개요
최근 DDos공격으로 인해 서버가 다운이 된적이 있다.
기존 코인 다운시 memory 혹은 cpu가 과도하게 사용되는 경우가 많은데, 임계치의 자원이 사용될 경우 slack에 알림이 간 후 auto-scaling을 진행하는 방식으로 인프라 변화를 줄 필요를 느꼈다.
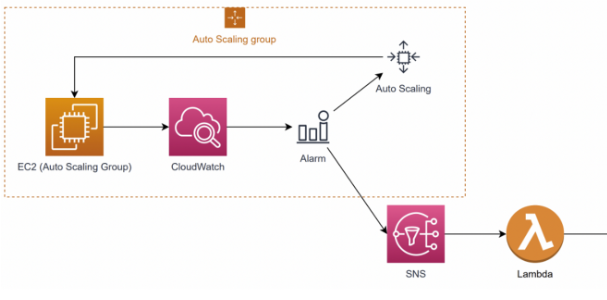
위의 그림은 구상한 방법이다.
cloudWatch 도입
cloudWatch는 AWS리소스와 AWS에서 실시간으로 실행중인 애플리케이션을 모니터링 하는 서비스이다. 지표를 감시해 알림을 보내거나 임계값을 위방한 경우 모니터링 중인 리소스를 자동으로 변경하는 경보를 생성할 수 있다.

cloudwatch에서 cpu사용량을 모니터링 가능하다.
다만 메모리 사용량은 확인 할 수 없으므로 cloudwatchAgent를 도입하였다.
cloudWatchAgent 도입
cloudWatchAgent란 AWS에서 제공하는 리소스 모니터링, 관찰 서비스인 클라우드 워치에 리소스 내부에서 나온 지표,데이터를 수집할 수 있게 해주는 것이다.
Koin은 amd64기반이므로
- amd64용(ubuntu용)CloudWatch다운로드(권한문제로 인해 sudo 붙이기)
sudo wget https://s3.amazonaws.com/amazoncloudwatch-agent/ubuntu/amd64/latest/amazon-cloudwatch-agent.deb- cloudWatch설치
sudo dpkg -i -E ./amazon-cloudwatch-agent.deb- 설정마법사에서 설정파일 생성
sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-config-wizard여기서
Which user are you planning to run agent? : 2.cwagent
로그파일 /var/log/message, /var/log/secure설정
- cloudWatchAgent 실행여부
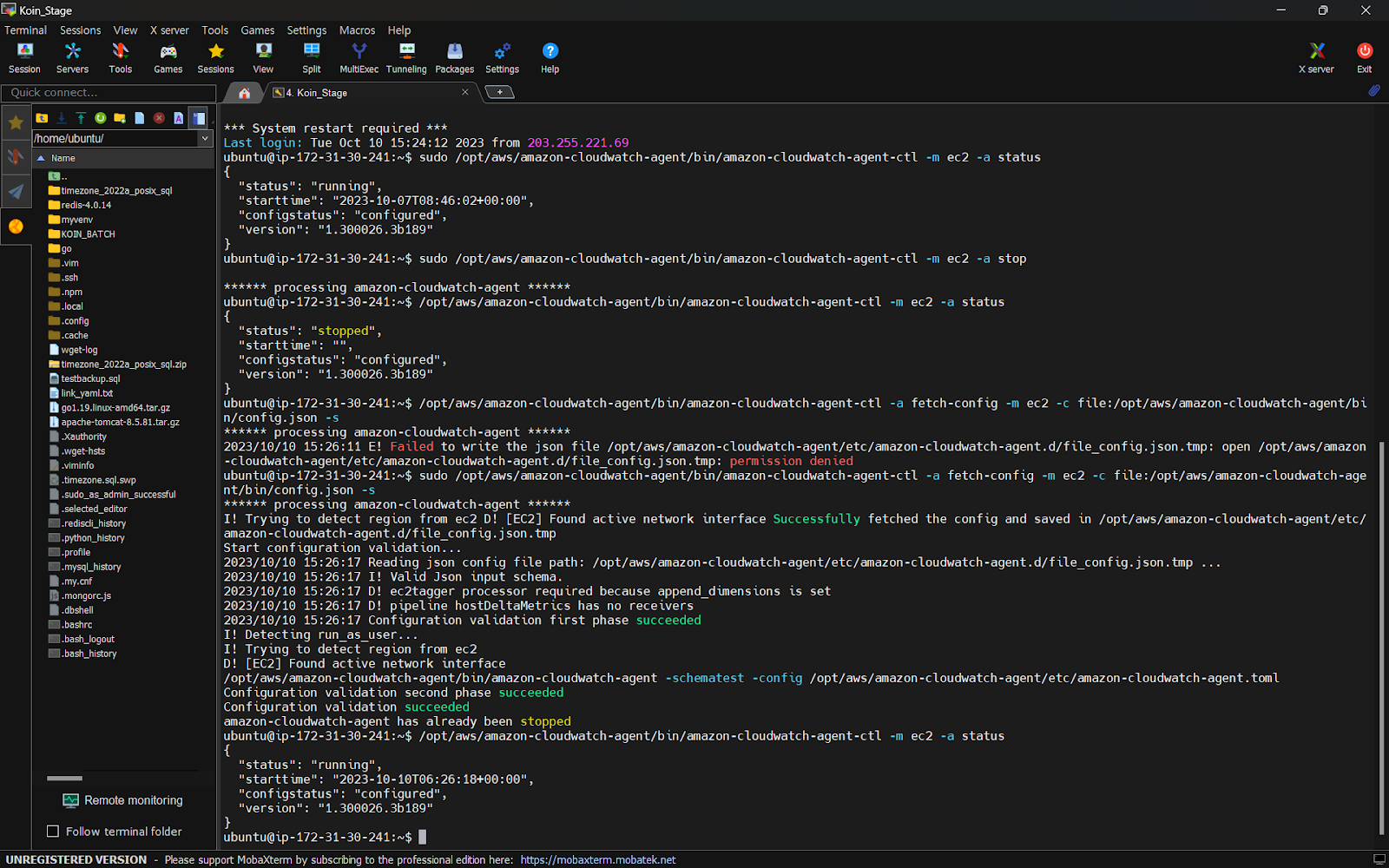
cloudWatchAgent 실행
sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -c file:/opt/aws/amazon-cloudwatch-agent/bin/config.json -scloudWatchAgent 중지
sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -m ec2 -a stopcloudWatchAgent 상태
sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -m ec2 -a status- 만약 설정 마법사에서 권한설정으로 인한 거부가 된다면
IAM을 설정하여
CloudWatchAgentServerPolicy정책을 같은 역할을 만들어주었다.
위의 설정파일에서 권한 문제가 있을 경우 ec2인스턴스에서
이러한 에러 발생하여
CloudWatchAgentAdminPolicy 권한까지 포함하였다.
만약 현재 실행중인 cloudwatchAgent를 멈추고 싶다면 아래의 명령어를 실행,
재실행을 원하면 위의 실행 명령어를 입력하면 된다.

위와 같이 메모리 사용량을 모니터링 할 수 있다.
- cloudwatchagent의 설정을 철회하고 싶다면
- IAM권한 삭제

- cloudwatchAgent중지
위의 두가지 절차를 거치고 설정파일을 삭제하면 된다.
cloudWatchAlarm
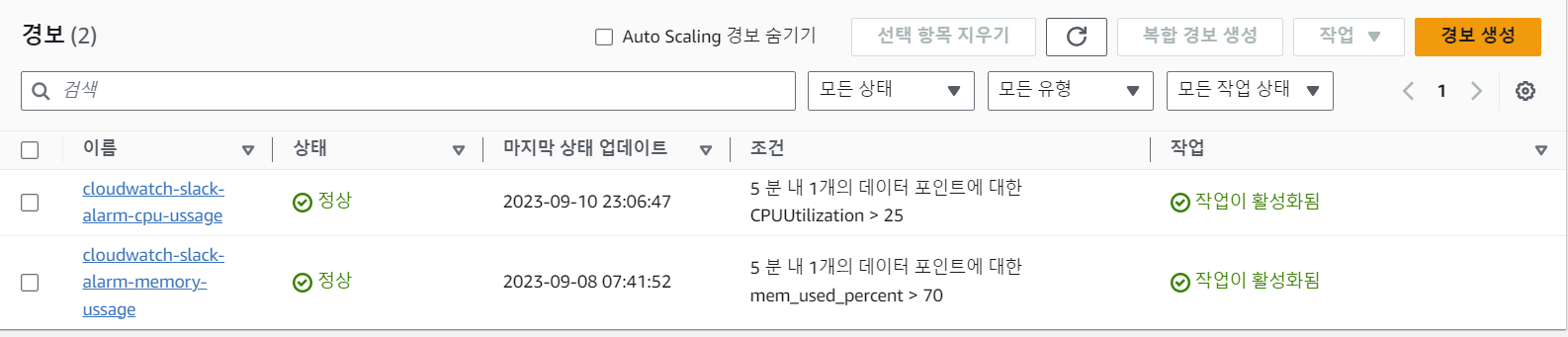
위 그림과 같이 특정 조건이 부합하면 경보가 발생한다.
(현재 cpu,memory사용량 모니터링중이다.)
경보가 발생할 경우
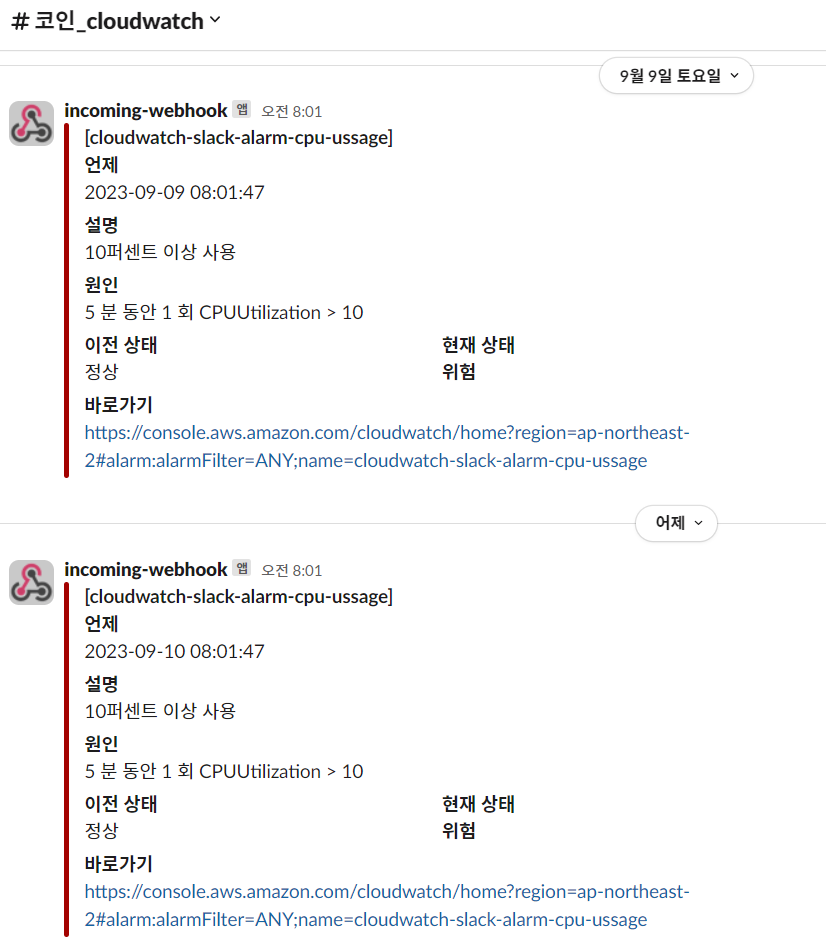
slack과 연동이 되어 알람이 간다.
AMI(Amazon Machine Image)
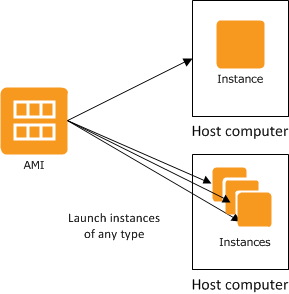
위의 그림과 같이 Amazon Machine Image에서 인스턴스를 바로 시작할 수 있는데, 이 인스턴스는 AMI의 사본으로 클라우드에서 실행되는 가상서버이다.
AMI를 이용하면 서버의 환경을 이미지화 하여 새로운 인스턴스를 바로 생성할 수 있다.
여기서 Snapshot은 각각의 EBS Volume을 백업하는 개념이고, AMI는 Root Volume을 포함하여 EC2에 연결된 모든 EBS Volume정보를 한번에 백업한다는 개념이다.
AMI를 이용한 백업
- 긴급하게 백업된 인스턴스를 복구해야 하는 경우
- 인스턴스 설정등이 복잡해서 설정이 완료된 인스턴스 이미지를 만들고 싶은 경우
- Auto Scaling Group에서 새 인스턴스를 자동으로 생성하기 위해 만드는 경우
Snapshot을 이용한 백업
- OS와 별개로 데이터만 백업하고 싶은 경우
- 생성된 스냅샷을 기반으로 여러종류의 AMI를 생성하고 싶은 경우
- Amazon DLM을 활용하여 백업을 자동화 하고 스토리지 비용 최적화를 원하는 경우
Auto-Scaling
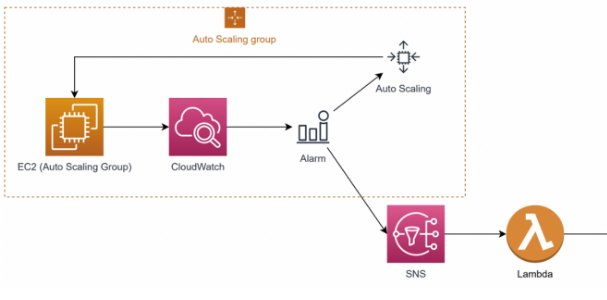
현재 KoinStage에 적용된 AutoScaling그룹의 정책을 살펴보면
- cloudwatch에서의 Cpu or Memory의 사용량이 80퍼센트 이상이 되면
- 300초간의 휴지기간을 가지고
- 1개의 t2.small서버가 scale in-out이 이루어진다.(평소1개의 t2.small유지, 최대 2개의 t2.small으로 확장)

일단 위와 같은 시작템플릿을 이용한다.(현재 KoinStage는 t2 small을 사용하고 있으므로 ver3사용)
AMI-KoinStage
instance-t2.small
keyPair-KoinStage
templateVer-ver3
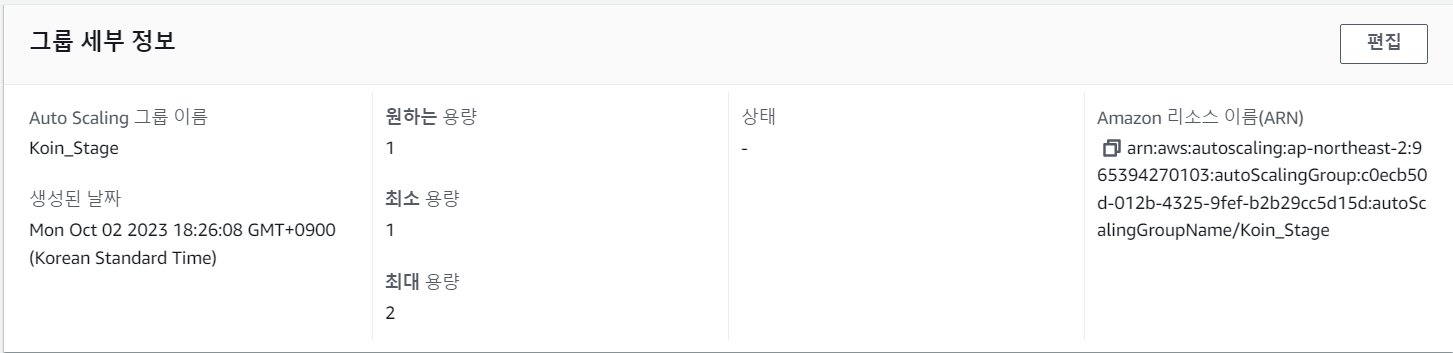
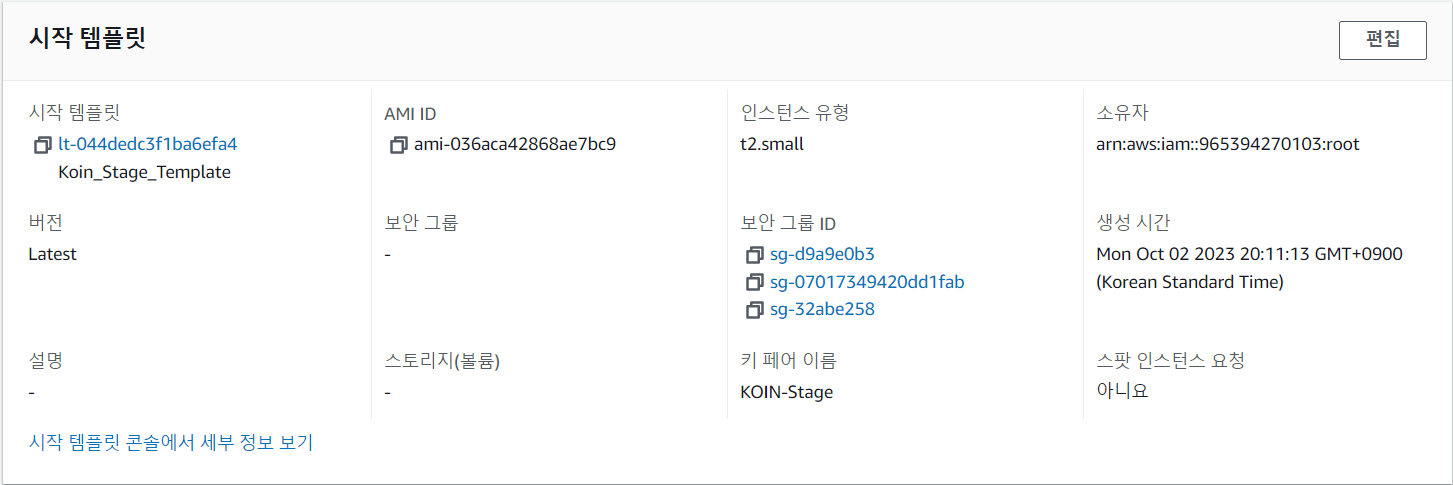
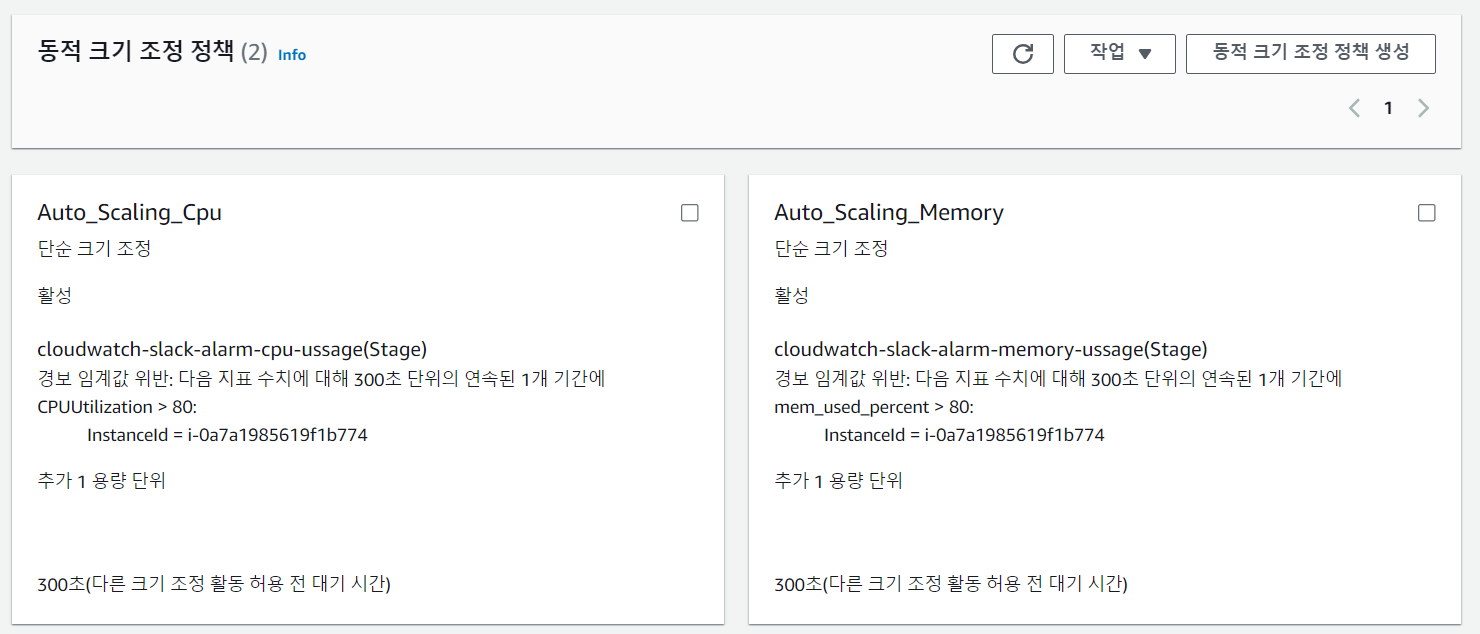
현재 Scaling정책은 평소 t2 small 서버를 유지하다, cloudwatch에서 경보조건이 발생하면 AMI를 이용한 Scaling을 통해 최대 2개의 t2 small서버를 유지하도록 설계되었다.

기존 Stage에서 사용하던 로드밸런서를 이용하고 있다.
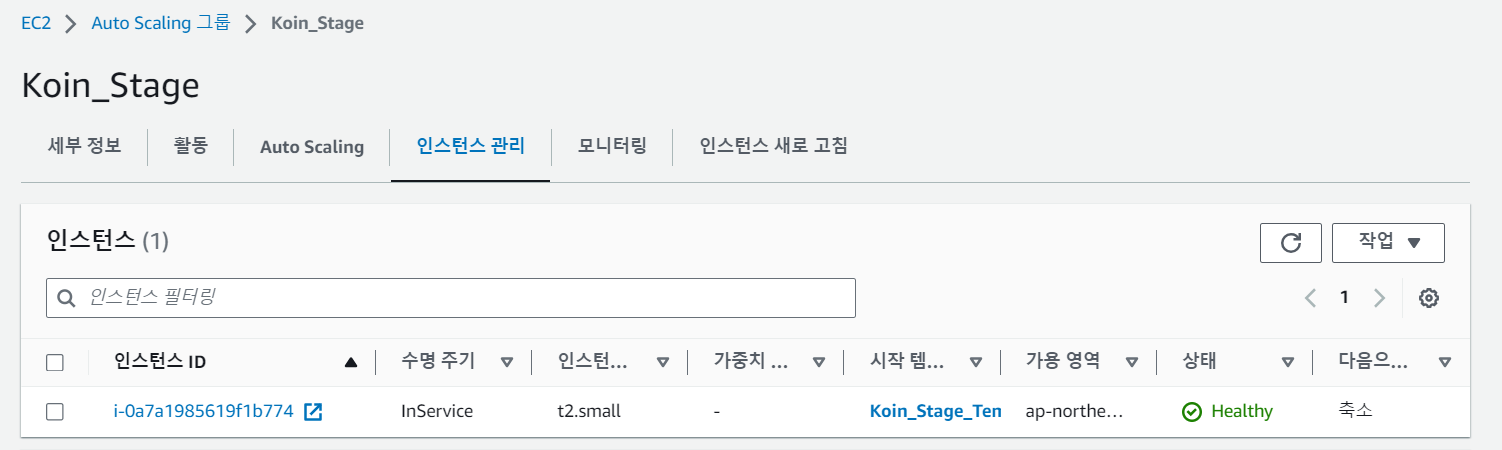
주의사항으로 기존에 사용하던 인스턴스를 오토스케일링 그룹에 추가시킬경우 기존인스턴스에 축소방지를 해야 한다.(아니면 인스턴스가 종료되는 큰 문제가 발생할 수 있다.)
현재 Stage에 Autoscaling이 적용되어 있다.
추후 블루/그린 배포등 다양한 기능으로도 확장 할 수 있다.
비용
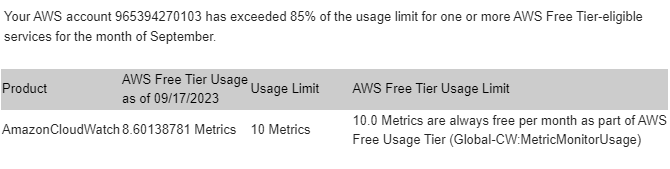
CloudWach비용을 참고하여 작업중 다음과 같은 free tier limit가 발생하여 aws영업지원에 문의하였다.
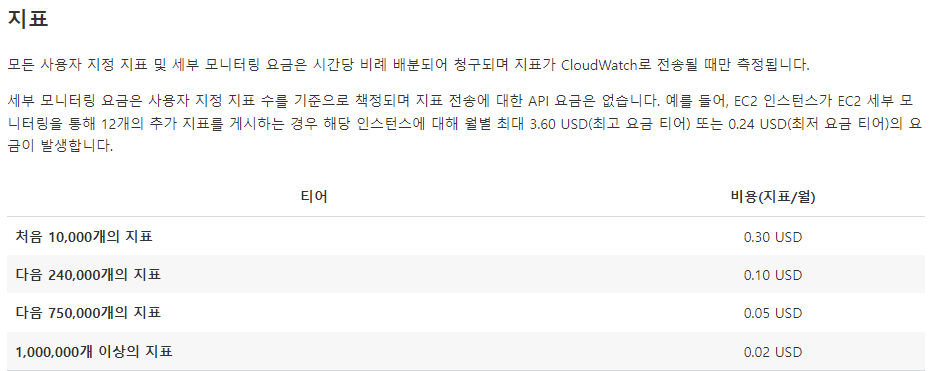
CloudWatchAgent 문서 확인 결과 세부지표로 인한 과금이 발생한 것을 확인하였다.
17일간 15.5Metrics를 사용한것으로 보아(1개의 인스턴스), free 10 Metrics, 10 Metrics(0.3X10),24 Metrics(0.1X 24),16 Metrics(0.05X16)으로 6.2USD 정도의 과금이 발생할 것으로 보인다.
문의 결과 cloudwatchagent에서 오직 Memory만 보내고 싶은 경우는 불가능하며, Basic이 가장 저렴한 방법이다.
후기
이후 AWS에 문의도 해본 결과 AMI를 Jenkins를 통해 꾸준히 업데이트를 한다면 AutoScaling이 가능하다.
하지만 현재 코인 서버는 EC2onDB로 인해 Auto Scaling이 비효율적이라 판단하였다. 왜냐하면 서버가 부하가 걸려 ScaleUP하게 되면 불필요한 데이터베이스도 생성이 되기 때문이다.
또한 스케일링에 대한 비용과 무중단 서비스에 대한 고민 결과 비융대비 효율적이지 않다는 생각에 안타깝지만 도입을 반려하게 되었다.
다만 서버 모니터링을 위해 Cloudwatch/CloudwatchAgent 는 사용하기로 하였다.
현재로선 서버의 상태를 모니터링후 문제가 생기면
를 바탕으로 빠르게 대응을 하는것이 최선이라고 생각한다.
참고자료
cloudwatchAgent:
https://blog.pium.life/server-monitoring/
cloudWatchAlarm:
cloudWatchAgent 작동중지:
https://www.petefreitag.com/item/868.cfm
https://sisylian.tistory.com/10
AutoScaling:
https://jaehyun8719.github.io/2020/02/20/aws/auto-scaling/
https://suyeon96.tistory.com/46

이걸 뜯어낸건 너무 아쉽구만, AWS ECS는 이번에 신규 기능으로 진짜 딸칵하면 auto scailing되는 듯