 즉, 입출력을 위한 파일 내의 'Offset'을 찾는다.
- lseek을 통해 파일 Offset을 마음대로 변경할 수 있다.
File Type
각 파일에는 해당 파일이 System에서 가지는 역할(Role)에 대한 Type이 있다.
Regular File, Directory, Socket, Named Pipes, Symbolic Link, Character, Block Device 등
-
Regular File : 그냥 '임의의 정보(Arbitrary Data)'를 가진 일반적인 파일을 의미한다. Document부터, Audio, Media, Program 파일 등 Any File!
-
Directory : 관련된 '파일의 집합을 위한 인덱스'를 가지는 파일을 의미한다. 즉, 폴더!
-
a.txt, b.txt, c.txt라는 파일들이 workspace라는 디렉토리에 들어있다고 해보자.
- 디렉토리도 파일이라 했다. 이 파일에는, 다른 파일을 가리키기 위한 인덱스인 Inode가 있다.
즉, Regular File처럼 어떠한 컨텐츠를 가진 것은 아니지만, 내부의 각 파일들을 인덱싱할 수 있는 Table을 가지고 있는 파일을 디렉토리라 하는 것이다.
-
-
Socket : 다른 Machine에 있는 프로세스와 소통하기 위한 파일이다.
- 즉, Ethernet과 같은 Network에서, 프로세스 P1이 Client에, 프로세스 P2가 Server에 있다 하면, P1과 P2가 서로 소통하기 위해 필요한 파일을 Socket이라 부르는 것이다.

- 기타 : 이들은 Chapter2의 논외이다.
- Named Pipe ~> IPC를 위한 파이프라인의 fd[2]와 같은 파일을 의미!
- Symbolic Link ~> 바로가기 파일 등
- Block Device ~> 키보드 같은 것 등
Regular File
Regular File contains arbitrary data.
-
즉, Application 파일이 모두 Regular File에 해당한다.
-
Binary File과 Text File로 나눌 수 있다.
-
Text File : 오직 ASCII나 Unicode 문자로만 이루어진 파일을 의미한다.
-
Text File = "Sequence of Text Lines"
-
Text Line : 'Newline Character(\n)'로 끝나는 문자열
-
EOL(End of Line)
- Linux와 Mac : 0xa(\n) = LF(line feed)
- Windows와 인터넷 프로토콜 : 0xd 0xa (\r\n) = CR(Carriage Return) + LF
-
-
-
Binary File : 이진수로 이루어진, Text File 외의 모든 파일을 의미한다.
- obj 파일, 그림 파일 등
-
참고로, Kernel은 Regular File에 대해, Binary와 Text를 구분하지 않는다.
Directory
Directory : 파일 이름에 대해 위치를 나타내는 Link들의 Array(Table)이다.
-
Directory = "Array of Links"
- 각 Link는 File에 대한 Filename을 가리킨다.
-
각 디렉토리는 디폴트로 다음의 두 Entry를 가진다.
- .(dot) : 자기 자신
- ..(double dot) : Directory Hierarchy 상에서 상위 디렉토리
-
디렉토리에 대한 명령어
- mkdir : 빈 디렉토리 생성
- ls : 디렉토리 내 컨텐츠 확인
- rmdir : 빈 디렉토리 삭제
- 비어있지 않으면 기본적으로는 삭제할 수 없음. ★
-
디렉토리 계층구조(Directory Hierarchy)
- 처음 root부터 시작해서 쭉 트리형태로 뻗어나간다.
Leaf Node가 아닌 Node는 모두 Directory이다. ★★
-
Kernel은 각 프로세스에게 '현재 디렉토리(Current Working Directory)'를 cwd라는 이름으로 제공한다.
- bash shell로 확인해보자!

-
계층구조에서 '파일의 위치'는 Pathname이란 것으로 표기한다. 쉽게 말해서 경로이름이다.
-
Pathname(경로명)
-
Absolute Pathname : 루트인 /부터 시작해서 쭉 나아가는 것 (절대 경로)
- /home/droh/hello.c
- /usr/include/sys/unistd.h
-
Relative Pathname : cwd부터 시작해서 쭉 나아가는 것 (상대 경로)
- cwd가 /home/bryant라면, hello.c 파일의 상대 경로는,..
- ../droh/hello.c
- cwd가 /home/bryant라면, hello.c 파일의 상대 경로는,..
-
File Open & Close
파일을 연다는 것은, Kernel에게 "나 이제 이 파일 접근할 준비됐어!"라고 알리는 것과 같다.
int fd; /* 파일 지정자(File Descriptor) */
if ((fd = open("/etc/hosts", O_RDONLY)) < 0) {
perror("File Open Error");
exit(1);
}-
open함수를 사용하면, Kernel이 Return Value로 File Descriptor를 반환한다.
- open의 리턴값이 -1이면, 그것은 에러 상황이다.
-
프로세스는 File Descriptor Table을 가진다. ★
-
리눅스 Shell에서 생성된 각 프로세스는 아래의 세 파일 지정자를 Default로 가진다.
- 0번 : Standard Input (stdin, STDIN_FILENO)
- 1번 : Standard Output (stdout, STDOUT_FILENO)
- 2번 : Standard Error (stderr, STDERR_FILENO)
이 세 파일 지정자는 예약(Reserved)되어 있다. 따라서, 프로세스에서 open함수를 처음 호출하면, 3번 인덱스부터 반환한다. ★★★

파일을 닫는다는 것은, Kernel에게 "나 이제 이 파일 접근 끝낼게!"라고 알리는 것과 같다.
int fd;
int ret; /* Return Value */
// 리턴값을 확인하는 습관은 매우 좋은 습관이다.
if ((ret = close(fd)) < 0) {
perror("File Close Error");
exit(1);
}- 이미 닫힌 파일을 또 close 함수로 닫는 행위는 Thread 프로그램에서 최악의 행위이다. (주의. 이유는 OS 시리즈에서 다룰 것)
File Read & Write
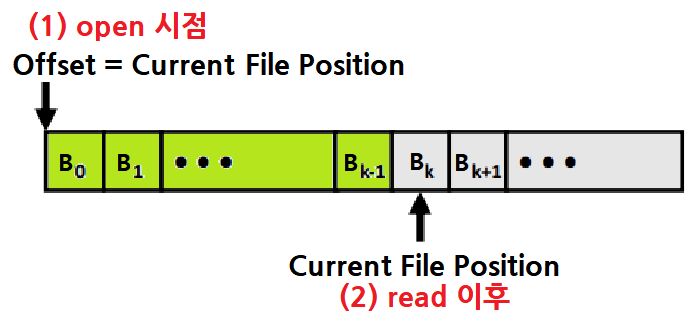
파일을 읽는다는 것은, 'Current File Position(somewhere in SSD or something)'에서부터 복수의 바이트를 복사해서 Main Memory에 놓고, 그 다음 Current File Position을 Update하는 것이다.
즉, "선 Copy 후 fd Update"이다.
- fd가 어딘가를 가리키고 있고, 그곳에서부터 데이터를 얼마만큼 복사하고, 그러나서 fd를 옮기고,... 이런 과정!
char buf[512];
int fd;
int m; /* 읽은 바이트 개수 */
if ((fd = open("/etc/hosts", O_RDONLY)) < 0) {
perror("File Open Error");
exit(1);
}
if ((m = read(fd, buf, sizeof(buf))) < 0) {
perror("File Read Error");
exit(1);
}-
"read(fd, buf, sizeof(buf))"의 의미
-
fd의 Current File Position부터 sizeof(buf)만큼 읽어서 buf에 넣고, 읽은 바이트 개수를 반환한다. ★
-
read 함수의 반환값이 0보다 작으면 에러 상황이다.
-
내가 요청한 사이즈보다 실제 읽은 바이트 수가 적은 것은 에러가 아니다.
- 이를 'Short Count'라고 한다. 위 예시 코드에서 m < sizeof(buf) 상황이다!
-

파일에 쓴다는 것은, Main Memory에서 복수의 바이트를 복사해서 Current File Position에서부터 덮어쓰고, 그 다음 Current File Position을 Update하는 것이다.
즉, "선 Copy 후 fd Update"이다. (read와 동일)
char buf[512];
int fd;
int m; /* 쓰여진 바이트 개수 */
if ((fd = open("/etc/hosts", O_RDONLY)) < 0) {
perror("File Open Error");
exit(1);
}
if ((m = write(fd, buf, sizeof(buf)) < 0) {
perror("File Write Error");
exit(1);
}-
"write(fd, buf, sizeof(buf))"의 의미
-
sizeof(buf)만큼 buf를 복사해서 fd의 Current File Position에서부터 넣고, 쓴 바이트 개수를 반환한다. ★
-
write 함수의 반환값이 0보다 작으면 에러 상황이다.
-
내가 요청한 사이즈보다 실제 읽은 바이트 수가 적은 것은 에러가 아니다. (역시나)
- 이를 'Short Count'라고 한다. 위 예시 코드에서 m < sizeof(buf) 상황이다!
-
아래와 같은 간단한 C코드를 보자.
int main(void) {
char c;
while(Read(STDIN_FILENO, &c, 1) != 0) // Wrapper로 씌운 Read/Write
Write(STDOUT_FILENO, &c, 1);
return 0;
}~> 터미널에서 문자열이 입력되면, 한 문자씩 읽어서 화면에 쓰는 프로그램이다.
=> 매우 비효율적인 프로그램이다.
--> read와 write는 System Call이다. 즉, Overhead가 많다. 한 번의 호출에 대략 20ms 정도의 Overhead가 난다고 한다. 이는 인간에겐 짧은 시간일지 몰라도, 컴퓨터에겐 너무나 긴 시간이다. 위 코드처럼 read/write를 잦게 호출하는 경우, 시간 비효율이 매우 높은 것이다.
read나 write 시에는, 시간 효율을 높이기 위해, 큰 바이트 단위로 읽는 것이 좋다. 일반적으로 Chunk(0.5KB, 512B)단위로 읽고 쓰곤 한다.
Short Count
read나 write 시 발생할 수 있는 상황이다. 읽거나 쓴 바이트 개수가 요청한 바이트 개수보다 작을 때를 의미한다.
-
Short Count 발생 상황
- read 중 EOF(End of File)을 만날때
- 터미널에서 read할 때, Newline을 만날때
- Network Sochet을 읽고 쓸 때
-
디스크에서 읽고 쓸 때는 read 시 EOF를 만날 때를 제외하고는 Short Count가 발생하지 않는다. 매 읽기마다 읽을 수 있는 만큼 다 읽기 때문! ★
RIO Package
본인이 SP 연재에서 참고하는 교재 'Computer Systems: A Programmer's Perspective'에서는 RIO Package를 제공한다. 지난 포스팅에서 다룬 SIO 라이브러리와 같은 느낌이다. SIO와 RIO 모두 이후 연재에서 계속 언급될 것이기 때문에 알고 넘어가자.
- RIO Package
- Efficient & Robust Wrapper for I/O
- 네트워크 입출력에 알맞게 구현되었다고 한다.

-
RIO Package는 Unbuffered와 Buffered를 모두 제공한다.
-
Unbuffered : rio_readn, rio_writen
-
Buffered : rio_readlineb, rio_readnb
-
Unbuffered RIO Input & Output
- Unbuffered의 경우, UNIX의 read & write와 동일하다. ★
UNIX의 read & write는 Unbuffered Input & Output이다. ★★★
- 네트워크 소켓에서 데이터를 주고받을 때 좋은 성능을 보인다고 한다.
ssize_t rio_readn(int fd, void *usrbuf, size_t n);
ssize_t rio_writen(int fd, void *usrbuf, size_t n);
/* Return */
// num of bytes transferred if OK
// 0 on EOF (rio_readn only)
// -1 on error-
rio_readn은 EOF를 만날 때만 Short Count 상황이 만들어진다.
- 버퍼가 제공되지 않기 때문에 얼마를 읽을지 알고 있을 때만 써야한다. ★
-
rio_writen은 Short Count 상황이 만들어지지 않는다.
아래는 rio_readn 함수의 내부이다. 구성 원리를 알아보고 가자.
ssize_t rio_readn(int fd, void *usrbuf, size_t n) {
size_t nleft = n; // nleft는 n에서 좌로 갈 변수!
ssize_t nread;
char *bufp = usrbuf;
while (nleft > 0) {
if ((nread = read(fd, bufp, nleft)) < 0) { // nleft만큼 읽는다.
if (errno == EINTR) // Interrupt 상황 시, 다시 수행! ★
nread = 0;
else
return -1; // 에러 상황 시 -1 반환 및 종료
}
else if (nread == 0) // 파일의 끝을 만났을 때!
break;
nleft -= nread; // 읽은 만큼 nleft는 좌로 이동
bufp += nread; // 읽은 만큼 버퍼주소는 우로 이동
}
return (n - nleft); // 읽은 양을 반환
}~> 시그널 인터럽트 시 다시 read를 수행하게 함을 주목! (rio_readn)
Buffered RIO Input & Output
Buffered의 경우 내부 메모리 버퍼를 두어 조금 더 효율적인 입출력을 도모할 수 있다.
Unix I/O는 Unbuffered이다. 따라서 Buffered RIO가 더 수행속도가 빠르다.
void rio_readinitb(rio_t *rp, int fd);
ssize_t rio_readlineb(rio_t *rp, void *usrbuf, size_t maxlen);
ssize_t rio_readnb(rio_t *rp, void *usrbuf, size_t n);
/* Return */
// num of bytes read if OK
// 0 on EOF
// -1 on error-
rio_readlineb : fd에서 텍스트 라인을 읽을 수 있는 최대로 읽고, 버퍼에 넣어놓는다.
-
네트워크 소켓에서 텍스트를 읽을 때 상당히 효율적이다.
-
종료 조건
- MaxLen만큼 바이트가 읽혔을때
- EOF를 만났을 때
- Newline Character를 만났을 때 (이것이 readnb와의 차이)
-
-
rio_readnb : fd에서 최대 바이트만큼 읽을 수 있는대로 읽고, 버퍼에 넣어놓는다.
- 종료 조건
- MaxLen만큼 바이트가 읽혔을때
- EOF를 만났을 때
- 종료 조건
rio_readnb와 rio_readlineb는 서로 겹쳐서 써도 상관없지만, 이 둘은 rio_readn과는 함께 쓰지 않도록 한다.
Buffered I/O Details
Buffered : File에 버퍼를 할당하는데, 이 버퍼에는 파일로부터는 읽었지만, 아직 사용자 코드 레벨에선 읽지 않은 데이터가 들어있다. ★
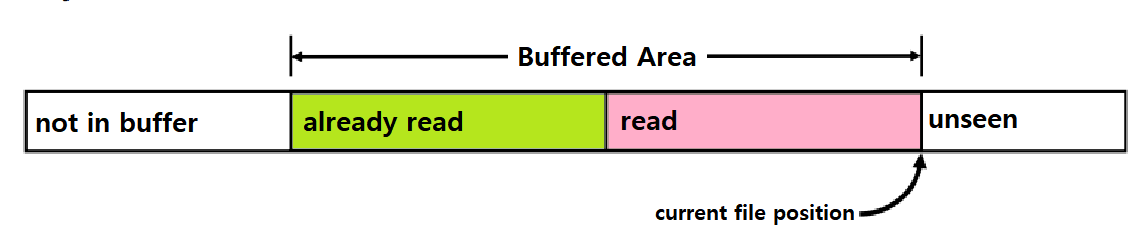
typedef struct {
int rio_fd; /* 내부 버퍼를 위한 파일 지시자 */
int rio_cnt; /* 내부 버퍼엔 들어있지만 아직 사용자가 읽지 않은 양 */
char *rio_bufptr; /* 내부 버퍼엔 들어있지만 아직 사용자가 읽지 않은 구간의 시작 */
char rio_buf[RIO_BUFSIZE]; /* 내부 버퍼 */
} rio_t;~> 이러한 구조체 자료형을 가지고, 아래와 그림과 같은 원리로 Buffered I/O를 구현한다.

아래의 예시 코드를 보자.
int main(int argc, char **argv) {
int n;
rio_t rio;
char buf[MAXLINE];
Rio_readinitb(&rio, STDIN_FILENO); // Buffered를 사용하기 위한 준비
while((n = Rio_readlineb(&rio, buf, MAXLINE)) != 0)
Rio_writen(STDOUT_FILENO, buf, n);
return 0;
}~> Buffered 방식이기 때문에 앞서 한 문자 씩 read-write하던 코드보다 훨씬 효율적인 I/O가 가능하다.
File Metadata
Database System이나 Software Engineering을 공부해본 이들은 Metadata의 의미를 익히 알고 있을 것이다. 그렇다. 'Data about data'이다.
-
SP 맥락에서 Metadata는, 조금 더 의미를 좁혀 'Data about file'이라고 하자. ★
- Kernel에 들어있다.
- stat이나 fstat System Call을 통해 OS 커널에게서 Metadata 정보를 받을 수 있다.
- 이는, 앞서 말했듯, Unix I/O로만 접할 수 있는 정보로, 이것이 바로 Unix I/O가 여전히 의미가 있는 이유이다. ★★★
-
stat과 fstat 함수는 아래와 같은 정보들을 알려준다.
struct stat {
dev_t st_dev; /* Device */
ino_t st_ino; /* inode */
mode_t st_mode; /* Protection and file type */
nlink_t st_nlink; /* Number of hard links */
uid_t st_uid; /* User ID of owner */
gid_t st_gid; /* Group ID of owner */
dev_t st_rdev; /* Device type (if inode device) */
off_t st_size; /* Total size, in bytes */
unsigned long st_blksize; /* Blocksize for filesystem I/O */
unsigned long st_blocks; /* Number of blocks allocated */
time_t st_atime; /* Time of last access */
time_t st_mtime; /* Time of last modification */
time_t st_ctime; /* Time of last change */
};~> 당연히, 외울 필요 없다. 아래와 같이 사용할 수 있다는 것을 음미하면 된다.
int main (int argc, char **argv) {
struct stat stat;
char *type, *readok;
Stat(argv[1], &stat);
if (S_ISREG(stat.st_mode)) /* Determine file type */
type = "regular";
else if (S_ISDIR(stat.st_mode))
type = "directory";
else
type = "other";
if ((stat.st_mode & S_IRUSR)) /* Check read access */
readok = "yes";
else
readok = "no";
printf("Type: %s, Read: %s\n", type, readok);
return 0;
}(쉘에서 다음과 같이 동작)
> ./example example.c
type: regular, read: yes
(자기 자신의 소스 코드 파일에 대한 stat)
> chmod 000 example.c
> ./example example.c
type: regular, read: no
(권한을 000으로 변경 후 stat)
> ./example ..
type: directory, read: yes
(상위 디렉토리에 대한 stat)
=> 위와 같이, stat 함수 호출 후, struct stat이라는 구조체 Type으로 멤버변수에 접근하여 파일에 대한 각종 정보를 확인할 수 있음을 기억하자.
금일 포스팅은 여기까지 하겠다.
