저장 프로시저란?
DB 내부에 저장된 일련의 SQL 명령문들을 하나의 함수처럼 실행하기 위한 쿼리의 집합
즉, DB에 대한 작업을 정리한 절차를 RDBMS(관계형 데이터 베이스 관리 시스템)에 저장한 쿼리 집합이다.
- SQL Server에서 제고오디는 프로그래밍 기능. 쿼리문의 집합
- 어떠한 동작을 일괄 처리하기 위한 용도로 사용
- 자주 사용되는 일반적인 쿼리를 모듈화시켜 필요할 때마다 호출
- 테이블처럼 각 데이터베이스 내부에 저장
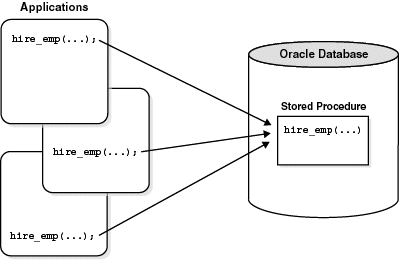
프로시저를 만들어두면, 애플리케이션에서 여러 상황에 따라 해당 쿼리문이 필요할 때 인자 값만 전달하여 쉽게 원하는 결과물을 받아낼 수 있다.
일반 쿼리문 VS 저장 프로시저
일반 쿼리문 작동 방식

일반적으로 쿼리문 한 줄을 실행하더라도 '파싱 -> 최적화 -> 컴파일 및 실행 계획 등록(실행 계획 결과를 메모리에 등록) -> 실행' 하는 과정의 많은 절차를 거친다.
최적화된 결과를 바탕으로 컴파일 및 실행 계획 등록 단계에서 해당 실행 계획 결과를 메모리(캐시)에 등록한다.
저장 프로시저
1. 저장 프로시저 정의 단계
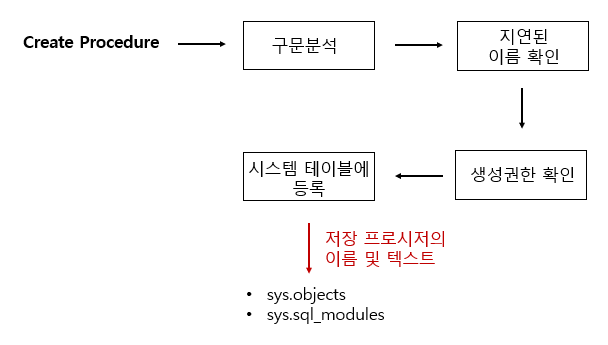
- 구문 분석 : 구문의 오류 파악
- 지연된 이름 확인 : 저장 프로시저를 정하는 시점에서 해당 개채(ex. 테이블)가 존재하지 않아도 상관없다. 프로시저 실행 당시에 테이블 존재 여부 확인(개채이름 확인)
- 생성권한 확인 : 현재 사용자가 저장 프로시저를 생성할 권한이 있는지 확인
- 시스템 테이블 등록 : 저장 프로시저의 이름 및 코드가 시스템 테이블에 등록
2. 처음으로 저장 프로시저를 실행
구문 분석 단계가 빠지는것만 빼면 일반적인 쿼리문 수행단계와 동일하다. 저장 프로시저 정의 단계의 지연된 이름 확인에서 미루어두었던 해당 개체 존재 유무를 개체 이름 확인을 통해 수행한다.
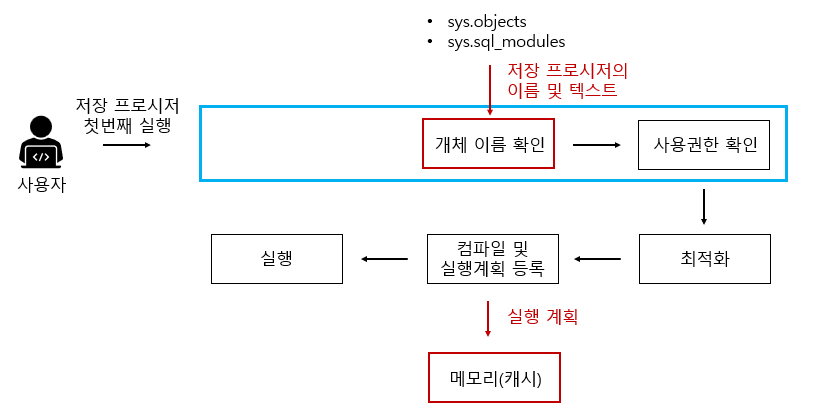
3. 이후의 저장 프로시저 실행
이후에 두 번째 실행부터는 메모리(캐시)에 있는 것을 그대로 가져와 재사용하게 되어 수행시간을 많이 단축한다.

사용방법
- 프로시저 생성 및 호출
CREATE OR REPLACE PROCEDURE 프로시저명(변수명1 IN 데이터타입, 변수명2 OUT 데이터타입) -- 인자 값은 필수 아님
IS
[
변수명1 데이터타입;
변수명2 데이터타입;
..
]
BEGIN
필요한 기능; -- 인자값 활용 가능
END;
EXEC 프로시저명; -- 호출- 예시 1(IN)
CREATE OR REPLACE PROCEDURE test( name IN VARCHAR2 )
IS
msg VARCHAR2(5) := '내 이름은';
BEGIN
dbms_output.put_line(msg||' '||name);
END;
EXEC test('jun');내 이름은 jun- 예시 2 (OUT)
CREATE OR REPLACE PROCEDURE test( name OUT VARCHAR2 )
IS
BEGIN
name := 'Jun'
END;
DECLARE
out_name VARCHAR2(100);
BEGIN
test(out_name);
dbms_output.put_line('내 이름은 '||out_name);
END;내 이름은 Jun프로시저 장점
-
최적화 & 캐시
프로시저의 최초 실행 시 최적화 상태로 컴파일이 되며, 그 이후 프로시저 캐시에 저장된다.
만약 해당 프로세스가 여러 번 사용될 때, 다시 컴파일 작업을 거치지 않고 캐시에서 가져오게 된다.
또한 여러개의 쿼리를 한번에 실행할 수 있다. -
유지 보수
작업이 변경될 때, 다른 작업은 건드리지 않고 프로시저 내부에서 수정만 하면 된다.
예를 들어 C#, Java등으로 만들어진 응용프로그램에서 직접 SQL문을 호출하지 않고 저장 프로시저의 이름을 호출하도록 설정하여 사용하는 경우가 많은데, 이때 개발자는 수정 요건이 발생할 때 코드 내 SQL문을 건드리는게 하니라 SP 파일만 수정하면 되기 때문에 유지 보수 측면에서 유리해진다. -
트래픽 감소
클라이언트가 직접 SQL문을 작성하지 않고, 프로시저명에 매개변수만 담아 전달하면 된다. 즉, SQL문이 서버에 이미 저장되어 있기 때문에 클라이언트와 서버 간 네트워크 상 트래픽이 감소된다. -
보안
프로시저 내에서 참조 중인 테이블의 접근을 막을 수 있다.
사용자별로 테이블에 권한을 주는게 아닌 저장 프로시저에만 접근 권한을 줌으로써 테이블의 모든 정보를 사용자에게 노출하지 않고 프로시저에서 선택한 정보만 사용자에게 보여줄 수 있다.
프로시저 단점
-
호환성
구문 규칙이 SQL/PSM 표준과의 호환성이 낮기 때문에 코드 자산으로써 재사용성이 나쁘다. -
성능
문자 또는 숫자 연산에서 프로그래밍 언어인 C나 Java보다 성능이 느리다. -
디버깅
에러가 발생했을 때, 어디서 잘못됐는지 디버깅하는 것이 힘들 수 있다. -
DB 확장 어려움
서비스 사용자가 많아져 서버의 수를 늘려야할 때, DB의 수를 늘리는 것이 더 어렵다. 또한, DB교체는 거의 불가능하다. -
데이터 분석의 어려움
- 개발된 프로시저가 여러 곳에서 사용될 경우 수정했을 때 영향의 분석이 어렵다( 별도의 Description 사용).
- 배포, 버전 관리등에 대한 이력 관리가 힘들다.
- APP에서 SP를 호출하여 사용하는 겨우 문제가 생겨도 해당 이슈에 대한 추적이 힘들다(별도의 에러 테이블 사용).
참조: https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Database/%EC%A0%80%EC%9E%A5%20%ED%94%84%EB%A1%9C%EC%8B%9C%EC%A0%80(Stored%20PROCEDURE).md, https://velog.io/@sweet_sumin/%EC%A0%80%EC%9E%A5-%ED%94%84%EB%A1%9C%EC%8B%9C%EC%A0%80-Stored-Procedure
