현재 소켓 통신망을 구축해 그림 생성을 요청받은 Spring 서버와 FastApi 서버의 통신을 사용하고 있다.
하나의 서버의 version이 바뀌거나 하나의 서버라도 down 된다면 해당 소켓 통신을 유실되고 밀려있던 모든 일기의 내용이 유실되는 문제점이 존재했다.
무엇보다 Spring Server 에서 보낸 요청이 응답까지 최소 3분에서는 최대는 3시간.. 3일 늘어날수 있기에 중요한 부분이다.
따라서 아래의 그림과 같은 Kafka를 구축하여 안정적인 통신을 구축하고자 한다.
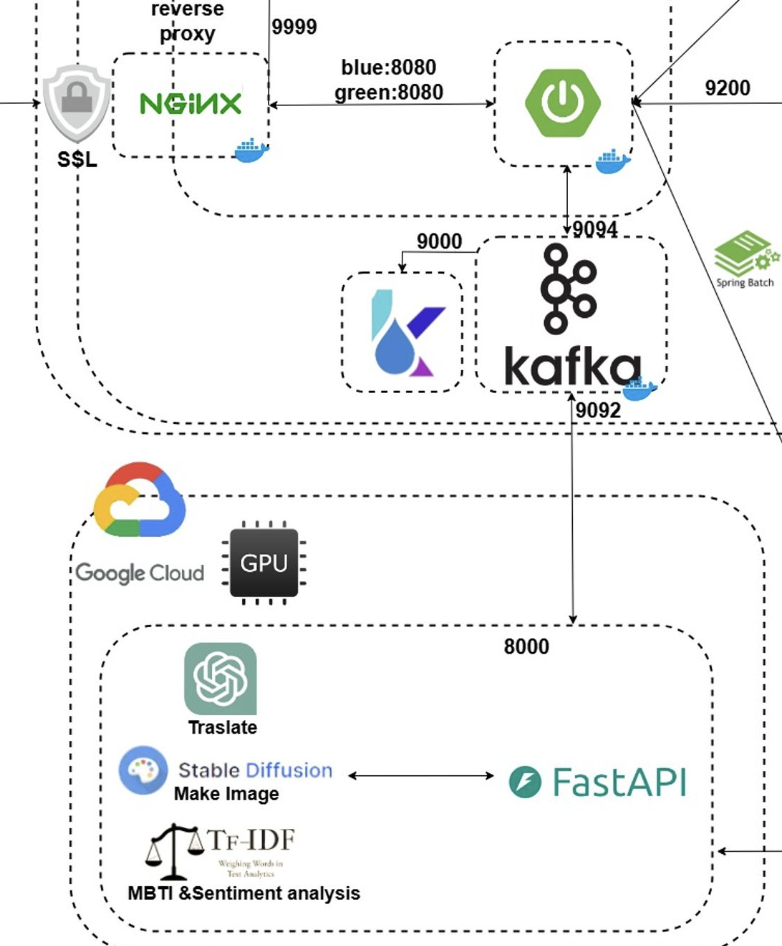
구축 이전 Kafka의 학습을 먼저 진행하려고 한다.
Kafka는 애플리케이션 즉 서버간의 결합도를 줄이고, 탈 중앙화를 위해 등장했다.
즉 두개의 서버 가운대에 Kafka가 존재하고, 메세지(데이터)를 보내는 쪽이 프로듀서, 메세지(데이터)를 받는 쪽이 컨슈머가 된다.
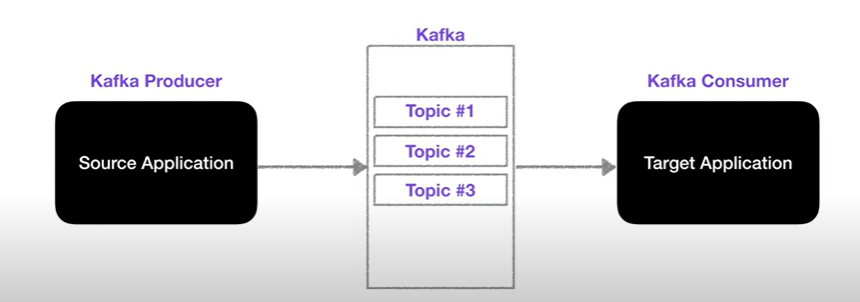
프로듀서가 카프카의 토픽에 정보를 올려놓고, 컨슈머는 구독한 토픽에서 찾아간다.
하나의 토픽은 쉽게 큐로 이뤄져 있고, Producer → Consumer 방향으로 이해하면 쉽다.
파편화를 줄이고 중앙의 하나의 카프카가 모든 스트림을 구성해준다.
- 데이터가 많다면 컨슈머를 늘려서 속도를 향상시킬수 있다
- 래플리카가 가능하다
- 데이터를 컨슈머가 가져가도 데이터가 남아있다
스타트업은 성장속도가 빠르기 때문에 손쉽게 스케일 아웃이 가능한 (브로커의 갯수를 증가) 해서 사용이 가능하다. -> 확장성 측면에서도 아주 유용하다.
Kafka 용어에 대해서 한개씩 알아보자
- 토픽
하나의 중앙 저장소인 Kafka에 여러개의 토픽을 생성할수 있다.
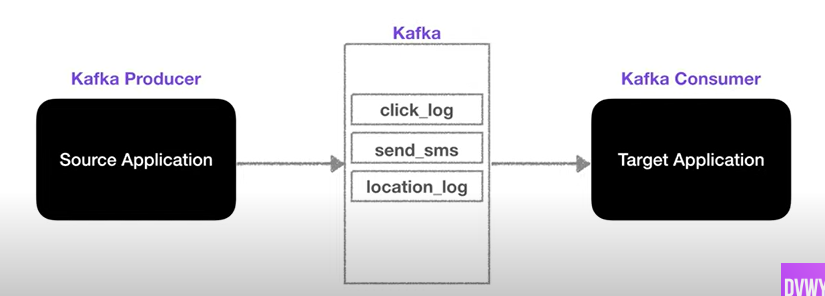
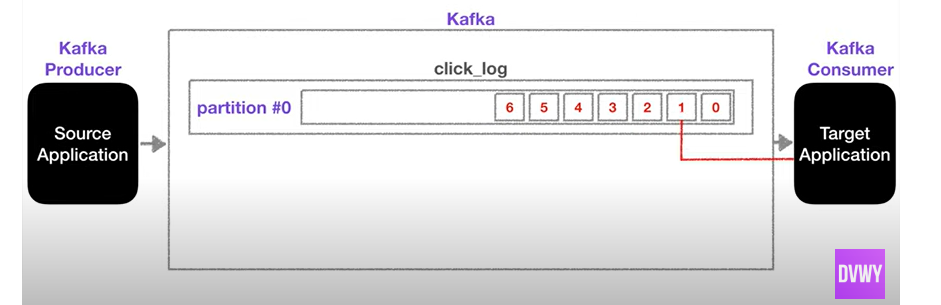
카프카의 프로듀서가 토픽에 데이터를 추가하고, 컨슈머는 오래된 데이터 순서대로 가져간다.
이때 ! offset을 활용해 중복 데이터를 방지하고, 무엇보다 데이터를 토픽 내부에 두고 내용만 가져간다 !

외부 그룹이 해당 토픽에 접근하면 같은 처리를 그대로 사용할수 있다 -> 하나의 토픽에 여러 개의 컨슈머가 가능
auto.offset.reset = earliest 의 설정이 필요하다.
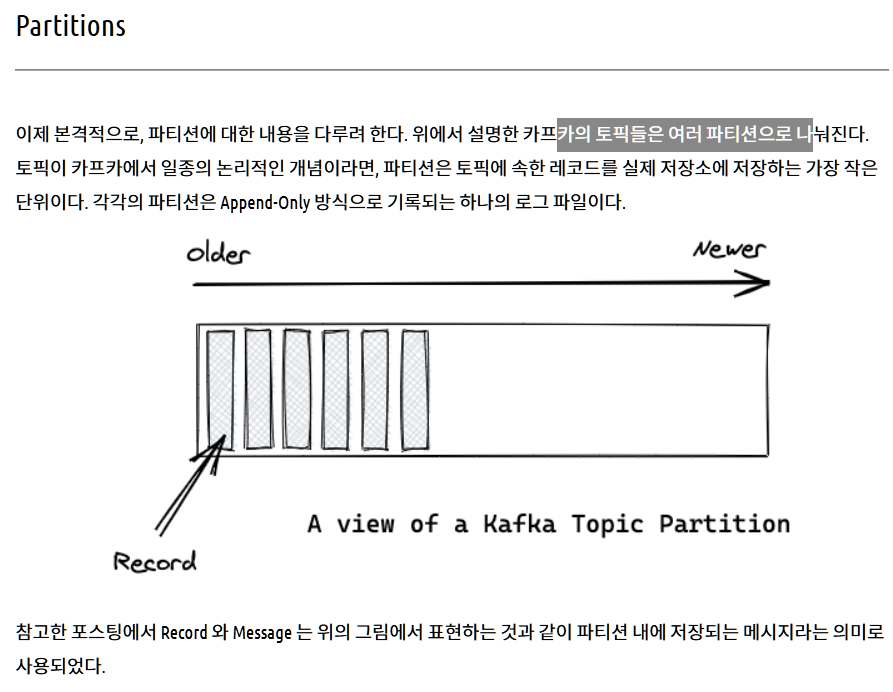
하나의 토픽 안에 여러개의 파티션이 생성되는 방향이다
기본 파티션 설정은 라운드 로빈으로 파티션의 갯수만큼 돌아가면서 write 하게된다
해시로 지정해서 write 할수도 있다 !
파티션의 갯수를 늘리는 이유 → 컨슈머의 분산처리를 위해서이다 !

- 프로듀서
데이터를 Kafka에 보내는 역할을 한다.
- Topic에 해당하는 메시지 생성
- 특정 Topic으로 데이터를 publish
- 처리 실패/재시도
- 컨슈머
다른 메시징 시스템과 달리 큐에서 데이터를 가져가게 되도
큐에는 데이터들이 남아있다, 기본적으로 카프카의 토픽 데이터를 가져온다.
이를 polling이라고 한다.
- Topic의 partition으로 부터 데이터 polling
- Partition offset 위치 기록(commit)
- Consumer group을 통해 병렬처리
컨슈머 그룹에선 1개 이상의
- Lag
프로듀서와 컨슈머 사이에 데이터의 무결성을 보장하기 위한 Offset이 존재한다.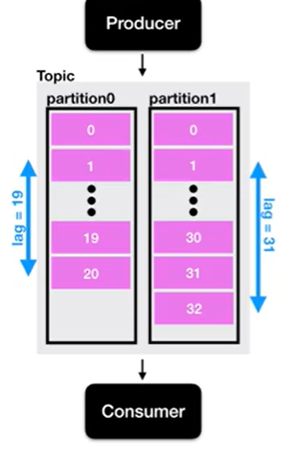
즉 Lag란 :
프로듀서 offset과 컨슈머 offset의 차이이다 !
lag는 여러개 존재할수 있다 !
만약 write 보다 read가 빠르다면 데이터를 계속 안읽어오는 경우가 발생할수 있기에 Lag를 두는게 좋다 ! ! !
Lag를 바탕으로 데이터의 무결성을 보장할수 있는 것이다.
- 참고
Dev 원영
