이전 포스팅
이전에 공유 자원에 대한 동시성을 처리하며, 기존의 값을 조회해온뒤 + 5 해서 Update 플로우를 진행했었다.
최근 한 블로그를 보면서 내가 생각하지 못했던 로직에 대해서 직접 다뤄보려고 한다.
조회수 기능 구현 (동시성 이슈)
공유자원의 문제를 생각하기 이전에

"기존 값 + 5" 라는 "Update" 종이를 들고 위 사진과 같이 사람들이 줄서있다고 생각해보자.
이전의 select 이후 update는 "Select" 종이를 먼저 제출하고 다시 맨 뒤에 줄을서 "Update" 종이를 들고 줄을 서있었기 때문에 매표소에서는 해당 자원의 무결성을 보장할수 없었다.
매표소에서 "Update" 종이만 허가한다면 공유 자원의 문제점이 없을 뿐 더러, 줄을 더 빠르게 소진시킬수 있다.
또한, 이는 "Update", "Select" 종이를 들고있는 사람은 중복될수 없음을 보장하기도 한다.(다른 트랜잭션에서 실행되기 때문)
따라서 해당 로직을 작성해보려고 한다.
기존 프로젝트에 board 도메인을 추가한다.
Controller
import lombok.RequiredArgsConstructor;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController()
@RequestMapping("board")
@RequiredArgsConstructor
public class BoardController {
private final BoardService boardService;
@GetMapping()
public Integer plusViews() {
return boardService.plusViews(1L);
}
@GetMapping("/{id}")
public Integer getViews(@PathVariable Long id) {
return boardService.getViews(id);
}
}
Service
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
@Service
@RequiredArgsConstructor
@Transactional
public class BoardService {
private final BoardRepository boardRepository;
public Integer plusViews(Long id) {
return boardRepository.plusBoardView(id);
}
public Integer getViews(Long id) {
return boardRepository.findBoardById(id).getViews();
}
}
Repository
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Modifying;
import org.springframework.data.jpa.repository.Query;
public interface BoardRepository extends JpaRepository<Board, Long> {
@Modifying
@Query("update Board b set b.views = b.views + 5 where b.id = :id")
Integer plusBoardView(Long id);
Board findBoardById (Long id);
}
테스트를 위해 Controller 에서 임시로 만들어져 있는 컬럼 id=1 을 이용해서 사용한다.
이후 Jmeter를 활용하여 한번에 1000개의 request를 보내보겠다.
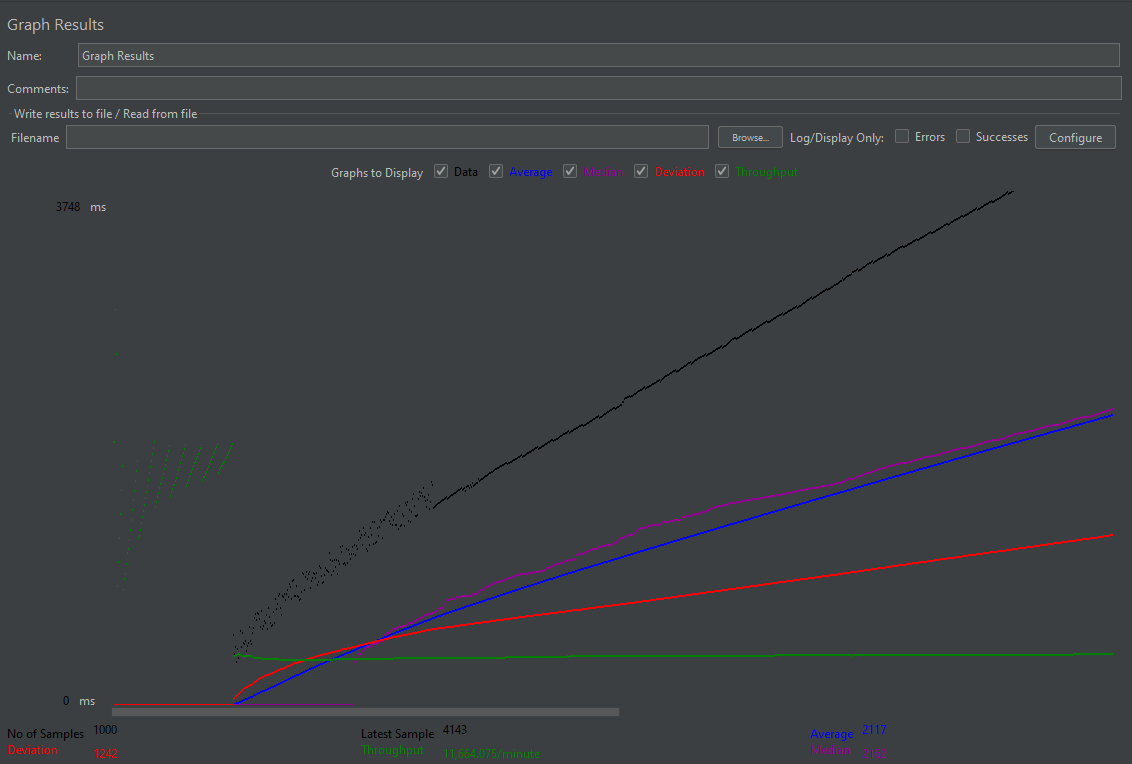
"Update(n + 5)" 종이 5000장을 보낸 셈이다.
일전의 분산락이나 비관 낙관 락을 사용할때 보다 훨신 더 빠른 효율을 확인할 수 있다.
또한 해당 방법은 DB로 request를 여러 서버에서 보내도 하나의 DB에서 처리 되기 때문에 서버 증설의 문제점도 없다. (메모리에 부하만 일어나지 않는다면...)
DB의 트랜잭션 시스템을 통해서 request들이 관리되며 순차적으로 요청을 처리한다.
- Redis write
그렇다면 위와 비슷한 방법으로 wirte 로직을 DB에 직접 쓰는게 아닌 인메모리 단계에 존재하는 Redis를 활용한다면 ?
client -> Server : wirte (Update) 로직을 Redis에서 관리하고
특정 시간이나 trigger에 실제 DB와 동기화 하도록 설계한다면 ?
client는 Read 로직에서 DB를 바라보도록 설정하여 value 조회가 가능하다.
Controller 는 위와 같다.
Service
@Service
@RequiredArgsConstructor
@Transactional
public class BoardService {
private final BoardRepository boardRepository;
private final RedisTemplate<String, Long> redisTemplate;
// public Integer plusViews(Long id, Long views) { return boardRepository.plusBoardViews(id); }
public Integer plusViews(Long id) {
String redisKey = FEED_VIEW_COUNT_PREFIX + id;
Long increment = redisTemplate.opsForValue().increment(redisKey, 5L);
if(increment == null) return 0;
return increment.intValue();
}
public Integer getViews(Long id) {
return boardRepository.findBoardById(id).getViews();
}
}위 코드에서 write 발생시 Redis 저장소에 value를 증가시킨다.
스케줄러
import com.example.threadsafetest.board.BoardRepository;
import jakarta.transaction.Transactional;
import lombok.RequiredArgsConstructor;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Service;
import java.util.Optional;
import java.util.Set;
import static com.example.threadsafetest.config.redis.RedissonConfig.FEED_VIEW_COUNT_PREFIX;
@Service
@RequiredArgsConstructor
public class ScheduleService {
private final BoardRepository boardRepository;
private final RedisTemplate<String, Long> redisTemplate;
// every 1 minute
@Scheduled(cron = "0 * * * * *")
@Transactional
public void applyViewsToDb() {
Set<String> keys = redisTemplate.keys(FEED_VIEW_COUNT_PREFIX + "*");
if (keys.isEmpty()) { // redis에 존재하는 모든 조회수를 가져온다.
return;
}
// 가져온 조회수를 DB에 반영 ( redis to DB )
keys.forEach(redisKey -> {
Long boardId = Long.parseLong(redisKey.replace(FEED_VIEW_COUNT_PREFIX, ""));
long ViewsCount = Optional.ofNullable(redisTemplate.opsForValue().get(redisKey))
.orElse(0L);
if (ViewsCount > 0) { // 0 이상의 조회수가 쌓인 경우 동기화
syncViewCount(redisKey, boardId, ViewsCount);
}
});
}
// DB 접근
private void syncViewCount(String redisKey, Long boardId, long ViewsCount) {
Integer i = boardRepository.plusBoardViews(boardId, ViewsCount);// DB 호출
redisTemplate.opsForValue().set(redisKey, 0L);
}
}
매분 cron을 통한 스케줄러로 Redis에 있는 value를 DB에 Update 해준다.
Repository
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Modifying;
import org.springframework.data.jpa.repository.Query;
public interface BoardRepository extends JpaRepository<Board, Long> {
@Modifying
@Query("update Board b set b.views = b.views + :views where b.id = :id")
Integer plusBoardViews(Long id, Long views);
Board findBoardById(Long id);
}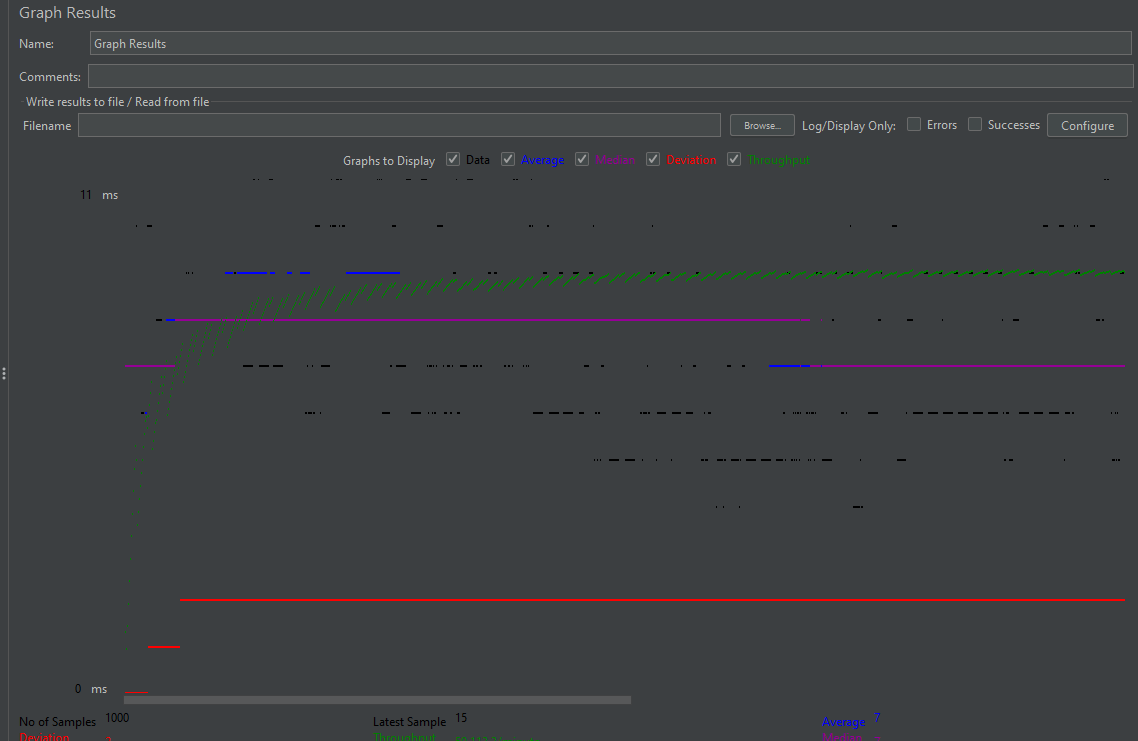
동시 1000개의 요청을 write 하는데 단 10ms 의 시간이 소요된다.
이후 스케줄러 가동을 통하여
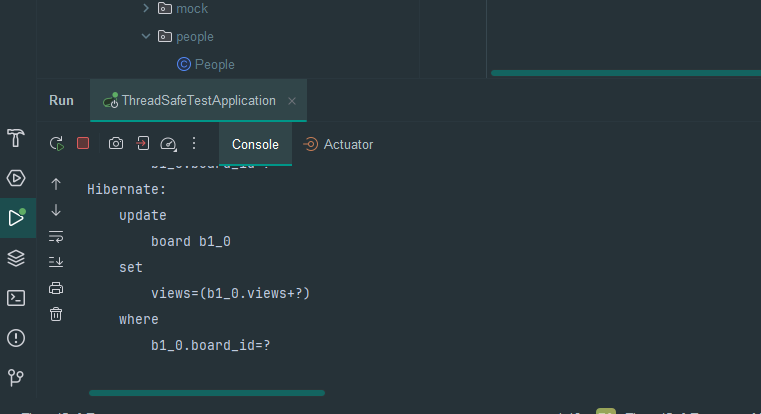
Redis 의 값을 DB와 동기화 시켜준뒤 Redis value를 다시 0으로 변경해준다.
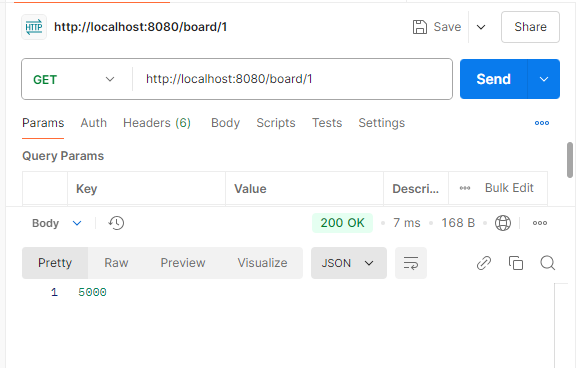
이후 조회해보면 정상적으로 5000 value가 반영 되어있는 것을 확인할 수 있다.
기존 DB에 value를 반영하는 로직과 무려 380배 성능 차이를 보인다.
이렇게 DB가 아닌 메모리에 value를 기록해두고 한꺼번에 DB에 반영한다면, 데이터 실시간성은 조금 떨어질수 있다.
하지만, 스케줄러 시간을 조정한다면,
- DB에 가는 부하를 줄임으로써 얻는 안정성
- 따로 Lock을 걸지 않아도 나타나지 않는 동시성 문제
- DB에 write를 했을때 보다 무려 380 배 빠른 성능
훨신 더 큰 trade off 가져온다는 장점이 존재한다.
