리액티브 시스템이란?
반응을 잘하는 시스템을 의미합니다.
리액티브 시스템을 이용하는 클라이언트의 요청에 반응을 잘하는 시스템.
리액티브 시스템 관점에서 반응은 스레드의 Non-Blocking과 관련있습니다.
리액티브 시스템은 클라이언트의 요청에 대한 응답 대기 시간을 최소화할 수 있도록 요청 스레드가 차단되지 않게 함으로써(Non-Blocking) 클라이언트에게 즉각적으로 반응하도록 구성된 시스템입니다.
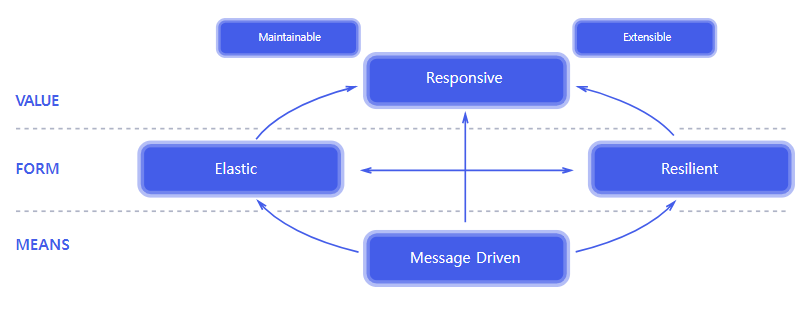
참고자료: https://www.reactivemanifesto.org/
위 그림은 리액티브 시스템의 설계 원칙을 그림으로 표현한 것입니다.
- MEANS : 리액티브 시스템에서 사용하는 커뮤니케이션 수단을 의미합니다.
- Message Driven : 리액티브 시스템에서는 메시지 기반 통신을 통해 여러 시스템 간에 느슨한 결합을 유지합니다.
- FORM : 메시지 기반 통신을 통해 리액티브 시스템이 어떤 특성을 가지는 구조로 형성되는지를 의미합니다.
- Elastic : 시스템으로 들어오는 요청량이 적거나 많거나에 상관없이 일정한 응답성을 유지하는 것을 의미합니다.
- Resillient : 시스템의 일부분에 장애가 발생하더라도 응답성을 유지하는 것을 의미합니다.
- VALUE : 리액티브 시스템의 핵심 가치가 무엇인지를 표현하는 영역입니다.
- Responsive : 리액티브 시스템은 클라이언트의 요청에 즉각적으로 응답할 수 있어야 합니다.
- Maintainable : 클라이언트의 요청에 대한 즉각적인 응답이 지속가능해야 합니다.
- Extensible : 클라이언트의 요청에 대한 처리량을 자동으로 확장하고 축소할 수 있어야 합니다.
리액티브 프로그래밍이란?
리액티브 시스템에서 사용되는 프로그래밍 모델을 의미합니다.
리액티브 시스템에서의 메시지 기반 통신은 Non-Blocking 통신과 유기적인 관계를 맺고 있으며, 리액티브 프로그래밍은 Non-Blocking 통신을 위한 프로그래밍 모델입니다.
In computing, reactive programming is a declarative programming paradigm concerned with data streams and the propagation of change. With this paradigm, it's possible to express static (e.g., arrays) or dynamic (e.g., event emitters) data streams with ease, and also communicate that an inferred dependency within the associated execution model exists, which facilitates the automatic propagation of the changed data flow.
위 설명은 위키피디아에 나와 있는 리액티브 프로그래밍에 대한 설명입니다.
-
declarative programming paradigm
- 리액티브 프로그래밍은 선언형 프로그래밍 방식을 사용하는 대표적인 프로그래밍 모델입니다.
명령형 프로그래밍과 선언형 프로그래밍의 차이점에 대해서는 뒤에서 설명하겠습니다.
- 리액티브 프로그래밍은 선언형 프로그래밍 방식을 사용하는 대표적인 프로그래밍 모델입니다.
-
data streams and the propagation of change
- data streams는 지속적으로 데이터가 입력으로 들어올 수 있음을 의미하며, 리액티브 프로그래밍에서는 데이터가 지속적으로 발생하는 것 자체를 데이터에 어떤 변경이 발생함을 의미합니다.
그리고 이 변경 자체를 이벤트로 간주하고, 이벤트가 발생할 때마다 데이터를 계속해서 전달합니다.
- data streams는 지속적으로 데이터가 입력으로 들어올 수 있음을 의미하며, 리액티브 프로그래밍에서는 데이터가 지속적으로 발생하는 것 자체를 데이터에 어떤 변경이 발생함을 의미합니다.
-
automatic propagation of the changed data flow
- 앞에서 설명한 data streams and the propagation of change와 같은 의미입니다. 지속적으로 발생하는 데이터를 하나의 데이터 플로우로 보고 데이터를 자동으로 전달합니다.
리액티브 스트림즈란?
리액티브 프로그래밍을 위한 표준 사양입니다.
Java에서는 어떤 기술의 표준 사양을 코드로 정의할 셩우 일반적으로 Java의 인터페이스로 정의합니다.
리액티브 스트림즈에서 사양으로 정의된 컴포넌트에 대해 설명하겠습니다.
리액티브 스트림즈 컴포넌트
Publisher
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}Publisher 인터페이스는 데이터 소스로부터 데이터를 내보내는(emit) 역할을 합니다.
Publisher 인터페이스는 위 코드와 같이 subscribe() 추상 메서드를 포함하고 있으며, subscribe()의 파라미터로 전달되는 Subscriber가 Publisher로부터 내보내진 데이터를 소비하는 역할을 합니다.
subscribe()는 메서드 이름에서도 알 수 있듯이 Publisher가 내보내는 데이터를 수신할지 여부를 결정하는 구독의 의미를 가지고 있으며, 일반적으로 subscribe()가 호출되지 않으면 Publisher가 데이터를 내보내는 프로세스는 시작되지 않습니다.
Subscriber
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}Subscriber 인터페이스는 Publisher로부터 내보내진 데이터를 소비하는 역할을 합니다.
Subscriber는 네 개의 추상 메서드를 포함하고 있으며, 각 메서드의 역할은 다음과 같습니다.
-
onSubscribe(Subscription s)
- 구독이 시작되는 시점에 호출되며, onSubscribe() 내에서 Publisher에게 요청할 데이터의 개수를 지정하거나 구독 해지 처리를 할 수 있습니다.
-
onNext(T t)
- Publisher가 데이터를 emit할 때 호출되며, emit 된 데이터를 전달받아서 소비할 수 있습니다.
-
onError(Throwable t)
- Publisher로부터 emit 된 데이터가 Subscriber에게 전달되는 과정에서 에러가 발생할 경우에 호출됩니다.
-
onComplete()
- Publisher가 데이터를 emit하는 과정이 종료될 경우 호출되며, 데이터의 emit이 정상적으로 완료된 후, 처리해야 될 작업이 있다면 onComplete() 내에서 수행할 수 있습니다.
Subscription
public interface Subscription {
public void request(long n);
public void cancel();
}Subscription 인터페이스는 Subscriber의 구독 자체를 표현한 인터페이스이며, 각 메서드의 역할은 다음과 같습니다.
-
request(long n)
- Publihser가 emit하는 데이터의 개수를 요청합니다.
-
cancel()
- 구독을 해지하는 역할을 합니다. 즉, 구독 해지가 발생하면 Publisher는 더 이상 데이터를 emit하지 않습니다.
Processor
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> {
}Processor 인터페이스는 Subscriber 인터페이스와 Publisher 인터페이스를 상속하고 있기 때문에 Publisher와 Subscriber의 역할을 동시에 할 수 있는 특징을 가지고 있으며, 별도로 구현해야 되는 추상 메서드는 없습니다.
리액티브 스트림즈 구현체
- Project Reactor
Project Reactor(줄여서 Reactor)는 리액티브 스트림즈를 구현한 대표적인 구현체로써 Spring과 궁합이 가장 잘 맞는 리액티브 스트림즈 구현체입니다.
Reactor는 Spring 5의 리액티브 스택에 포함되어 있으며 Sprig Reactive Application 구현에 있어 핵심적인 역할을 담당하고 있습니다.
- RxJava
RxJava는 .NET 기반의 리액티브 라이브러리를 넷플릭스에서 Java 언어로 포팅한 JVM 기반의 리액티브 확장 라이브러리입니다.
RxJava의 경우 2.0부터 리액티브 스트림즈 표준 사양을 준수하고 있으며, 이 전 버전의 컴포넌트와 함께 혼용되어 사용이 되고 있습니다.
- Java Flow API
Java 역시 Java 9부터 리액티브 스트림즈를 지원하고 있습니다.
그런데 Flow API는 리액티브 스트림즈를 구현한 구현체가 아니라 리액티브 스트림즈 표준 사양을 Java 안에 포함을 시킨 구조라고 볼 수 있습니다.
즉, 다양한 벤더들이 JDBC API를 구현한 드라이버를 제공할 수 있도록 SPI(Service Provider Interface) 역할을 하는 것처럼 Flow API 역시 리액티브 스트림즈 사양을 구현한 여러 구현체들에 대한 SPI 역할을 한다고 보면 될 것 같습니다.
- 기타 리액티브 확장(Reactive Extension)
RxJava의 Rx는 Reactive Extension의 줄임말입니다.
이 의미는 특정 언어에서 리액티브 스트림즈를 구현한 별도의 구현체가 존재한다는 의미이며, 실제로 다양한 프로그래밍 언어에서 리액티브 스트림즈를 구현한 리액티브 확장(Reactive Extension) 라이브러리를 제공하고 있습니다.
대표적인 리액티브 확장(Reactive Extension) 라이브러리로 앞에서 언급한 RxJava가 있으며, 이외에도 RxJS, RxAndroid, RxKotlin, RxPython, RxScala 등이 있습니다.
Project Reactor
Reactor는 리액티브 스트림즈 표준 사양을 구현한 구현체 중 하나입니다.
특징
-
리액티브 스트림즈를 구현한 리액티브 라이브러리입니다.
-
완전한 Non-Blocking 통신을 지원합니다.
-
Publisher 타입으로 Mono[0|1]와 Flux[N]이라는 두 가지 타입을 제공합니다.
- Mono[0|1]에서 0과 1의 의미는 0건 또는 1건의 데이터를 emit 할 수 있음을 의미합니다.
Flux[N]에서 N의 의미는 여러 건의 데이터를 emit할 수 있음을 의미합니다.
- Mono[0|1]에서 0과 1의 의미는 0건 또는 1건의 데이터를 emit 할 수 있음을 의미합니다.
-
서비스들 간의 통신이 잦은 MSA 기반 애플리케이션들은 요청 스레드가 차단되는 Blocking 통신을 사용하기에는 무리가 있습니다. 따라서 기본적으로 Non-Blocking 통신을 완벽하게 지원하는 Reactor는 MSA 구조에 적합한 라이브러리라고 볼 수 있습니다.
-
Backpressure 지원
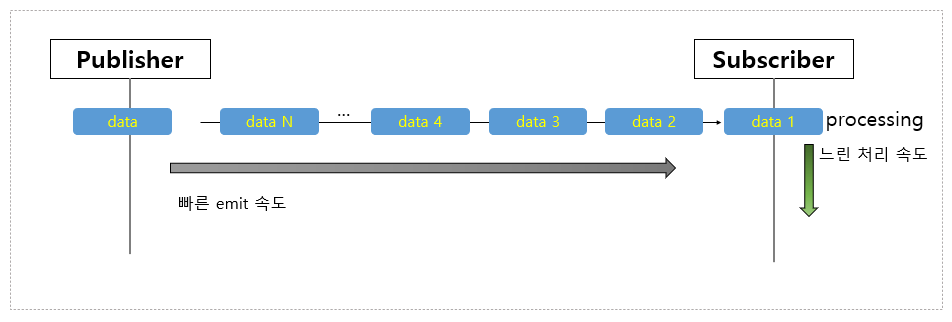
Backpressure가 적용되지 않은 Publisher & Subscriber 이미지입니다.
리액티브 프로그래밍에서는 끊임없이 들어오는 데이터를 적절하게 처리할 수 있어야 합니다.
위 이미지처럼 처리 속도가 느리면 처리되지않고 대기하는 데이터가 지속적으로 쌓이는 것을 방치하게 되면 오버플로우가 발생하게 되고 급기야 시스템이 다운될 수 있습니다.
Backpressure란 Subscriber의 처리 속도가 Publisher의 emit 속도를 따라가지 못할 때 적절하게 제어하는 전략을 의미합니다.
마블 다이어그램
구슬 모양의 동그라미는 하나의 데이터를 의마하며, 다이어그램 상에서 시간의 흐름에 따라 변화하는 데이터의 흐름을 표현합니다.
Mono의 마블 다이어그램
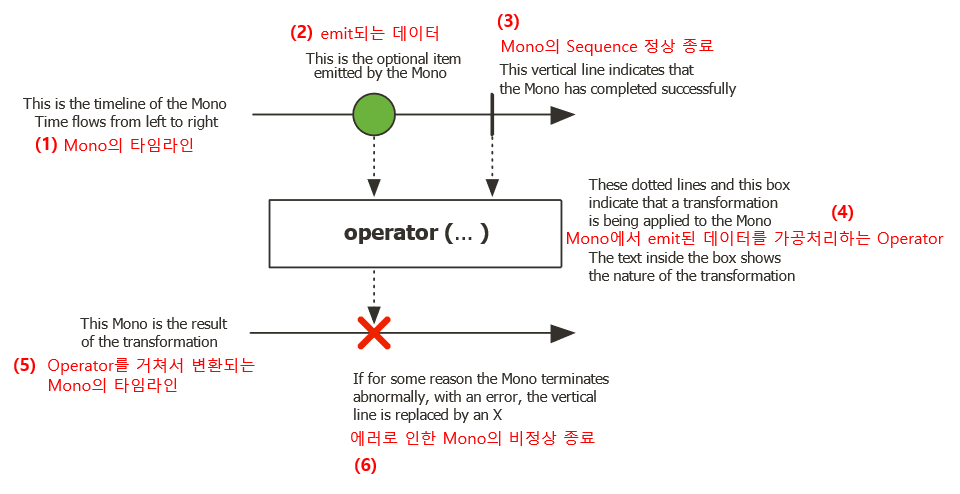
마블 다이어그램에는 아래위로 두 개의 타임 라인이 있는데 모두 데이터가 흘러가는 시간의 흐름을 표현하고 있습니다. 시간은 왼쪽에서 오른쪽으로 흘러가기 때문에 시간 상으로는 왼쪽이 빠른 시간입니다.
(1)은 원본 Mono(Original Mono)에서 Sequence가 시작되는 것을 타임라인으로 표현한 것입니다.
(2)는 Mono의 Sequence에서 데이터가 emit 되는 것을 표현하고 있습니다.
그림 상에서 구슬 모양의 데이터 하나가 emit되는 것을 확인할 수 있는데, 단순히 그냥 구슬 모양의 데이터 하나만 표시한 게 아니라 Mono는 0건 또는 1건의 데이터만 emit하는 Reactor 타입이기 때문에 마블 다이어그램에서 이를 표현하고 있는 것입니다.
(3)의 수직 막대 바는 Mono의 Sequence가 정상 종료됨을 의미합니다.
(4)는 Mono에서 지원하는 어떤 Operator에서 입력으로 들어오는 구슬 모양의 데이터를 가공 처리되는 것을 표현하고 있습니다.
(5)는 Operator에서 가공 처리된 데이터가 Downstream으로 전달될 때의 타임라인입니다. 시간의 흐름은 위쪽에 있는 타임라인과 마찬가지로 왼쪽이 빠른 시간입니다.
만약 Mono에서 emit 된 데이터가 처리되는 과정에 에러가 발생한다면 (6)과 같이 ‘X’로 표시합니다.
Flux의 마블 다이어그램
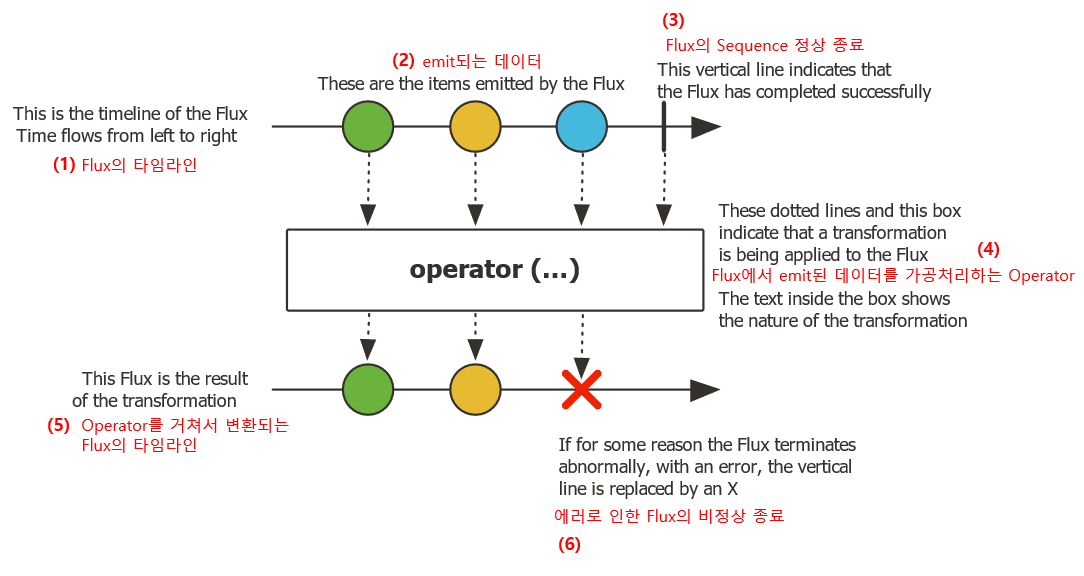
Mono가 0 또는 1개의 데이터만 emit하는 것과는 달리 Flux는 여러 개(0 … N)의 데이터를 emit하는 Reactor 타입임을 표현하는 것입니다.
스케줄러란
Reactor Sequence 상에서 처리되는 동작들을 하나 이상의 스레드에서 동작하도록 별도의 스레드를 제공해 준다.
Reactor의 Scheduler는 복잡한 멀티스레딩 프로세스를 단순하게 해 준다.
Scheduler 전용 Operator
적절한 상황에 맞는 스레드를 추가로 생성하는 Operator
import lombok.extern.slf4j.Slf4j;
import reactor.core.publisher.Flux;
/**
* Scheduler를 추가하지 않을 경우
*/
@Slf4j
public class SchedulersExample01 {
public static void main(String[] args) {
Flux
.range(1, 10)
.filter(n -> n % 2 == 0)
.map(n -> n * 2)
.subscribe(data -> log.info("# onNext: {}", data));
}
}실행 결과를 보면 로그에 [main]으로 표시되어 main 스레드에서 실행이 되었음을 의미합니다.
import lombok.extern.slf4j.Slf4j;
import reactor.core.publisher.Flux;
import reactor.core.scheduler.Schedulers;
/**
* subscribeOn() Operator를 이용해서 Scheduler를 추가할 경우
*/
@Slf4j
public class SchedulersExample02 {
public static void main(String[] args) throws InterruptedException {
Flux
.range(1, 10)
.doOnSubscribe(subscription -> log.info("# doOnSubscribe")) // (1)
.subscribeOn(Schedulers.boundedElastic()) // (2)
.filter(n -> n % 2 == 0)
.map(n -> n * 2)
.subscribe(data -> log.info("# onNext: {}", data));
Thread.sleep(100L);
}
}(2)와 같이 subscribeOn() Operator 내부에 Schedulers.boundedElastic() 같은 Scheduler를 지정하면 구독 직후에 실행되는 스레드가 main 스레드에서 Scheduler로 지정한 스레드로 바뀌게 됩니다.
이를 통해서 알 수 있는 사실은 subscribeOn()의 경우, 구독 직후 실행되는 Operator 체인의 실행 스레드를 Scheduler에서 지정한 스레드로 변경한다는 것입니다.
doOnSubscribe() Operator는 구독 발생 직후에 트리거 되는 Operator로써 구독 직후에 실행되는 스레드와 동일한 스레드에서 실행됩니다. 만약 구독 직후에 어떤 동작을 수행하고 싶다면 doOnSubscribe()에 로직을 작성하면 됩니다.
위 코드에서 publishOn()이라는 Operator를 추가해 보겠습니다.
@Slf4j
public class SchedulersExample03 {
public static void main(String[] args) throws InterruptedException {
Flux
.range(1, 10)
.subscribeOn(Schedulers.boundedElastic())
.doOnSubscribe(subscription -> log.info("# doOnSubscribe"))
.publishOn(Schedulers.parallel()) // (1)
.filter(n -> n % 2 == 0)
.doOnNext(data -> log.info("# filter doOnNext")) // (2)
.publishOn(Schedulers.parallel()) // (3)
.map(n -> n * 2)
.doOnNext(data -> log.info("# map doOnNext")) // (4)
.subscribe(data -> log.info("# onNext: {}", data));
Thread.sleep(100L);
}
}publishOn() 을 추가할 때마다 추가한 publishOn()을 기준으로 Downstream 쪽 스레드가 publishOn()에서 Scheduler로 지정한 스레드로 변경됩니다.
(2)와 (4)의 doOnNext()는 doOnNext() 바로 앞에 위치한 Operator가 실행될 떄, 트리거 되는 Operator입니다.
filter()와 map() Operator가 어느 스레드에서 실행이 되는지 확인하기 위한 용도로 사용하고 있습니다.
정리
subscribeOn()은 구독 시점 직후의 실행 흐름을 다른 스레드로 바꾸는 데 사용합니다.
구독 시점 직후 실행되는 작업으로 range() Operator처럼 원본 데이터를 생성하고, 생성한 데이터를 emit하는 작업이 구독 직후에 실행됩니다.
즉, subscribeOn()은 주로 데이터 소스에서 데이터를 emit하는 원본 Publisher의 실행 스레드를 지정하는 역할을 합니다.
publishOn()은 전달받은 데이터를 가공 처리하는 Operator 앞에 추가해서 실행 스레드를 별도로 추가하는 역할을 합니다.
주의할 것은 publishOn()은 Operator 앞에 여러 번 추가할 경우 별도의 스레드가 추가로 생성되지만 subscribeOn()은 여러 번 추가해도 하나의 스레드만 추가로 생성됩니다.
Reactor에서는 Scheduler를 통해 여러 가지 유형의 스레드를 지원합니다.
subscribeOn()에서는 주로 Schedulers.boundedElastic()을 사용하고, publishOn()에서는 주로 Schedulers.parallel()을 사용합니다.
