지난 포스팅에서 Semaphore에 대해 알아보았다. Semaphore란, 0 이상의 값을 가지고, P와 V라는 연산에 의해 조작되는 전역 변수라고 했다. 이때, 초기 Mutex 값이 1이면 Binary Semaphore, 1보다 큰 값이면 Counting Semaphore인 것이다.
Semaphore의 초기화 값은 Critical Section에 동시에 들어갈 수 있는 Thread의 개수를 의미한다.
즉, Counting Semaphore의 경우, 복수의 Threads가 동시에 Critical Section을 점유할 수 있는 것이다. ★
우리가 지난 포스팅에서 중점적으로 다룬 내용은 'Binary Semaphore'로, 아래의 그림을 통해 복습해보도록 하자.
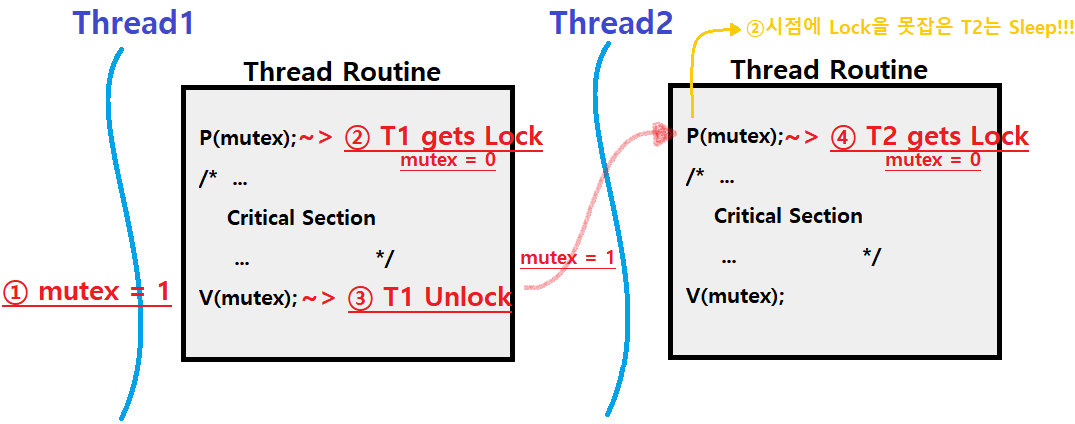
~> T1이 먼저 Lock을 잡아 Mutex가 0이 되고, P연산을 호출한 T2는 Mutex가 0이 된 것을 확인하면 Wait하게 된다. Mutex에서 T2가 기다리고 있고, T1이 Critical Section 수행을 마치고 V연산을 호출해 Return 및 Unlock하게 되면, 자고 있던 T2가 재실행되고, T2가 Lock을 잡아 Mutually Exclusive하게 일을 할 수 있게 된다. ★★
금일 포스팅도 Semaphore에 대해 다룰 것이다. 다만, 지난 포스팅보다 더욱 더 깊게 파고들겠다. 집중하자.
Shared Resources Coordination
Semaphore 기법을 이용해 'Shared Resources(Data Structure)'에 대한 Access를 조정할 수 있다.
Mutex를 이용해 Resource에 대한 Access를 보호할 수 있다.
이러한 '세마포를 이용한 공유 자료구조 조정' 기법에는 대표적으로 두 가지 모델이 존재한다. 하나는 '생산자-소비자 문제'이며, 다른 하나는 '독자-저자 문제'이다. 이들에 대해 알아보자.
Producer-Consumer Problem
-
생산자(Producer)와 소비자(Consumer)가 모두 여럿 있는 상황을 생각해보자. 생산자는 Item을 생산하고, 소비자는 당연스럽게 Item을 소비한다.
-
생산자는 Shared Resource에 Item을 쌓아둔다.
- 이 Shared Resource를 따로 'Shared Buffer'라고 하자.
- Buffer는 여러 Slot으로 이루어져 있다.
- 또한, front와 rear라는 포인터를 두고 있다. 이들을 통해 이 자료구조에 접근할 수 있다.
- Deque 자료구조를 생각하면 쉬울 듯 하다.
- 이 Shared Resource를 따로 'Shared Buffer'라고 하자.
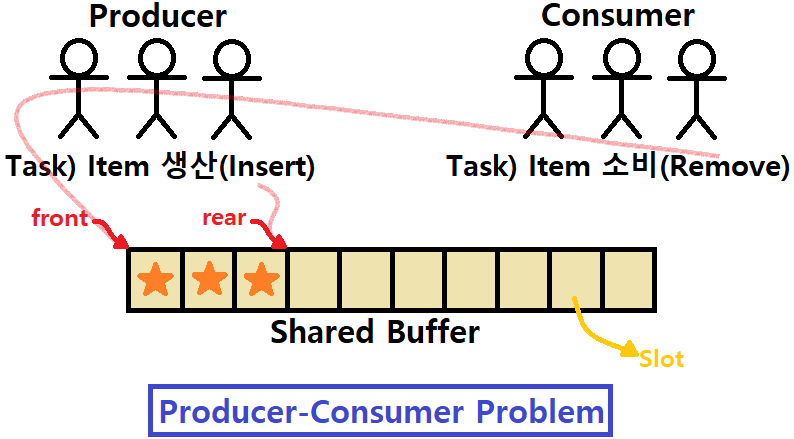
- Producer는 자료구조에 Item Insert를, Consumer는 자료구조의 Item Remove를 수행한다.
- Insert를 하면 rear 포인터가 한 칸 다음으로 가고,
- Remove를 하면 front 포인터가 한 칸 다음으로 간다.
- 생산자가 생산을 두 번, 소비자가 소비를 두 번 하면 아래의 그림처럼 변화한다.
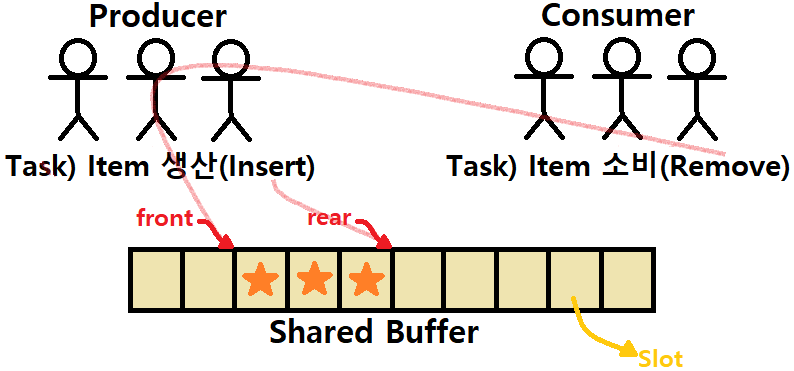
이러한 'Producer-Consumer Problem' 모델은 Shared Resources에 Concurrency를 구축할 때 사용하는 Classic한 구조이다. 여기에 Semaphore 기법을 적용해 Coordination하는 것이다.
-
Shared Buffer가 비어있다고 해보자. Empty Buffer이다. 이때는, Consumer는 소비할 수 있는 Item이 없다.
- 따라서, 이때는 Consumer는 Sleep(Blocked)한다.
-
Producer 입장에서는 만약 Consumer가 아무런 소비도 하지 않고 있으면 계속 생산을 한다. Buffer가 꽉차면, 그제서야 Producer는 Sleep한다.
-
이 전체적인 과정에서, Producer-Consumer Problem은 Semaphore를 사용한다. Empty Slot이 있으면 Producer는 생산하고, Item이 있으면 Consumer는 Consume하고, .. 이러면서 말이다.
이러한 'Producer-Consumer Problem' 구조는 'Common Synchronization Pattern'으로,
Producer는 Empty Slot이 생길 때마다 Buffer에 Item을 넣고, Consumer에게 이를 Notify한다.
Consumer는 Item을 Buffer에서 Remove하며, 이를 Producer에게 Notify한다.Producer와 Consumer가 Semaphore를 이용해, 서로가 서로에게 Notify한다!!!
- 이 기법은 Backend에서 적용하는 주요한 테크닉 중 하나이다. 아래와 같은 실제 적용 예시를 보며 이해해보자
Real-World Application
이러한 'Producer-Consumer Problem'은 어떤 상황에서 사용하는 개념일까? 아래의 예시를 통해 이를 설명하겠다. 이 개념을 배우는 이유에 대해 생각해볼 수 있을 것이다.
-
Google의 데이터 센터가 있다고 하자. 데이터 센터 안에는 수많은 컴퓨터가 있고, 이들이 굉장히 빠른 네트워크를 통해 연결되어 있다.
- 병렬 시스템, 병렬 서버이다.
- 수많은 Disk를 이용해 데이터를 저장한다.
- 병렬 시스템, 병렬 서버이다.
-
이러한 데이터 센터가 여러 지역에 흩어져 있다. California, Newyork, Chicago, Seoul, Tokyo 등에 흩어져 있다고 해보자.
-
Newyork에 있는 데이터 센터에 있는 데이터와, Seoul에 있는 데이터 센터에 있는 데이터를 분석하다고 해보자. 우선, 가장 기본적으로 해야할 일은 'Data Migration'이다. 데이터를 통합해야하는 것이다. 그래야 분석을 하든 말든 할 것이지 않은가?
-
'Data Migration'을 위해 데이터 이동이 필요하다. 이를 '빠르게' 수행해야할 것이다.
- 이때, 데이터 이동을 위해 필요한 것은 당연히 Network이다.
-
데이터를 빠르게 공유하기 위해선 특정한 System Software Framework가 필요하다. Disk를 Source라고 하고, 컴퓨터에서 데이터를 보내는 부분을 Sink라고 하자(싱크대에서 물이 개수되어 모이는 것에서 Reference한 용어이다). 아래의 그림을 보자.
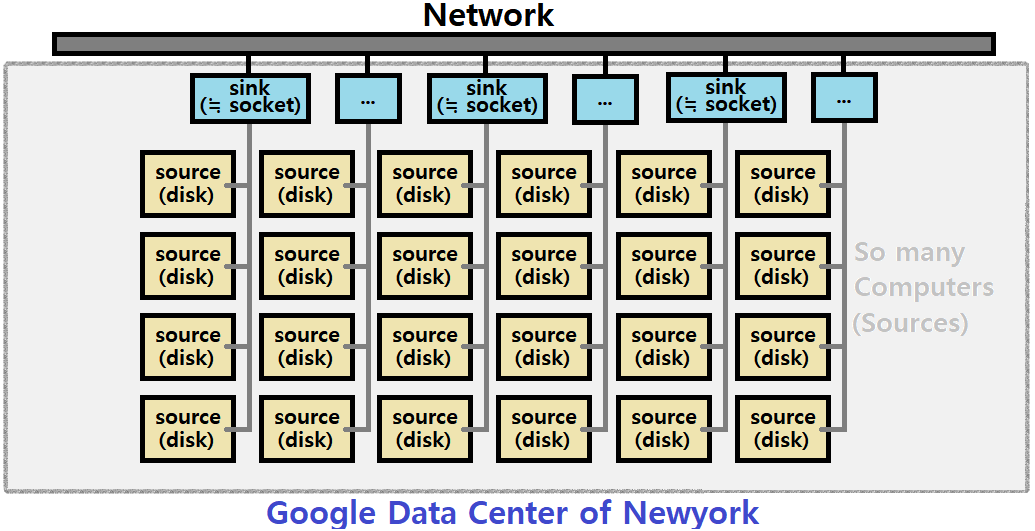
- 각 컴퓨터에서는 Source(Disk)에서 데이터를 마구마구 뽑아내어 DRAM의 Shared Buffer에 삽입한다. 여러 Thread를 띄워서 마구잡이로 데이터를 뽑아내서 올린다.
- Shared Buffer의 데이터를 Endpoint Socket에 보낸다.
- Disk에서 데이터를 뽑아내는 Thread가 있는 반면, Buffer의 Data를 Socket으로 보내는 역할을 하는 Thread도 있다.
- Shared Buffer의 데이터를 Endpoint Socket에 보낸다.
그렇다. 데이터를 뽑아내서 Buffer에 넣는 Thread가 Producer, Buffer의 데이터를 Socket으로 보내는 Thread가 Consumer, Buffer가 Shared Buffer인 것이다.
즉, 이러한 데이터 센터(의 구성 컴퓨터 및 구조) 구축에 있어서 'Producer-Consumer Problem'이 적용되고 있는 것이다.

- 이밖에도 Multimedia Processing, Graphical User Interface 구축에도 이 '생산자-소비자 문제' 개념이 유용하게 쓰인다.
- Multimedia Processing : Producer는 MPEG Video Frame을 생성하고, Consumer는 이를 Rendering한다.
- Event-Driven GUI : Producer는 마우스 클릭, 마우스 움직임, 키보드 입력 등을 모조리 Buffer에 집어넣고, Consumer가 이를 Retrieve하여, 대응되는 결과를 Display에 출력(Paint)한다.
N-Element Buffer with 'sbuf'
Mutex와 두 개의 Counting Semaphore를 이용하여 우리는 '(Shared) N-Element Buffer'를 구축할 수 있다. (총 3개의 Semaphore가 등장)
-
Mutex : Shared Buffer에 대한 Mutually Exclusive Access를 제공하는 Binary Semaphore이다.
-
Slots : Shared Buffer에 있는 Available Slot의 개수를 세는 Counting Semaphore이다.
-
Items : Shared Buffer에 있는 Available Item의 개수를 세는 Counting Semaphore이다.
~> 본 포스팅의 참조 교재에서는 sbuf라는 Package를 제공하여 이를 구현하고 있다.
주석을 매우 자세히 읽어라. 주석에 모든 설명과 복기 내용이 담겨 있다. 아주 좋은 학습이 될 것이다.
typedef struct {
int *buf; // Buffer 배열
int n; // slot의 최대 개수
int front; // buf[(front+1)%n], 즉, 첫 번째 Item을 가리킨다.
int rear; // buf[rear%n], 즉, 마지막 Item을 가리킨다.
sem_t mutex; // Buffer에 대한 상호 배타적 접근을 제공한다.
sem_t slots; // 접근 가능한 Slot의 개수를 센다. (for Notify)
sem_t items; // 접근 가능한 Item의 개수를 센다. (for Notify)
} sbuf_t;
void sbuf_init(sbuf_t *sp, int n); // Shared Buffer Initialization
void sbuf_deinit(sbuf_t *sp); // Shared Buffer Clear
void sbuf_insert(sbuf_t *sp, int item); // Buffer Insertion (Produce)
int sbuf_remove(sbuf_t *sp); // Buffer Removement (Consume)
/* n개의 Slot을 지닐 수 있는 Empty, Bounded, Shared FIFO Buffer를 생성한다. */
void sbuf_init(sbuf_t *sp, int n) {
sp->buf = Calloc(n, sizeof(int)); // Buffer를 동적할당하여 생성한다.
sp->n = n; // 최대 n개의 slot을 가질 수 있다.
sp->front = sp->rear = 0; // 처음엔 비어있다.
Sem_init(&sp->mutex, 0, 1); // Locking을 위한 Binary Semaphore 초기화
Sem_init(&sp->slots, 0, n); // Buffer는 최초에 n개의 Empty Slot을 가짐.
Sem_init(&sp->items, 0, 0); // 따라서, Buffer는 최초에 0개의 Item 접근 가능
}
// 각 Semaphore의 초기화 값을 매우매우 강조한다.
// Available Slots가 처음에는 Buffer Size만큼 있을테니 slots를 n으로 초기화
// Slot만 있으므로 Item은 없다는 소리고, 따라서 items는 0으로 초기화 ★★★
/* Shared Buffer를 Clear하는 함수 */
void sbuf_deinit(sbuf_t *sp) { // Buffer Freeing
Free(sp->buf); // 그냥 Header만 날린다.
}
/* rear Pointer가 가리키는 Shared Buffer 위치에 Item을 삽입하는 함수 */
void sbuf_insert(sbuf_t *sp, int item) {
P(&sp->slots); // Available Slot을 기다린다. ★★
P(&sp->mutex); // Lock을 잡는다. (for Mutual Exclusion)
sp->buf[(++(sp->rear))%(sp->n)] = item; // Item Insertion (Produce)
V(&sp->mutex); // Lock을 푼다. (다른 Thread에게 기회를!)
V(&sp->items); // Available Item이 생겼음을 Notify! ★★
}
// Insert할 때는, slots 변수에 대한 P연산을 통해 Slot의 개수를 확인한다.
// n을 Decrement한다. 즉, n개의 Slot이 다 존재하면, Block된다. ★
// 한편, Item Insertion 시, 여러 Thread가 혼재되면 Synchronization Error가
// 발생할 수 있으므로, Producer의 직렬화를 위해 Mutex Lock을 P와 V로 잡아준다.
// Item Produce가 완료되면, Item Semaphore를 Increment한다. (Notify) ★
/* Shared Buffer의 front에 있는 Item을 Remove하고 Return하는 함수 */
int sbuf_remove(sbuf_t *sp) {
int item;
P(&sp->items); // Available Item을 기다린다. ★★
P(&sp->mutex); // 역시나, Consumer도 직렬화해야한다.
item = sp->buf[(++(sp->front))%(sp->n)]; // Item Removement (Consume)
V(&sp->mutex);
V(&sp->slots); // Available Slot이 생겼음을 Notify! ★★
return item;
}
// Item 개수를 세는 Semaphore Value가 0이 아닐 때에 이 함수를 수행할 수 있다.
// Available Item이 0개이면, Item이 생길 때까지 P(&sp->items);를 통해
// 대기하는 것이다.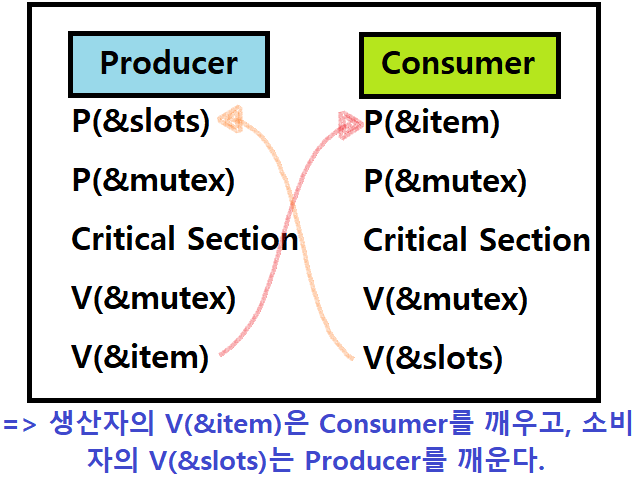
Thread-based Server Example
이러한 'Producer-Consumer Problem'을 실제 Thread Programming 시에 적용해보는 연습을 하는 것이 중요하다. 우리는 이전 포스팅에서 POSIX의 Pthread 라이브러리를 이용해 'Thread-based Concurrent Server'를 구축하는 과정에 대해 다룬 바 있다. 해당 예시에, 이번 포스팅에서 다룬 '생산자-소비자 문제'를 적용하는 방법에 대해 알아보자.
Thread-based Concurrent Server의 어느 부분에 'Producer-Consumer Problem'을 적용할 수 있을까?
기존에 소개했던 방식은, Client의 Connection Request가 올 때, 그에 대응하여 Thread를 실시간으로 띄웠었다.
우리는 바로 이 부분에 '생산자-소비자 문제'를 적용할 수 있다. 이를 'Thread Pooling'이라 한다.
-
Thread Pooling
-
Thread를 미리 만들어놓고, 현재 필요하지 않은 Thread는 Sleep시키고, 필요한 Thread만 Wake Up해서 Service 일을 시키는 것이다. ★
-
기존의 방식은, Connected Descriptor에 대해 각각 실시간으로 Thread를 띄우는 방식이었는데, Thread Pooling 방식은 여러 Thread를 미리 마련해두고, 필요한 녀석들만 뽑아서 일을 시키는 방식이다. ★
- 미리 띄워놓은 Thread를 'Worker Thread'라고 하자.
- 현재 필요하지 않으면 Sleep시킨다. ★
- 미리 띄워놓은 Thread를 'Worker Thread'라고 하자.
-
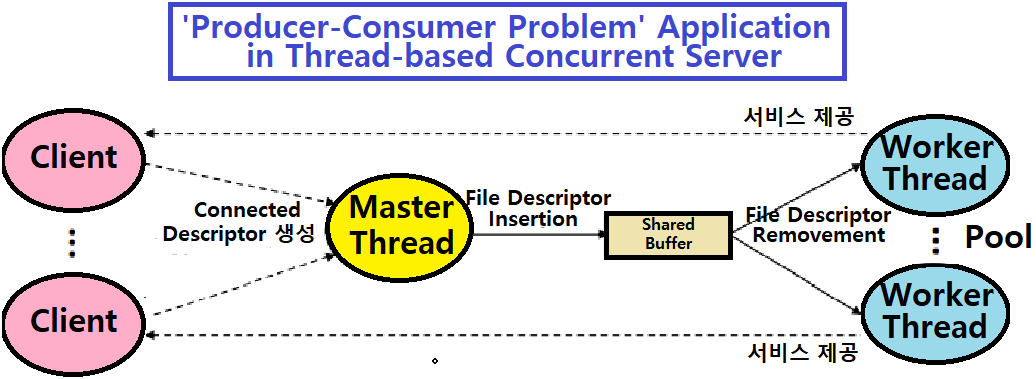
Connected Descriptor가 새로 생기면, Shared Buffer에 Item Insert를 한다.
-
새로운 Descriptor가 Buffer에 들어오면, V Operation을 이용해 Worker Thread를 하나 깨워서 일을 부여한다.
- 이를 (하나의) Master Thread가 관장한다.
- 즉, Master Thread는 Producer이다. ★
- 이를 (하나의) Master Thread가 관장한다.
-
Worker Thread는 Master Thread의 V연산에 의해 깨어난다. File Descriptor를 Shared Buffer에서 Remove하고, 그 Descriptor에 대해 Service를 제공한다.
- 이를 여러 Worker Thread가 관장한다.
- 즉, Worker Thread는 Consumer이다. ★
- 이를 여러 Worker Thread가 관장한다.
-
-
이를, 실제 Code Level에서 확인해보자. 아래의 코드는 Server의 코드이다.
/* Service Routine인 echo 함수를 위한 Variable 및 Initialization들! */
static int byte_cnt; // 읽은 바이트 개수 세는 용도
static void init_echo(void); // echo 함수 수행을 위한 초기화 함수
/* Service와 관련없는 Global Variable들 */
sbuf_t sbuf; // Connected Descriptor를 Item으로 하는 Shared Buffer
static sem_t mutex; // Mutual Exclusion을 위한 Mutex (Semaphore)
void *thread(void *vargp);
void echo(int connfd);
int main(int argc, char **argv) { // main thread가 곧 Master Thread임.
int listenfd, connfd; // 즉, main이 그 자체로서 Producer임.
socklen_t clientlen;
pthread_t tid;
struct sockaddr_storage clientaddr;
listenfd = Open_listenfd(argv[1]); // Descriptor를 받을 준비 완료!
sbuf_init(&sbuf, SBUFSIZE); // Shared Buffer 초기화 해준 다음,
for (int i = 0; i < NTHREADS; i++) // Worker Thread를 적절한 개수로 생성하고,
Pthread_create(&tid, NULL, thread, NULL); // 얘네가 Consumer 역할을 할 것!
while (1) {
clientlen = sizeof(struct sockaddr_storage);
connfd = Accept(listenfd, (SA *) &clientaddr, &clientlen); // Request 오면
sbuf_insert(&sbuf, connfd); // 반환된 Connected Descriptor를 Buffer에 삽입
}
}
void *thread(void *vargp) { // Thread Routine
Pthread_detach(pthread_self()); // Reaping Routine
while (1) {
int connfd = sbuf_remove(&sbuf); // Shared Buffer에서 Item Consume !!!
echo(connfd); // Service Routine
Close(connfd);
}
}
static void init_echo(void) { // echo 함수를 위한 함수
Sem_init(&mutex, 0, 1); // mutex 초기화해주고! (Binary Semaphore)
byte_cnt = 0;
}
void echo(int connfd) { // echo Service Routine
char buf[MAXLINE];
int n;
rio_t rio;
static pthread_once_t once = PTHREAD_ONCE_INIT;
Pthread_once(&once, init_echo); // echo 함수 초기화
Rio_readinitb(&rio, connfd);
while((n = Rio_readlineb(&rio, buf, MAXLINE)) != 0) {
P(&mutex); // Mutual Exclusion을 위한 P연산
byte_cnt += n; // 각 Thread가 Interleaving되지 않도록
printf("Thread %d received %d (%d total) bytes on fd %d\n",
(int) pthread_self(), n, byte_cnt, connfd); // printf 행잉 방지!!!
V(&mutex); // Mutual Exclusion
Rio_writen(connfd, buf, n); // 쓰는건 직렬화될 필요 x
}
} Client로부터 Connection Request가 오고, Server가 이를 받은 다음, 반환된 Connected Descriptor를 Shared Buffer에 넣는다. 누가? Master Thread가 말이다.
~> Available Slot이 하나 줄어들 것이다. = Available Item은 하나 늘어난 것
한편, Shared Buffer에 Available Item인 New File Descriptor가 생겼으므로, sbuf_remove를 호출해놓고, P(&item)에 막혀서 Sleep하고 있던 Consumer, Worker Thread는 Master Thread의 삽입 행위에서 발생하는 V(&item)에 의해 깨어난다.
깨어난 Worker Thread는 Shared Buffer에서 해당 Item(File Descriptor)를 제거하고, 드디어 서비스를 제공하게 되는 것이다. sbuf_remove의 끝에선 V(&slots)를 통해 Available Slot이 하나 늘어났음을 Notify한다.
echo Server이므로, echo Service를 제공하는데, 서비스 간에 Shared Variable을 사용할 일이 있으므로, Worker Thread들이 Synchronization Error를 일으키기 않도록, P와 V를 통해 직렬화를 제공해주는 것도 주목하자.
~> 여기까지의 개념을 약간 변형하면 우리는 실제 상용 서버에 근접한, 괜찮은 서버를 제작할 수 있다. 실제로, 본 SP 연재가 종료되면, 번외로 쉘 제작과 서버 제작 포스팅을 올릴 것인데, 서버 제작 포스팅에서 좀 더 디테일하게 소개하겠다.
=> 여기서 다룬 내용이면 충분하다.
Readers-Writers Problem
'Readers-Writers Problem'은 Mutual Exclusion Problem의 Generalization이다.
'Producer-Consumer Problem'이 Shared Buffer에 대한 이야기였다면, 'Readers-Writers Problem'은 Shared Object에 대한 이야기이다. ★
-
Shared Object가 있다.
-
Reader Thread는 오직 Object Read만 수행한다.
-
Writer Thread는 Object Modify만 수행한다.
-
Writer Thread는 Object에 Mutually Exclusive하게 Access(Write)해야한다.
-
Unlimited Reader Threads가 Object에 Access(Read)할 수 있다.
- 즉, Reader는 Mutually Exclusive할 필요가 없다.
- 왜? 얘네는 State를 바꾸질 않으니까!!!
- 즉, Reader는 Mutually Exclusive할 필요가 없다.
-
-
Real-World Application
-
Database의 Record 관리에서 적용되는 개념이다.
-
데이터베이스에서는 데이터 저장을 위해 주로 B+Tree와 같은 'Index Tree'를 도입한다. Tree의 각 노드는 데이터를 의미하며, Tree의 Update/Access 등의 기능을 지원한다.
-
데이터베이스에 A라는 데이터가 있는데, R1, R2, R3라는 Reader들은 이 정보를 읽으려 하고, W1, W2라는 Writer들은 이 정보를 쓰려고 한다. 이들이 유사한 시간대에 이 정보에 대한 일을 수행하려고 할 때, 우리는 이 A라는 'Shared Object'에 대해 'Readers-Writers Problem'을 적용해야한다. ★★
- 왜냐? Readers와 Writers가 난잡하게 Object를 접근하면, 무엇이 최신 Version인지 모호해지는 문제가 발생한다. 또한, 비정상적인 데이터 수정이 생기게 된다. ★★
-
이러한 문제의 해결을 위해, Semaphore 기법을 사용하여 Exclusion을 제공하는 것이 'Readers-Writers Problem'이다.
-
-
Paris로 여행을 가려고 항공편을 알아보고 있을 때, 나 말고도 여러 사람이 세계 각지에서 해당 좌석 항공권을 주시하고 있을 것이다. 이때도 이 기법이 필요하다. (Online Airline Reservation System)
-
Multithreaded Caching Web Proxy
-
- 'Readers-Writers Problem'은 아래와 같이 두 가지 유형으로 나뉜다.
- 그런데, 아래의 두 유형 모두에 적용되는 공통 법칙이 하나 있다.
누군가 Shared Object를 Read or Write하고 있으면, 그 행위가 끝날 때까지, Reader이든 Writer이든 기다려야한다. 당연히, 그것이 '예의(?)'이다.
- 그런데, 아래의 두 유형 모두에 적용되는 공통 법칙이 하나 있다.
First Readers-Writers Problem
Readers에게 우선권을 주는 것이 'First Readers-Writers Problem'이다.
-
Shared Object가 있을 때, R1이 이를 읽고 있다고 해보자.
-
이때, W1이 오면, 이 W1는 Wait한다.
- 누군가 읽고 있으므로, 앞서 언급한 룰에 의해 당연하다.
-
만약, 이때, R2가 온다고 해보자.
- 얘는 Writer보다 우선권이 있으므로, 그대로 바로 읽을 권한이 생긴다. (꽉차지만 않으면)
-
R3가 오면?
- 얘 역시, R2처럼, W1보다 늦게 왔음에도, W1보다 먼저 일을 하도록 권한이 부여된다.
-
Writer가 먼저 왔음에도, 이후에 온 Reader들이 먼저 일을 할 수 있게 우선권을 준다. ★
-
No reader should be kept waiting unless a writer has already been granted permission to use the object!
-
A reader that arrives after a waiting writer gets priority over the writer!
-
-
눈치 챘는가? 'Readers-Writers Problem'은 Starvation 문제가 발생할 수 있다. First에선 Writer가, 후술할 Second에선 Reader가 굶어 죽을 수 있다.
아래의 코드는 Reader에게 Priority를 부여하는, 'First Readers-Writers Problem'의 예시 코드이다. w라는 Semaphore를 만들고, w가 0이면 Reader이든 Writer이든 기다린다. 참고로, w는 Binary Semaphore이다. ★★★
/* Reader */
int readcnt; // 현재 Shared Object를 읽고 있는 Reader의 개수이다.
sem_t mutex, w; // 둘 다 초기값은 1이다.
void reader(void) { // Reader Thread Routine
while (1) {
P(&mutex); // Mutual Exclusion을 제공한다. (공유 자료구조 때문)
readcnt++; // Reader가 늘어났으므로 Increment!
if (readcnt == 1) // Reader가 하나라도 있으면, 그대로 Writer를 Block!
P(&w); // w 값을 Decrement하여, Writer를 Sleep하게 한다.★
V(&mutex); // Mutual Exclusion
/* Critical section : Reader의 Task를 작성한다. */
P(&mutex); // Mutual Exclusion for preventing Sync Error!
readcnt--; // Read를 마친 Reader는 끝날 것이므로!
if (readcnt == 0) // 만약, 이 '나가는 Reader'가 마지막 Reader라면,
V(&w); // 드디어, w를 Increment해 Writer에게 권한을 준다.
V(&mutex);
}
}
/* Writer */
void writer(void) { // Writer Thread Routine
while (1) {
P(&w); // Reader가 아예 없으면 Writer가 여럿일 수 있다.
// Writer끼리도, 당연히 Mutually Exclusive해야한다.
/* Critical section : Writer의 Task를 작성한다. */
V(&w); // 여럿일 경우, P와 V로 직렬화를 제공해준다. ★
}
}~> 아주 기본적인 'First Readers-Writers Problem' 구현 코드이다. 이 코드에는 Writer에게 발생할 수 있는 Starvation 문제에 대한 해결책이 존재하지 않는다.
=> 연속으로 Object에 접근할 수 있는 Readers의 수에 Threshold를 두어 처리하는 방법이 있을 수 있다. (Starvation에 대한 해결책. 현재 코드에 동시 접근 가능 Reader의 개수에 제한이 없다.)
--> 예를 들어, Reader가 연속으로 10번 접근하면, 1번은 Writer도 일을 할 수 있도록 배려해주는 것이다. ★
Second Readers-Writers Problem
Writers에게 우선권을 주는 것이 'Second Readers-Writers Problem'이다.
-
위의 예시에서, R2, R3를 기다리게 하고, W1이 이들보다 먼저 일을 하도록 권한을 부여하는 방식이다.
- Reader가 먼저 오든 말든, Writer가 기다리고 있으면, Writer에게 우선권을 준다. ★
-
Once a writer is ready to write, it performs its write as soon as possible!
-
A reader that arrives after a writer must wait, even if the writer is also waiting!
'Second Readers-Writers Problem'에 대한 코드는 제공하지 않겠다. 너무 쉽기 때문이다. 그냥 위의 코드에서 Reader를 Writer로 바꾸고, Writer를 Reader로 바꿔주면 된다. 대신 Context에 알맞게 변수명도 적절히 바꿔주는 센스가 있어야할 것이다.
금일 포스팅은 여기까지이다.
